August 02, 2026

Hashtag Jakarta EE #344
by Ivar Grimstad at August 02, 2026 09:59 AM
Welcome to issue number three hundred and forty-four of Hashtag Jakarta EE!
This will be a rather short post since it is in the time of the year most people are on vacation or doing something else than reading blogs. This week, I have attended JCrete with lots of regulars and also made friends among the new faces. I will write a more detailed writeup from JCrete later.
The Starter for Jakarta EE has just released a new version with support for Jakarta EE 11. You can use the starter to quickly get started by generating a new Jakarta EE project. You can choose to create a plain project with no runtime configuration, or you can choose to get your project fully configured for one of the implementations of Jakarta EE 11. You can also get the Dockerfile generated for you. Please give it a try and tell us what you think.

AWS CDK Infrastructure as Business Components (BCE/ECB) with the /aws-cdk Skill
August 02, 2026 06:26 AM
The /aws-cdk skill generates and reviews Java AWS CDK v2 projects organized as BCE (Boundary-Control-Entity) business components. Infrastructure code follows the same structure as a business application instead of accumulating as a flat list of resources. It ships as an AIrails skill: /aws-cdk.
The main tenet is the separation of stacks from constructs. A stack decides which resources deploy together and lives in boundary. A construct defines how a capability is configured, is reusable across stacks, and lives in control as a stateless factory, preferably an interface with static methods. Immutable data that describes infrastructure without creating it, like build specs and typed value objects, lives in entity.
The remaining ideas follow from that split:
- Packages are business components named after the AWS capability they provision:
s3,cloudfront,cognito,route53,stepfunctions. A component spanning multiple services is named after its domain responsibility. - A single
CDKAppentry point loads configuration as typed Javarecords, applies tags, wires stacks in dependency order, and callsapp.synth(). Stacks never read CDK context or environment variables; they receive typed records. - Regions are pinned in a central
Stacksinterface exposingStackPropsconstants. Account and region are never inlined in stack classes. - Stacks stay independent. A producing stack passes resource interfaces like
IBucketorITableto consumers, never stack instances. - For IAM,
grant*methods on the target construct generate least-privilege policies. ExplicitPolicyStatements are the fallback. - Synthesis stays deterministic and side-effect free: no SDK calls, no timestamps, no randomness during construction. Tests assert on the synthesized CloudFormation template instead of snapshots.
The skill composes with /bce and /java-conventions and ships with a domain-neutral project blueprint. It is also compatible with /sbce, the spec-driven BCE workflow: a capability spec describes one business component, and the code is iterated until it matches the spec. A compilable starter is available at AdamBien/aws-cdk-plain, and constructions.cloud collects example constructs and CDK applications.
July 30, 2026
How to Name Business Components (BC): The Essence Method
July 30, 2026 09:52 AM
A business component is a package named after a single responsibility, and the structure of a system is the sum of these components. The hard part is finding the names. Here is the simplest approach I know, three steps.
- Say it. Describe what the system does in one sentence, in one breath.
- Name it. Underline the essential verbs and nouns. Those are your component candidates, and verbs become nouns.
- Test it. Drop every name that would fit another project. A name that transplants into any system says nothing about this one.
The method reverse-engineers reality. Take zb, a zero dependency builder:
"It discovers the Java sources, compiles them, packs an executable JAR, and runs the test hook after the build."
Verbs become nouns: discovers becomes discovery, compiles becomes compiler, packs becomes packer, and hook is already a noun. Open zb and you find exactly those packages: discovery, compiler, packer, hook. That sentence took about ten iterations. packer started as "jar creator", discovery started as "source", and hook did not exist yet.
An online shop: "customers browse the catalog, put products into a cart, place orders, and pay." That gives catalog, cart, orders, payments. Browse collapses into catalog, products are entities inside it. Customers is borderline: a component only when the system manages them, otherwise an entity inside orders.
Say it. Name it. Test it.
Part of the free Screaming Architecture with BCE course.
July 26, 2026
Hashtag Jakarta EE #343
by Ivar Grimstad at July 26, 2026 09:59 AM
Welcome to issue number three hundred and forty-three of Hashtag Jakarta EE!
I have been home a week since JConf Dominicana 2026, and today I am setting course for Crete to be a part of JCrete 2026. This unconference in the Mediterranean in the middle of summer has become a tradition for me since I first attended more than ten years ago.
Even if the summer holidays are upon us, the Jakarta EE Platform project continues to meet every Tuesday in the Platform call. There is a bit of progress in the Jakarta RESTful Web Services project now, so it seems like they will be able to publish a milestone soon with the changes needed to deprecate and eventually remove the custom component model in favor of CDI. A final release will be available for Jakarta EE 12.
The limits that were recently introcuced for publication to Maven Central is stirring up the open source community. There are discussions among the Java Champions for how to cope with this. A suggestion that a vendor-neutral model like the one for Open VSX may be a possible way forward should it continue to be a problem. Good to know is that projects hosted at Eclipse Foundation currently have no limitations for publishing artifacts to Maven Central.
A little over a week ago, the Java Documentary by CultRepo titled The Java Story was released. You should really watch it to get a glimpse of this amazing community and ecosystem around Java. I am also pleased to be featured in the documentary. Not a big part, but I am there representing the community, Jakarta EE, Eclipse Foundation, Enterprise Java, and open source in general.

Scraping in Java is easy
July 26, 2026 12:00 AM
July 21, 2026
July 15, 2026

Resumable file uploads with plain Jakarta EE and TUS protocol
by Rustam Mehmandarov at July 15, 2026 05:00 AM
In my previous post I covered binary uploads to REST endpoints – multipart, Quarkus @RestForm, and raw application/octet-stream. All three share one weakness: if the connection drops at 95%, you have to start over. This post adds resumability using the TUS protocol, implemented with nothing but jakarta.ws.rs.
Introduction
A plain HTTP upload is all-or-nothing. If anything interrupts the stream, the whole thing is gone. For a 2 MB profile picture that’s a shrug and a retry. For a 4 GB video over a hotel network or a spotty mobile connection, every retry starts from byte zero. The flakier the connection, the less likely you are to ever reach the end.
TUS is an open protocol that fixes this. Instead of one big request, the upload becomes a series of small ones, and the server keeps track of how many bytes have arrived. When the connection dies, the client asks “how far did we get?” and continues from there. Vimeo, Cloudflare, and Supabase all use it for their upload APIs.
The core protocol is small enough to implement with plain Jakarta REST annotations and nothing else. Let’s do that. But first, a few words on how TUS works.
The TUS protocol in a nutshell
The whole flow is just three HTTP requests and a handful of headers:
POST /files– creates a new upload. The client declares the total size with anUpload-Lengthheader; the server responds with201 Createdand aLocationheader pointing at the new upload resource.HEAD /files/{id}– asks where to resume. The server answers with anUpload-Offsetheader: the number of bytes it has safely received so far.PATCH /files/{id}– appends bytes at that offset, withContent-Type: application/offset+octet-stream. The server responds with the newUpload-Offset.
That’s it. Upload chunks with PATCH until the offset equals the length; if anything breaks, do a HEAD and continue from the offset it returns.
Oh, and one more rule: every request and response carries a Tus-Resumable: 1.0.0 header, so both sides know which protocol version they’re speaking.
Everything else is layered on top as optional extensions: cancelling an upload with DELETE (termination), checksums, expiration. Strictly speaking, even the POST above belongs to the creation extension – the core spec only covers resuming with HEAD and PATCH – but in practice every client and server implements it.
Why not a library?
There is a server-side library – tus-java-server – and since version 1.0.0-3.0 it targets jakarta.servlet, so it drops into Jakarta EE 10+ runtimes without tricks. It’s a fine choice if you want the full protocol with extensions. But it’s servlet-based, not JAX-RS – you wire it into a servlet or a controller and hand it the raw request. Since the core protocol fits in three resource methods, and we would like to understand how it all works, implementing it natively in Jakarta REST is barely more work. That’s what we’ll do here.
Implementing it with pure Jakarta REST
The implementation below uses nothing but jakarta.ws.rs, so it runs unchanged on either Helidon, Open Liberty, Payara, or Quarkus. As with the previous posts, the code lives in my API Guide for Java repository – see TusResource.java in the upload/tus package, with ready-made requests in http/tus.http. (In the repo the endpoints sit under the application’s /api prefix, so it’s /api/tus there.)
@Path("/tus")
public class TusResource {
private static final String TUS_VERSION = "1.0.0";
private static final java.nio.file.Path STORAGE_DIR =
java.nio.file.Path.of(System.getProperty("java.io.tmpdir"), "tus-uploads");
// upload id -> declared total length
private static final Map<String, Long> UPLOAD_LENGTHS = new ConcurrentHashMap<>();
@Context
UriInfo uriInfo;
// Capability discovery – what the server supports
@OPTIONS
public Response options() {
return Response.noContent()
.header("Tus-Resumable", TUS_VERSION)
.header("Tus-Version", TUS_VERSION)
.header("Tus-Extension", "creation")
.build();
}
// 1. Create the upload – returns the URL the client will PATCH to
@POST
public Response create(@HeaderParam("Upload-Length") Long uploadLength) throws IOException {
if (uploadLength == null || uploadLength < 0) {
return Response.status(Response.Status.BAD_REQUEST)
.header("Tus-Resumable", TUS_VERSION)
.build();
}
String id = UUID.randomUUID().toString();
Files.createDirectories(STORAGE_DIR);
Files.createFile(STORAGE_DIR.resolve(id));
UPLOAD_LENGTHS.put(id, uploadLength);
URI location = uriInfo.getAbsolutePathBuilder().path(id).build();
return Response.created(location)
.header("Tus-Resumable", TUS_VERSION)
.build();
}
// 2. Ask where to resume from
@HEAD
@Path("/{id}")
public Response offset(@PathParam("id") String id) throws IOException {
Long length = UPLOAD_LENGTHS.get(id);
if (length == null) {
return Response.status(Response.Status.NOT_FOUND)
.header("Tus-Resumable", TUS_VERSION)
.build();
}
long offset = Files.size(STORAGE_DIR.resolve(id));
return Response.noContent()
.header("Tus-Resumable", TUS_VERSION)
.header("Upload-Offset", offset)
.header("Upload-Length", length)
.header("Cache-Control", "no-store")
.build();
}
// 3. Append a chunk at the given offset
@PATCH
@Path("/{id}")
@Consumes("application/offset+octet-stream")
public Response append(@PathParam("id") String id,
@HeaderParam("Upload-Offset") Long uploadOffset,
InputStream body) throws IOException {
Long length = UPLOAD_LENGTHS.get(id);
if (length == null) {
return Response.status(Response.Status.NOT_FOUND)
.header("Tus-Resumable", TUS_VERSION)
.build();
}
java.nio.file.Path file = STORAGE_DIR.resolve(id);
long currentOffset = Files.size(file);
// The client's idea of the offset must match ours – otherwise 409
if (uploadOffset == null || uploadOffset != currentOffset) {
return Response.status(Response.Status.CONFLICT)
.header("Tus-Resumable", TUS_VERSION)
.header("Upload-Offset", currentOffset)
.build();
}
long newOffset;
try (OutputStream out = Files.newOutputStream(file, StandardOpenOption.APPEND)) {
body.transferTo(out);
newOffset = Files.size(file);
}
return Response.noContent()
.header("Tus-Resumable", TUS_VERSION)
.header("Upload-Offset", newOffset)
.build();
}
}
A few things worth pointing out:
@PATCHand@HEADare standardjakarta.ws.rsannotations – no vendor extras, which is what keeps this portable.- The body is a plain
InputStream.transferToplusStandardOpenOption.APPENDdo the heavy lifting: each chunk is streamed straight onto the end of the file, never buffered in memory. - The offset check is the heart of the protocol. The file on disk is the single source of truth. If the client’s
Upload-Offsetdoesn’t matchFiles.size(file), the server answers409 Conflictwith the correct offset, and the client retries from there. A half-received chunk is harmless: whatever made it to disk counts, the rest is re-sent. Tus-Resumable: 1.0.0goes on every response – including the error ones.- The in-memory map is demo-only. A restart wipes it, orphaning the files on disk. In production, persist the upload metadata – more on that below.
Testing it with curl
For the sake of the experiment, let’s split a 100 MB file into two 50 MB chunks and pretend the connection died in between:
# 1. Create a 100 MB upload
curl -si -X POST http://localhost:8080/tus \
-H "Tus-Resumable: 1.0.0" \
-H "Upload-Length: 104857600"
# -> 201 Created, Location: http://localhost:8080/tus/{id}
# 2. Upload the first chunk (and pretend the connection died after it)
curl -si -X PATCH http://localhost:8080/tus/{id} \
-H "Tus-Resumable: 1.0.0" \
-H "Upload-Offset: 0" \
-H "Content-Type: application/offset+octet-stream" \
--data-binary @chunk-1.bin
# -> 204 No Content, Upload-Offset: 52428800
# 3. Come back later – ask the server where we left off
curl -sI http://localhost:8080/tus/{id} \
-H "Tus-Resumable: 1.0.0"
# -> Upload-Offset: 52428800
# 4. Resume from that offset
curl -si -X PATCH http://localhost:8080/tus/{id} \
-H "Tus-Resumable: 1.0.0" \
-H "Upload-Offset: 52428800" \
-H "Content-Type: application/offset+octet-stream" \
--data-binary @chunk-2.bin
# -> 204 No Content, Upload-Offset: 104857600 – done!
Note: In real life you don’t split files by hand. TUS clients – tus-js-client for the browser, tus-java-client for the JVM – handle chunking, retries, and the HEAD-on-reconnect automatically. The curl session above is just the protocol laid bare.
A simple frontend
curl is fine for testing, but the whole point of TUS is surviving flaky browser connections. So let’s wire up tus-js-client. A single HTML file, no build step. Below is a simplified version – the full demo with styling and a few more niceties lives in the repo as snippets/tus-upload-demo.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Resumable upload demo</title>
<script src="https://cdn.jsdelivr.net/npm/tus-js-client@4/dist/tus.min.js"></script>
</head>
<body>
<input type="file" id="file">
<button id="toggle" disabled>Pause</button>
<progress id="progress" value="0" max="100"></progress>
<span id="status"></span>
<script>
let upload = null;
let paused = false;
const progress = document.getElementById("progress");
const status = document.getElementById("status");
const toggle = document.getElementById("toggle");
document.getElementById("file").addEventListener("change", (e) => {
const file = e.target.files[0];
if (!file) return;
upload = new tus.Upload(file, {
endpoint: "http://localhost:8080/tus",
chunkSize: 5 * 1024 * 1024, // 5 MB per PATCH
retryDelays: [0, 1000, 3000, 5000], // auto-retry on failure
metadata: { filename: file.name, filetype: file.type },
onProgress: (sent, total) => {
progress.value = (sent / total) * 100;
status.textContent = `${(sent / 1048576).toFixed(1)} / ${(total / 1048576).toFixed(1)} MB`;
},
onSuccess: () => { status.textContent = "Done: " + upload.url; },
onError: (err) => { status.textContent = "Error: " + err; }
});
// Resume a previous attempt of the same file, if one exists
upload.findPreviousUploads().then((previous) => {
if (previous.length > 0) upload.resumeFromPreviousUpload(previous[0]);
upload.start();
toggle.disabled = false;
});
});
toggle.addEventListener("click", () => {
paused = !paused;
paused ? upload.abort() : upload.start(); // abort() pauses, start() resumes
toggle.textContent = paused ? "Resume" : "Pause";
});
</script>
</body>
</html>
Here is what the full demo from the repo looks like in the browser:

A few things worth pointing out here:
findPreviousUploads()survives page reloads. tus-js-client remembers upload URLs inlocalStorage, keyed by file fingerprint. Reload the page, pick the same file, and the upload resumes instead of restarting.abort()/start()is pause/resume.start()does aHEADto get the current offset andPATCHes onward – the curl session from the previous section, automated.- The
metadataoption sends anUpload-Metadataheader (key/value pairs with base64-encoded values) on thePOST. Our minimal server ignores it – parse it increate()if you want to keep the original filename. - Don’t forget CORS. If the page and the API live on different origins, the TUS headers must be explicitly allowed and exposed. The easiest portable way is a
ContainerResponseFilter:
@Provider
public class TusCorsFilter implements ContainerResponseFilter {
@Override
public void filter(ContainerRequestContext request, ContainerResponseContext response) {
// Only for the TUS endpoints – don't leak CORS headers elsewhere
if (!request.getUriInfo().getPath().startsWith("tus")) {
return;
}
response.getHeaders().add("Access-Control-Allow-Origin", "*"); // narrow this in production
response.getHeaders().add("Access-Control-Allow-Methods", "POST, HEAD, PATCH, OPTIONS");
response.getHeaders().add("Access-Control-Allow-Headers",
"Tus-Resumable, Upload-Length, Upload-Offset, Upload-Metadata, Content-Type");
response.getHeaders().add("Access-Control-Expose-Headers",
"Tus-Resumable, Upload-Offset, Location");
}
}
Without the Expose-Headers part, the browser hides Location and Upload-Offset from JavaScript, and tus-js-client can’t resume – a classic “works in curl, fails in the browser” moment.
Production considerations
The resource above shows the protocol, not a production service. Before shipping something like it:
- Persist the upload metadata. The
ConcurrentHashMapdies with the JVM. Store the declared length (and anything fromUpload-Metadata) in a database or a sidecar file next to the partial upload, so uploads survive restarts. - Expire abandoned uploads. Partial files accumulate. The expiration extension adds an
Upload-Expiresheader; even without it, a scheduled job that deletes old partials is a must. - Verify integrity. The checksum extension lets the client send an
Upload-Checksumheader perPATCH, and the server verify before appending. - Lock concurrent PATCHes. Two simultaneous
PATCHrequests to the same upload will interleave appends and corrupt the file. The offset check catches most of it (the second request gets a 409), but a per-upload lock closes the race completely. - Cap the size. Same refrain as in the previous post: an unbounded upload endpoint is a denial-of-service waiting to happen. Validate
Upload-LengthonPOST, and don’t accept more bytes than were declared onPATCH.
Summary
✅ Pros:
- Survives failure. Connection drops, page reloads, and pause/resume all work – uploads continue instead of restarting.
- Portable. Pure
jakarta.ws.rs; the same class runs on Helidon, Open Liberty, Payara, and Quarkus. - An open, proven protocol. Mature clients exist for browser, JVM, iOS, and Android.
❌ Cons:
- More moving parts than a plain POST. Upload state, partial files, cleanup jobs, locking.
- No JAX-RS library. The existing Java server library is servlet-based; for a pure Jakarta REST setup you implement the core yourself (as here).
- Overkill for small files. A few megabytes on stable networks? A plain multipart POST from the previous post is good enough.
| Approach | Resumable? | Complexity | Reach for it when… |
|---|---|---|---|
| Plain upload (previous post) | ❌ No | Low | Small files, stable networks. |
| TUS (this post) | ✅ Yes | Medium | Large files, mobile/flaky networks, pause/resume UX. |
Conclusion
The TUS protocol is small: POST to create, HEAD to ask where you are, PATCH to continue, and one header on everything. The server side fits in three methods of plain Jakarta REST, with the file on disk as the single source of truth for progress. On the client side, tus-js-client adds chunking, retries, and resume-after-reload for free.
The trade-off: you take on upload state, cleanup, and locking in exchange for uploads that survive the real world. For large files on imperfect networks, that’s a good deal.
What’s Next?
This post continues the upload thread from binary file uploads to REST endpoints. The same API Guide for Java repo also covers OpenAPI docs, error handling with RFC 9457, security, pagination, and API versioning. Some of those topics I have blogged about already; others might make it into future posts here.
Happy upload resuming! ⏯️ 💾
July 08, 2026
Binary file uploads to REST endpoints using Jakarta EE or Quarkus
by Rustam Mehmandarov at July 08, 2026 05:00 PM
A while back I wrote about endpoints that send back a byte[] – images and PDFs. This post does the reverse: endpoints that receive binary data. We’ll look at the three ways this usually happens – a file as one part of a multipart form, the same thing using the Quarkus way, and a single binary body with no multipart wrapper at all. As always, code, the official docs, and the trade-offs for each.
Introduction
To return a file from a REST endpoint to a user (or a system) you need to set a MIME type, hand back a byte[], and you’re done. Uploading a binary to a server, on the other hand, is where things get a little more complex. Mostly because there is more than one way a client might want to send it.
Two situations come up again and again:
- A file plus some metadata – e.g. a profile picture together with a
userId, or a document with atitleand adescription. This is the classicmultipart/form-datarequest: several named parts, one (or more) of which happens to be binary. - Just the bytes – the client
PUTs a raw image or a PDF and nothing else. No form, no metadata, the body is the file. This is a plainapplication/octet-stream(or a specific type likeimage/png) request.
We’ll cover both. For the multipart case there are two routes worth knowing: the standard Jakarta REST 3.1 API that runs anywhere, and the Quarkus-specific one that is more “ergonomic”, if you’ve already committed to Quarkus.
A little bit of history
For years, multipart handling in JAX-RS was a gap in the standard. Everyone reached for a vendor extension – RESTEasy’s @MultipartForm, Jersey’s FormDataMultiPart, Apache CXF’s attachments – and the code you wrote was tied to whichever runtime you happened to be on. Portable multipart code simply wasn’t a thing.
That changed with Jakarta REST 3.1, which added the EntityPart API – a standard, vendor-neutral way to read (and build) the parts of a multipart message. If portability across Jakarta runtimes matters to you – in the same way as my RFC 9457 error handling and Jakarta Expression Language posts – the next section is for you.
Note: If you’ve used
@MultipartFormon older RESTEasy,EntityPartis the standardised successor to that idea.
I’ve added an upload package to my API Guide for Java repository. UploadResource.java holds the two portable endpoints (the standard EntityPart multipart one and the raw octet-stream one) – pure jakarta.ws.rs, so they compile and run on every runtime the repo targets. The Quarkus @RestForm variant lives as a reference snippet at QuarkusUploadResource.java (kept out of the main build because it only compiles on Quarkus). Ready-made requests are in http/uploads.http. Each section below shows how to run it with curl.
1. The standard way: Jakarta REST EntityPart
Here is an endpoint that accepts a multipart form with two parts: a file (the binary) and a description (plain text). It uses nothing but jakarta.ws.rs, so it runs on Helidon, Open Liberty, Payara, Jersey, and Quarkus alike.
@Path("/uploads")
public class UploadResource {
@POST
@Path("/multipart")
@Consumes(MediaType.MULTIPART_FORM_DATA)
@Produces(MediaType.APPLICATION_JSON)
public Response upload(List<EntityPart> parts) throws IOException {
String description = null;
String fileName = null;
long bytesReceived = 0;
for (EntityPart part : parts) {
switch (part.getName()) {
case "description" ->
description = part.getContent(String.class);
case "file" -> {
fileName = part.getFileName().orElse("unnamed");
try (InputStream in = part.getContent()) {
bytesReceived = in.transferTo(OutputStream.nullOutputStream());
// in real code: stream to storage, scan, resize, etc.
}
}
default -> { /* ignore unknown parts */ }
}
}
var summary = Map.of(
"fileName", fileName == null ? "unnamed" : fileName,
"bytes", bytesReceived,
"description", description == null ? "" : description);
return Response.ok(summary).build();
}
}
A few things worth pointing out:
- The method parameter is a
List<EntityPart>. The runtime parses the multipart body and hands you the parts; you decide what to do with each by itsgetName(). part.getContent(String.class)reads a text part as aString. For the binary part,part.getContent()gives you anInputStream– so you can stream straight to disk or object storage without buffering the whole file in memory. That last point matters once files get large.part.getFileName()returns anOptional<String>– the original filename from theContent-Dispositionheader, if the client sent one.
How to call it
curl -X POST http://localhost:8080/api/uploads/multipart \
-F "description=Conference floor plan" \
-F "file=@floorplan.pdf;type=application/pdf"
Here is what that curl command actually puts on the wire – a multipart/form-data body where each -F flag becomes its own part, separated by a boundary string, each with its own headers and content (the binary PDF bytes replaced with a placeholder here):
POST http://localhost:8080/api/uploads/multipart
Content-Type: multipart/form-data; boundary=----boundary
------boundary
Content-Disposition: form-data; name="description"
Conference floor plan
------boundary
Content-Disposition: form-data; name="file"; filename="floorplan.pdf"
Content-Type: application/pdf
[binary content of floorplan.pdf]
------boundary--
This is exactly the structure the List<EntityPart> parameter receives on the server side – one EntityPart per boundary-delimited section, with getName() returning description and file respectively.
Note: The
boundarystring is chosen by the client, and can be almost anything – RFC 2046 allows up to 70 characters from a restricted set, with one hard rule: it must never appear inside the parts it separates. That’s whycurlgenerates a long random one (something like------------------------d74496d66958873e) for every request. The----boundaryused here is just a simplified placeholder to keep the examples readable.
✅ Pros:
- Portable. Pure
jakarta.ws.rs; the same code runs on every Jakarta REST 3.1+ runtime. - Streams by default.
getContent()asInputStreammeans no need to hold the whole upload in memory. - Metadata and file in one request. Text parts and binary parts sit side by side.
❌ Cons:
- A bit more ceremony – you loop over parts and dispatch on names yourself.
- Requires Jakarta REST 3.1+ (Jakarta EE 10 and later). Older runtimes don’t have
EntityPart. (Which is not really a con.)
However: The extra few lines buy you portability. If “runs on every Jakarta runtime” is on your list, this is the price, and it’s a small one.
2. The Quarkus way: @RestForm and FileUpload
If you’re on Quarkus, RESTEasy Reactive gives you a more declarative style. You bind each part directly to a parameter with @RestForm, and binary parts map to a FileUpload (or a java.nio.file.Path, or a java.io.File):
@Path("/uploads")
public class QuarkusUploadResource {
@POST
@Path("/quarkus")
@Consumes(MediaType.MULTIPART_FORM_DATA)
@Produces(MediaType.APPLICATION_JSON)
public Map<String, Object> upload(
@RestForm("description") String description,
@RestForm("file") FileUpload file) {
// Note: The upload is already on disk as a temp file. We only return
// metadata here, but file.uploadedFile() gives you its Path when
// you need the content, e.g.:
// Files.move(file.uploadedFile(), Path.of("/storage", file.fileName()));
return Map.of(
"fileName", file.fileName() == null ? "unnamed" : file.fileName(),
"size", file.size(),
"contentType", file.contentType() == null ? "application/octet-stream" : file.contentType(),
"description", description == null ? "" : description);
}
}
This is noticeably tidier than the EntityPart loop – the framework does the dispatching for you, and FileUpload exposes fileName(), size(), contentType(), and a uploadedFile() Path pointing at a temp file Quarkus has already streamed to disk. Move or copy that file if you want to keep it – the temp file is cleaned up when the request ends. The Quarkus REST guide covers this and the multipart options in detail.
If you prefer a single object over several parameters, Quarkus also supports a class annotated with the parts as fields and bound with @BeanParam – handy when there are many fields.
How to call it
Note: in the demo repo this endpoint lives as a snippet and runs only when you build with the Quarkus profile and move it onto the classpath – the portable EntityPart endpoints above are the ones that work out of the box on every runtime.
curl -X POST http://localhost:8080/api/uploads/quarkus \
-F "description=Speaker headshot" \
-F "file=@headshot.png;type=image/png"
The request on the wire has the same multipart shape as in the EntityPart section – the only thing that changes is how the server side consumes it:
POST http://localhost:8080/api/uploads/quarkus
Content-Type: multipart/form-data; boundary=----boundary
------boundary
Content-Disposition: form-data; name="description"
Speaker headshot
------boundary
Content-Disposition: form-data; name="file"; filename="headshot.png"
Content-Type: image/png
[binary content of headshot.png]
------boundary--
✅ Pros:
- Less boilerplate. Each part is just a parameter; no manual loop.
- Files land on disk for you.
FileUpload.uploadedFile()is a ready-to-use tempPath. - Plays nicely with the rest of the Quarkus stack (validation, etc.).
❌ Cons:
- Quarkus-specific.
@RestFormandFileUploadare not portable – move to Helidon or Open Liberty and this code doesn’t come with you. - Temp-file handling has its own knobs (location, max size) you may need to tune.
Observation: This is the same trade-off as everywhere in this series – the vendor API is more pleasant, the standard API is more portable. Pick based on whether you ever expect to change runtimes.
3. Payload only: A single binary body
Sometimes there’s no form and no metadata – the client just sends the file as the entire request body. No multipart, no boundaries, the body is the bytes. This is the right shape for “upload this one image” style endpoints, and it’s the simplest of the three.
You consume application/octet-stream (or a concrete type) and take the body as an InputStream so you can stream it:
@POST
@Path("/raw")
@Consumes(MediaType.APPLICATION_OCTET_STREAM)
@Produces(MediaType.APPLICATION_JSON)
public Response uploadRaw(
InputStream body,
@HeaderParam("Content-Type") String contentType,
@HeaderParam("X-File-Name") String fileName) throws IOException {
long bytes = body.transferTo(OutputStream.nullOutputStream());
// in real code: stream to storage instead of counting
var summary = Map.of(
"fileName", fileName == null ? "unnamed" : fileName,
"contentType", contentType == null ? "application/octet-stream" : contentType,
"bytes", bytes);
return Response.ok(summary).build();
}
Since there’s no Content-Disposition part to carry the filename, the usual trick is to pass that kind of metadata in headers (X-File-Name above) or in the URL. The body parameter as InputStream keeps it streaming; you could also declare it as byte[] if the payload is genuinely small and you’re fine buffering it.
This part is pure jakarta.ws.rs too, so it’s portable across runtimes.
How to call it
curl -X POST http://localhost:8080/api/uploads/raw \
-H "Content-Type: image/png" \
-H "X-File-Name: headshot.png" \
--data-binary "@headshot.png"
And on the wire – notice how much simpler it is than multipart: no boundaries, no parts, just headers followed by the raw bytes as the entire body:
POST http://localhost:8080/api/uploads/raw
Content-Type: image/png
X-File-Name: headshot.png
[binary content of headshot.png]
✅ Pros:
- Dead simple. The body is the file; nothing to parse.
- Portable and streams naturally.
- A good fit for machine-to-machine “here is one blob” calls.
❌ Cons:
- No room for metadata in the body – you push it into headers or the URL, which is less tidy.
- Only one file per request. Need several files or several fields? You want multipart from §1 or §2.
Caution: Use
--data-binary, not-d/--data, when testing with curl.-dstrips newlines and null bytes from file input and will quietly corrupt binary payloads – it’s caught more than one person out.
A word on limits, safety, and security
Accepting uploads means accepting input from someone you don’t control, so a few guardrails are worth having regardless of which approach you pick:
- Cap the size. An unbounded upload endpoint is a denial-of-service waiting to happen. Most runtimes let you set a maximum body / multipart size (on Quarkus, e.g.
quarkus.http.limits.max-body-sizeand the multipart limits). Set it. - Don’t trust the
Content-Typeor the filename. Both come from the client. If the file type matters, sniff the actual content rather than believing the header, and never use a client-supplied filename directly as a path on disk. - Stream, don’t buffer. Prefer
InputStream/ a tempPathoverbyte[]for anything that could be large, so one big upload doesn’t blow up your heap. - Scan if it matters. If the files end up somewhere others can fetch them, virus/content scanning belongs in the pipeline.
Note: “Validate your input” is the same refrain as in the Jakarta EL post – binary input is still input. The bytes are opaque, but the size, the type, and the filename are all attacker-controllable.
Summary Comparison
| Approach | Payload shape | Portability | Metadata + file together? | Reach for it when… |
|---|---|---|---|---|
EntityPart (§1) |
multipart/form-data |
✅ Any Jakarta REST 3.1+ runtime | ✅ Yes | You want portable multipart handling. |
Quarkus @RestForm (§2) |
multipart/form-data |
✅ Quarkus only | ✅ Yes | You’re on Quarkus and want the tidiest code. |
| Raw body (§3) | application/octet-stream etc. |
✅ Any Jakarta REST runtime | ❌ Headers/URL only | One file, no metadata, machine-to-machine. |
Conclusion
Receiving binary isn’t hard once you know which of the three shapes you’re dealing with:
- If a client sends a file plus fields, that’s multipart.
– Use
EntityPartfor portable code, or Quarkus@RestFormfor the more ergonomic, Quarkus-only version. - If a client sends just the bytes, that’s a raw body.
– Use
@Consumes(APPLICATION_OCTET_STREAM)with anInputStream, and metadata goes in headers.
The recurring theme, same as for many other posts lately, is the standard-vs-vendor trade-off: EntityPart runs everywhere, @RestForm is nicer to write but ties you to Quarkus. And whichever you choose, treat the upload as untrusted input – cap the size, distrust the headers, and stream rather than buffer.
What’s Next?
This closes the loop with my old MicroProfile Part 1 post: that one returned images and PDFs, this one receives them. The same API Guide for Java repo also covers OpenAPI docs, error handling with RFC 9457, security, pagination, and API versioning. Some of those topics I have blogged about already; others might make it into future posts here.
Happy file uploading! 💾

Announcing OmniFish Build of Payara
by Jadon Ortlepp at July 08, 2026 09:59 AM
Many organisations continue to rely on Payara Server to run business-critical Jakarta EE applications. These systems often represent years of development and continue to deliver significant value, making stability and long-term maintenance a higher priority than constant platform changes.
OmniFish Build of Payara is designed for exactly these environments. While OmniFish stands strongly behind the Eclipse GlassFish project and provides top-quality support for GlassFish, we understand that it’s not straightforward to upgrade from older Payara versions to GlassFish. We decided to bridge this gap and start offering our supported builds of Payara to allow a smooth transition to a Payara Server build supported by OmniFish, without having to migrate to GlassFish to be able to benefit from our support services.
An affordable professionally maintained Payara distribution
OmniFish Build of Payara provides maintained builds of Payara Server and Payara Micro, allowing organisations to continue running their existing applications with confidence.
Our engineers maintain the platform by delivering critical bug fixes, security updates and production-ready releases on top of the latest available Payara Community version, helping teams keep their deployments current without taking on the burden of maintaining their own internal fork.
Whether you’re running a handful of applications or supporting hundreds of deployments, the goal is the same. Provide a reliable Payara runtime that you can trust in production, without risk of regressions from new changes or upgrades.
OmniFish Build of Payara currently provides builds for Payara Community 5 and 6, which are not maintained anymore. They provide a much more cost-efficient alternative to Payara Enteprise backed by recognized engineers with
[…]June 30, 2026

Jakarta Data 1.1 Beta Features and MicroProfile Health Endpoint Controls in 26.0.0.7-beta
June 30, 2026 12:00 AM
This beta introduces new Jakarta Data 1.1 beta capabilities, including stateful repositories, enhanced query restrictions, and the @First annotation. It also adds configuration-based control over MicroProfile Health REST endpoints when file-based health checks are enabled.
The Open Liberty 26.0.0.7-beta includes the following beta features (along with all GA features):
See also previous Open Liberty beta blog posts.
Preview of some Jakarta Data 1.1 M3 capabilities
The beta release previews some new capabilities at the Jakarta Data 1.1 Milestone 3 level:
-
Stateful repositories
-
The
@Firstannotation -
Restrictionparameters on repository@Findand@Deletemethods -
Constraintsubtype parameters on repository@Findand@Deletemethods
Also included in prior betas are:
-
Retrieving a subset or projection of entity attributes
-
The
@Isannotation
Previously, parameter-based @Find and @Delete methods had no way to filter on conditions other than equality. This limitation can now be overcome by typing the repository method parameter with a Constraint subtype or by indicating the Constraint subtype using the @Is annotation. Alternatively, the repository method can include a special parameter of type Restriction, allowing the application to supply one or more restrictions at run time when it invokes the repository method.
Prior to this release, all Jakarta Data repositories were stateless, operating without externalizing a persistence context to the application. Now, you can define a repository as stateful by using the repository lifecycle method annotations in the jakarta.data.repository.stateful package, enabling the repository to operate with a persistence context.
Previously, repository Find methods could not enforce returning only the first result or the first few results. That capability is now available with the @First annotation.
In Jakarta Data, you write simple Java objects that are called Entities to represent data, and interfaces that are called Repositories to define operations on data. You inject a Repository into your application and use it. The implementation of the Repository is automatically provided for you!
Start by defining an entity class that corresponds to your data. With relational databases, the entity class corresponds to a database table. The entity properties, which include the public methods and fields of the entity class, generally correspond to the columns of the table.
An entity class can be:
-
annotated with
jakarta.persistence.Entityand related annotations from Jakarta Persistence. -
a Java class without entity annotations, in which case the primary key is inferred from an entity property named
idor ending withId. Entity property namedversiondesignates an automatically incremented version column.
The following shows an example of a simple entity:
@Entity
public class Product {
@Id
public long id;
public String name;
public boolean onSale;
public double price;
public double weight;
}After you define the entity to represent the data, it is usually helpful to have your IDE generate a static metamodel class for it. By convention, static metamodel classes begin with the underscore character, followed by the entity name. Because this beta is being made available well before the release of Jakarta Data 1.1, we cannot expect IDEs for this generation yet. However, we can provide the static metamodel class that an IDE would be expected to generate for the Product entity:
@StaticMetamodel(Product.class)
public interface _Product {
String ID = "id";
String NAME = "name";
String ONSALE = "onSale";
String PRICE = "price";
String WEIGHT = "weight";
NumericAttribute<Product, Long> id = NumericAttribute.of(
Product.class, ID, long.class);
TextAttribute<Product> name = TextAttribute.of(
Product.class, NAME);
BooleanAttribute<Product> onSale = BooleanAttribute.of(
Product.class, ONSALE, boolean.class);
NumericAttribute<Product, Double> price = NumericAttribute.of(
Product.class, PRICE, double.class);
NumericAttribute<Product, Double> weight = NumericAttribute.of(
Product.class, WEIGHT, double.class);
}The first half of the static metamodel class includes constants for each of the entity attribute names so that you don’t need to otherwise hardcode string values into your application. The second half of the static metamodel class provides a special instance for each entity attribute, from which you can build restrictions and sorting to apply to queries at run time. These repository queries enable powerful and flexible data operations.
Built-in interfaces like BasicRepository and CrudRepository can be extended to add general-purpose methods for inserting, updating, deleting, and querying entities.
To compose a stateful repository, extend the built-in DataRepository interface. This interface allows you to define at least one stateful repository method using the @Detach, @Merge, @Persist, @Refresh, or @Remove annotations. Once the repository is stateful, any find methods you define will return entities that operate within a persistence context.
@Repository(dataStore = "java:app/jdbc/my-example-data")
public interface Products extends DataRepository<Product, Long> {
// Filtering is pre-defined at development time by the @Is annotation,
@Find
@First
@OrderBy(_Product.PRICE)
@OrderBy(_Product.NAME)
Optional<Product> leastExpensiveUpTo(
@By(_Product.PRICE) @Is(AtMost.class) double maxPrice,
@By(_Product.NAME) @Is(Like.class) String namePattern);
// Constraint types, such as Like, can also pre-define filtering.
// Allow additional filtering at run time by including a Restriction,
@Find
Page<Product> named(@By(_Product.NAME) Like namePattern,
Restriction<Product> filter,
Order<Product> sorting,
PageRequest pageRequest);
@Persist
@Transactional
void persist(Product product);
// Retrieve a single entity attribute, identified by @Select,
@Find
@Select(_Product.PRICE)
Optional<Double> priceOf(@By(_Product.ID) long productNum);
// Retrieve multiple entity attributes as a Java record,
@Find
@Select(_Product.WEIGHT)
@Select(_Product.NAME)
Optional<WeightInfo> weightAndNameOf(@By(_Product.ID) long productNum);
static record WeightInfo(double itemWeight, String itemName) {}
}Following is an example of using the stateful repository and static metamodel.
@DataSourceDefinition(name = "java:app/jdbc/my-example-data",
className = "org.postgresql.xa.PGXADataSource",
databaseName = "ExampleDB",
serverName = "localhost",
portNumber = 5432,
user = "${example.database.user}",
password = "${example.database.password}")
public class MyServlet extends HttpServlet {
@Inject
Products products;
@Inject
UserTransaction tx;
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
// Persist:
Product prod = Product.of(1, name, false, 99.99, 10.5);
products.persist(prod);
// Filter by supplying values only:
tx.begin();
products.leastExpensiveUpTo(1000.00, "%computer%")
.ifPresent(p -> {
p.setOnSale(false);
p.setPrice(p.getPrice() + 50.00);
});
tx.commit();
// Compute filtering at run time,
Page<Product> page1 = products.named(
Like.suffix("printer"),
Restrict.all(_Product.price.times(taxRate).plus(shipping).lessThan(250.0),
_Product.weight.times(kgToPounds).between(10.0, 20.0)),
Order.by(_Product.price.desc(),
_Product.name.asc(),
_Product.id.asc()),
PageRequest.ofSize(10));
// Find one entity attribute:
price = products.priceOf(prod.id).orElseThrow();
// Find multiple entity attributes as a Java record:
products.weightAndNameOf(prod.id).ifPresent(info ->
System.out.println(info.itemName() + " weighs " +
info.itemWeight() + " kg.")
);
}
}To learn more about this feature, see the following resources:
-
Maven coordinates for Data 1.1 Milestone 3:
<dependency>
<groupId>jakarta.data</groupId>
<artifactId>jakarta.data-api</artifactId>
<version>1.1.0-M3</version>
</dependency>Disabling mpHealth-4.0 REST endpoints when file-based health checks are enabled
The mpHealth-4.0 feature enables support for MicroProfile Health 4.0 in Open Liberty. The feature also includes a file-based health check mechanism as an alternative to the /health REST endpoints. When the file-based health check mechanism is enabled, you can now disable the /health/started, /health/live, and /health/ready REST endpoints using server configuration attributes.
Previously, when file-based health checks were enabled, the REST-based MicroProfile Health endpoints were still registered and accessible. This behavior was often redundant for Kubernetes deployments that rely on file-based health checks, where users typically configure probes using the exec strategy rather than httpGet or gRPC. In these scenarios, the REST health endpoints are not used.
To address this redundancy, the beta release introduces a new optional mpHealth server configuration attribute that allows REST health endpoints to be disabled when file-based health checks are enabled.
The mpHealth-4.0 feature adds a new optional enableEndpoints="false" attribute to the mpHealth server configuration element in server.xml file. An equivalent environment variable, MP_HEALTH_ENABLE_ENDPOINTS=false, is also supported.
When this option is set to false and file-based health checks are enabled, the server does not register or expose the MicroProfile Health REST endpoints (/health, /health/live, /health/ready, /health/started). Requests to these endpoints return '404 Not Found' response.
File-based health checks can be enabled with the checkInterval configuration attribute or the MP_HEALTH_CHECK_INTERVAL environment variable.
If both the environment variable and server.xml file configuration are specified, the server.xml setting takes precedence at runtime.
<server>
<featureManager>
<feature>mpHealth-4.0</feature>
</featureManager>
<!-- Enable file-based health checks but disable HTTP endpoints -->
<mpHealth startupCheckInterval="1s" checkInterval="5s" enableEndpoints="false" />
...
</server>If either the enableEndpoints configuration attribute or the MP_HEALTH_ENABLE_ENDPOINTS environment variable is not set, the default value is true, and the health check REST endpoints are enabled and exposed.
Note: This capability is supported only when the file‑based health check mechanism is enabled. If file-based health checks are not enabled and the new enableEndpoints configuration attribute or environment variable is specified, a warning message is logged. The REST health endpoints remain enabled by default.
For more information, see the documentation.
Try it now
To try out these features, update your build tools to pull the Open Liberty All Beta Features package instead of the main release. The beta works with Java SE 21, Java SE 17, Java SE 11, and Java SE 8.
If you’re using Maven, you can install the All Beta Features package using:
<plugin>
<groupId>io.openliberty.tools</groupId>
<artifactId>liberty-maven-plugin</artifactId>
<version>3.12.0</version>
<configuration>
<runtimeArtifact>
<groupId>io.openliberty.beta</groupId>
<artifactId>openliberty-runtime</artifactId>
<version>26.0.0.7-beta</version>
<type>zip</type>
</runtimeArtifact>
</configuration>
</plugin>You must also add dependencies to your pom.xml file for the beta version of the APIs that are associated with the beta features that you want to try. For example, the following block adds dependencies for two example beta APIs:
<dependency>
<groupId>org.example.spec</groupId>
<artifactId>exampleApi</artifactId>
<version>7.0</version>
<type>pom</type>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>example.platform</groupId>
<artifactId>example.example-api</artifactId>
<version>11.0.0</version>
<scope>provided</scope>
</dependency>Or for Gradle:
buildscript {
repositories {
mavenCentral()
}
dependencies {
classpath 'io.openliberty.tools:liberty-gradle-plugin:4.0.0'
}
}
apply plugin: 'liberty'
dependencies {
libertyRuntime group: 'io.openliberty.beta', name: 'openliberty-runtime', version: '[26.0.0.7-beta,)'
}Or if you’re using container images:
FROM icr.io/appcafe/open-liberty:betaOr take a look at our Downloads page.
If you’re using IntelliJ IDEA, Visual Studio Code or Eclipse IDE, you can also take advantage of our open source Liberty developer tools to enable effective development, testing, debugging and application management all from within your IDE.
For more information on using a beta release, refer to the Installing Open Liberty beta releases documentation.
We welcome your feedback
Let us know what you think on our mailing list. If you hit a problem, post a question on StackOverflow. If you hit a bug, please raise an issue.
June 10, 2026
GlassFish 8.0.3 Released: Performance optimizations and security fixes
by Ondro Mihályi at June 10, 2026 04:27 PM
The latest version of Eclipse GlassFish 8.0.3 was released on June 7, 2026. This update focuses heavily on security improvements across various components and introduces significant performance optimizations for both Jakarta Faces rendering and Embedded GlassFish startup times. The release of GlassFish 8.0.3 further reenforces that GlassFish is an actively maintained, enterprise-grade production platform.

Security fixes and brute force prevention
For production deployments, security is very important. GlassFish 8.0.3 brings several critical security fixes and a new mechanism to prevent brute force attacks on admin interfaces.
The most notable security improvement is the fix for CVE-2024-9342 (6.3 MEDIUM), which addresses a vulnerability that allowed Login Brute Force attacks against the Admin interface. The fix covers all admin interfaces: Admin Console, CLI, and HTTP. The login mechanism now progressively delays responses to failed login attempts for the same caller’s IP address, making brute-force password guesses impractical and time-consuming. It includes anti-DDoS measures to prevent attackers from locking out the admin interfaces. It also supports cluster and proxy setups to correctly and safely identify the original caller. And it always lets local connections through so that local administration (from localhost or via an SSH tunnel) is never delayed.
In addition to this, GlassFish 8.0.3 includes fixes for several other CVEs in Grizzly and JAXB Impl that have not yet been officially published. These address different areas of the server, including an HTTP smuggling type of attack and a
[…]May 19, 2026
Jakarta EE 11, Spring Boot 4.0, and more in 26.0.0.5
May 19, 2026 12:00 AM
This release introduces official support for Jakarta EE 11, Spring Boot 4.0 applications, and updated TLS/SSL cipher handling in Open Liberty, including enhanced Spring Boot deployment support and simplified SSL cipher configuration.
In Open Liberty 26.0.0.5:
View the list of fixed bugs in 26.0.0.5.
Check out previous Open Liberty GA release blog posts.
Develop and run your apps using 26.0.0.5
If you’re using Maven, include the following in your pom.xml file:
<plugin>
<groupId>io.openliberty.tools</groupId>
<artifactId>liberty-maven-plugin</artifactId>
<version>3.12.0</version>
</plugin>Or for Gradle, include the following in your build.gradle file:
buildscript {
repositories {
mavenCentral()
}
dependencies {
classpath 'io.openliberty.tools:liberty-gradle-plugin:4.0.0'
}
}
apply plugin: 'liberty'Or if you’re using container images:
FROM icr.io/appcafe/open-libertyOr take a look at our Downloads page.
If you’re using IntelliJ IDEA, Visual Studio Code or Eclipse IDE, you can also take advantage of our open source Liberty developer tools to enable effective development, testing, debugging and application management all from within your IDE.

Jakarta EE 11 Core Profile, Web Profile, and Platform
Jakarta EE 11 Core Profile, Web Profile and Platform are now officially supported in Open Liberty! We’d like to start by thanking all those who provided feedback throughout our various betas.
Jakarta EE 11 marks a major milestone. It is the first Jakarta release to add a new specification to the platform since Java EE 8 in 2017 and, therefore, the first to provide a new component specification since the platform was taken over by the Eclipse Foundation. Among the many updates to existing Java specifications, it also removes all optional specifications and functions from the Platform. Liberty continues to support those optional specifications and functions when combined with Jakarta EE 11 features.
The Core Profile specification was introduced in Jakarta EE 10 to provide a profile for lightweight cloud native applications such as MicroProfile-based applications. With the introduction of Jakarta EE 11 support in this release, the MicroProfile 7.0 and 7.1 features also now work with Jakarta EE 11. You can run your MicroProfile 7 applications using either Jakarta EE 10 or Jakarta EE 11 features.
The following specifications make up the Jakarta Platform and the Core and Web profiles:
Jakarta EE Core Profile 11
| Specification | Updates | Liberty Feature Documentation |
|---|---|---|
Major update |
||
Major update |
||
Minor update |
||
Minor update |
||
Unchanged |
||
Unchanged |
||
Unchanged |
Jakarta EE Web Profile 11
| Specification | Updates | Liberty Feature Documentation |
|---|---|---|
Major Update |
See previous table |
|
New |
||
Major update |
||
Major update |
||
Major update |
||
Minor update |
||
Minor update |
||
Minor update |
||
Minor update |
||
Minor update |
||
Minor update |
||
Minor update |
||
Minor update |
||
Unchanged |
Not applicable |
|
Unchanged |
||
Unchanged |
||
Unchanged |
Not applicable |
Jakarta EE Platform 11
| Specification | Updates | Liberty Feature Documentation |
|---|---|---|
Major update |
See previous table |
|
Major update |
||
Unchanged |
||
Unchanged |
||
Unchanged |
||
Unchanged |
||
Unchanged |
||
Unchanged |
| Enterprise Beans 4.0 is unchanged, but the optional EJB 2.x function is no longer enabled when the enterpriseBeans-4.0 feature is configured with other Jakarta EE 11 features. Users who want to use EJB 2.x APIs must also add the enterpriseBeansHome-4.0 feature. |
Liberty provides convenience features for running all of the component specifications that are contained in the Jakarta EE 11 Web Profile (webProfile-11.0) and the Jakarta EE 11 Platform (jakartaee-11.0). These convenience features enable you to rapidly develop applications using all of the APIs contained in their respective specifications. For Jakarta EE 11 features in the application client, use the jakartaeeClient-11.0 Liberty feature.
To enable the Jakarta EE Platform 11 features, add the jakartaee-11.0 feature to your server.xml file:
<featureManager>
<feature>jakartaee-11.0</feature>
</featureManager>Alternatively, to enable the Jakarta EE Web Profile 11 features, add the webProfile-11.0 feature to your server.xml file:
<featureManager>
<feature>webProfile-11.0</feature>
</featureManager>Although no convenience feature exists for the Core Profile, you can enable its equivalent by adding the following features to your server.xml file:
<featureManager>
<feature>jsonb-3.0</feature>
<feature>jsonp-2.1</feature>
<feature>cdi-4.1</feature>
<feature>restfulWS-4.0</feature>
</featureManager>To run Jakarta EE 11 features on the Application Client Container, add the following entry in your client.xml file:
<featureManager>
<feature>jakartaeeClient-11.0</feature>
</featureManager>For more information reference:
Spring Boot 4.0
Open Liberty currently supports running Spring Boot 1.5.x, 2.x, and 3.x applications. With the introduction of the new springBoot-4.0 feature, users can now deploy Spring Boot 4.x applications. While Liberty has consistently supported Spring Boot applications packaged as WAR files, this enhancement extends support to both JAR and WAR formats for Spring Boot 4.x applications.
The springBoot-4.0 feature provides complete support for running a Spring Boot 4.x application on Open Liberty, as well as the ability to thin the application when building containerized applications.
To use this feature, users must be running Java 17 or later with Jakarta EE 11 features enabled. If the application uses servlets, it must be configured to use servlet-6.1. Include the following features in your server.xml file to configure the server.
<featureManager>
<feature>springBoot-4.0</feature>
<feature>servlet-6.1</feature>
</featureManager>The server.xml configuration for deploying a Spring Boot application follows the same approach used in earlier Liberty Spring Boot versions.
<springBootApplication id="spring-boot-app" location="spring-boot-app-0.1.0.jar" name="spring-boot-app" />As in earlier versions, the Spring Boot application JAR can be deployed by placing it in the /dropins/spring folder. The springBootApplication configuration in the server.xml file can be omitted when this deployment method is used.
Update to TLS/SSL Cipher support
Liberty now uses the effective cipher list from the JDK for SSL configuration. The securityLevel attribute in the SSL configuration is not used anymore. In addition, the enabledCiphers attribute in the SSL config is updated to customize the SSL ciphers in a more flexible way.
Liberty’s securityLevel based cipher categories no longer provide meaningful value. The MEDIUM and LOW categories contain no remaining ciphers.
The enabledCiphers attribute now has two mutually exclusive modes: (1) Specify a custom list of ciphers separated by spaces, or (2) Specify filter criteria to add (+) or remove (-) cipher suites from the effective JDK cipher list. If the value set in enabledCiphers contains a static entry and a +/- entry, an error is logged, and the server ignores the enabledCiphers value by returning the effective JDK cipher list.
Existing Usage: A user sets securityLevel as HIGH
<ssl id="defaultSSL" securityLevel="HIGH"/>The securityLevel attribute is now ignored, so the previous <ssl> configuration is treated equivalently to the configuration shown here where there is no securityLevel attribute configured.
<ssl id="defaultSSL"/>Existing Usage: A user specifies all ciphers from the effective JDK list, excluding all TLS_RSA ciphers except for one (TLS_RSA_WITH_AES_128_GCM_SHA256)
<ssl id="defaultSSL" securityLevel="CUSTOM" enabledCiphers="TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384 TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256 TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256 TLS_DHE_DSS_WITH_AES_256_GCM_SHA384 TLS_DHE_DSS_WITH_AES_128_GCM_SHA256 TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA384 TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256 TLS_DHE_DSS_WITH_AES_256_CBC_SHA256 TLS_DHE_DSS_WITH_AES_128_CBC_SHA256 TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA TLS_DHE_DSS_WITH_AES_256_CBC_SHA TLS_DHE_DSS_WITH_AES_128_CBC_SHA TLS_RSA_WITH_AES_128_GCM_SHA256">Example with new syntax: Use wildcards to achieve the same logic
<ssl id="defaultSSL" enabledCiphers="-TLS_RSA* +TLS_RSA_WITH_AES_128_GCM_SHA256"/>To learn more about Transport Security, see SSL Constants Javadoc, JSSEProvider Javadoc, and SSL Configuration Reference.
Security vulnerability (CVE) fixes in this release
| CVE | CVSS Score | Vulnerability Assessment | Versions Affected | Notes |
|---|---|---|---|---|
7.5 |
Identity spoofing |
17.0.0.3-26.0.0.4 |
For a list of past security vulnerability fixes, reference the Security vulnerability (CVE) list.
Notable bugs fixed in this release
We’ve spent some time fixing bugs. The following sections describe just some of the issues resolved in this release. If you’re interested, here’s the full list of bugs fixed in 26.0.0.5.
Get Open Liberty 26.0.0.5 now
Available through Maven, Gradle, Docker, and as a downloadable archive.
March 22, 2026

A mix between Proxmox, Oracle Linux and Docker, my new Homelab
March 22, 2026 12:00 AM

Disclaimers: I really tried to write this with AI, but the slop was too much. So this was written like a caveman; I hope you enjoy it!
I've been into self-hosting for a couple of years, mostly running Raspberry Pis 24/7 on my network. Why? As a 90s kid, I've hoarded a lot of music, videos, films, and photos that I prefer to host myself due to space (> 2 TB), privacy, and costs.
Along those lines, my self-hosting procedure looked like this over the years:
- Buy a low powered device capable of running 24/7 without breaking the bank
- Install a Debian-based distro (which is common in the Raspberry Pi community)
- Connect via USB one big SSD
- Bootstrap services here and there with apt and config-file wrangling, services like
a. MiniDLNA
b. SMB Server
c. Nextcloud
d. Pi-hole
e. Tailscale
This was enough for a couple of years, and I lived through the transition Pi 2 -> Pi 3 -> Pi 4, until I reached a breaking point.
Although I like the case I chose for my last Raspberry Pi (the Nespi case), most of the time I ended up buying some kind of fan because the CPU gets really hot, and those fans broke once per semester and/or made a lot of noise. The Pi was the obvious choice because of the power vs. energy vs. price balance it offered. However, that balance was lost with the Pi 5.

From ARM to x86_64
As a self-hoster, I was quite aware of a trend in the community around the Intel N100, which finally delivered a capable and energy-efficient x86_64 processor. So, as time passed, it became the obvious choice since I didn't really use the GPIO pins on the Raspi; I'm far from a maker.
All in all, I took a brief detour from my family vacation and went to Paraguay, which has the biggest electronics market in LATAM, to get a cheap and lovely N150 machine capable of running my homelab, specifically a Blackview MP60.
This little machine included:
- 16 GB of RAM
- An NVMe SSD with 512 GB
- An SSD caddy via USB-C
- Two regular USB 2.0 and two regular USB 3.1 ports
And I added:
- A main 2 TB storage 2.5" SSD inside the caddy. A RAW space directly attached to an Oracle Linux VM
- A backup 512 GB 2.5" SSD using an external caddy. This was to isolate my backups.
Approaching the server as a software engineer

In my day job I do tons of DevOps work, but I never tried to approach my homelab like IaC. However, it was time to get serious. I made some design choices and landed on the following abstraction layers:
- Level -1: The MP60 machine
- Level 0: A hypervisor with Proxmox, which among other things allows KVM virtual machines and LXC containers, and is giving a good fight to other virtualization platforms.
- Level 1.a: The Docker House. As suggested by Proxmox staff, whenever you run Docker containers, it is preferred to run them inside a VM host. For this I chose Oracle Linux 10, which is free to use, particularly stable, and a well-known OpenELA supporter.
- Level 1.b: The Tailscale Tunnel. An Oracle Linux 9 LXC container acting as a Tailscale exit node. Hence, I'm able to reach my local network while on the road.
- Level 1.c: The Kopia storage. A Rocky Linux 10 LXC container, running nothing. Just a pure SSH server to isolate the access to the external SSD
- Level 2: Inside the Docker House. I run my services using Docker Compose files, including
To deploy this into the Docker House I also deployed a Github Actions self-hosted runner, which allowed me to create a deployment pipeline with the same tools I use daily, and evend assign the Compose creation to AI Agents (which contrary to writing this article, work really well).

In that line, once I bootstrapped a couple of stacks + a quite tailored GitHub Copilot skill ... I created the reset of deployment descriptors with GitHub Copilot sessions. This is the true power of IaC + AI

Docker vs. LXC vs. VM
One of the things that took me a while to understand was the difference between LXC containers and OCI (Docker) containers. To be honest, until this experiment I wasn't very aware of the LXC ecosystem.
So, quoting myself
- A VM is exactly that: a whole machine running over a hypervisor (in Proxmox KVM). For this I chose Oracle Linux 10 because I tend to prefer EL distros.
- An LXC is a container that isolates the memory space of a whole Linux system (including userland). Think of it as a lightweight-ish virtual machine. Again, I chose EL distros, specifically Oracle Linux and Rocky Linux.
- An OCI (Docker) container is a container that isolates the memory space of a Linux system (including userland), focused on providing an environment for a single process.
So, why Debian, Oracle and Rocky Linux? Let's find out.
A Debian bedrock
In the past I've used other hypervisor platforms like OpenNebula, pure Xen, bare-bones KVM, and vSphere with various levels of success in production. However, Proxmox was on my radar because it popped up from time to time in the Linux blogs I follow. Actually I wanted to try it a long time ago, but my previous homelab lacked the raw power to run it.
With Debian as basis, Proxmox became a Reddit community favourite to create self-hosted home labs. Which, after running it for three months, I finally get it. SREs and domestic sysadmins love Proxmox because ...
- It is easy to set up: just boot an installation pendrive, allow it to take a whole disk, and that's pretty much it
- It has various "batteries included" features, like a hypervisor firewall, backup automation, LVM-thin pool provisioning, ZFS support, cluster capabilities, Ceph, ... , all in a very intuitive user interface
- It doesn't need a beefy server to run; again, I'm using an N150 machine in a mini-PC form factor
- Eventually I can buy and join other nodes (maybe for another Paraguay travel)
- There is a community Terraform provider. So more IaC!

The battle of OpenELAs
Once I confirmed the Proxmox team advised running containers inside a VM, I decided to create a Docker server where I would deploy my services using plain old Docker Compose files. As in the the underlying layer, I wanted something easy to manage, rock-solid enough to forget, and familiar with my day-to-day cloud operations.
Hence the next step was to pick an Enterprise Linux.
What is an Enterprise Linux, BTW? Enterprise Linux is a generic name given to Linux distributions that derive in some way from Red Hat Enterprise Linux source code, with CentOS being the most famous. It was for a while the de facto downstream Linux distribution of Red Hat... until it was EOL'd by Red Hat.
Not long after that, various communities and companies stepped up to fill the niche left by CentOS, creating free (as in free coffee) Linux distros with optional support plans, to name a few:
- Alma Linux (with support via TuxCare)
- Rocky Linux (and Rocky Linux supported by CIQ)
- Oracle Linux
- OpenEuler
- SUSE Liberty Linux (which later became SUSE Multi-Linux Support)
Eventually, CIQ, Oracle, and SUSE created a joint effort called OpenELA aiming to provide accessible and buildable sources for the whole community.
Also, since all this exploded, Red Hat also offers a no-cost RHEL for developers subscription.
Do you see the problem? I had all these great options available to create my rock-solid server. Considering these distros are managed with the same tools and principles (package manager/config files/third-party compatibility), I was back at km 0 and had to decide.
This decision wasn't easy, so I had to add another criterion: who had the best logo?
- Who has the best logo? Oracle Linux, of course
- Who has the second-best logo? That's Rocky Linux
And that's how I ended up choosing. The Enterprise Linux ecosystem is a battle-tested environment that just works, and works well.


Is it worth to host your own services?
Yes but not exactly money-wise.
Between the mini-pc, SSD disks, a UPS and a living-room friendly rack I invested almost $600 and my electricity bill increased arround $3 per month. Also, I added an old Android phone as a monitoring gimmick running Beszel in kiosk mode.
Let's say my raw yearly cost is about $ 650, which doesn't account for my hourly rate (you put a number, Java tech lead, working remotely, etc.). If I consider that, this whole project is a cash-burner vs. just buying subscriptions.
However, I truly own my data in this way, and most importantly, not everything needs to be a VC backed idea. Part of life is having hobbies that help you to grow, and my whole carrer is a product of this type of hobbies, so blame me for having fun.

February 11, 2026

Scaling the Open VSX Registry responsibly with rate limiting
February 11, 2026 08:05 PM
The Open VSX Registry has become widely used infrastructure for modern developer tools. That growth reflects strong trust from the ecosystem, and it brings a shared responsibility to keep the Registry reliable, predictable, and equitable for everyone who depends on it.
In a previous post, I shared an update on strengthening supply-chain security in the Open VSX Registry, including the introduction of pre-publish checks for extensions. This post focuses on the operational side of the same goal: ensuring the Registry remains resilient and sustainable as usage continues to grow.
The Open VSX Registry is free to use, but not free to operate
Operating a global extension registry requires sustained investment in:
- Compute and storage to serve and index extensions at scale
- Bandwidth to deliver downloads and metadata worldwide
- Security to protect users, publishers, and the service itself
- Staff to operate, monitor, secure, and support the Registry
These costs scale directly with usage.
AI-driven usage is scaling faster than ever
Demand on the Open VSX Registry is increasing rapidly, and AI-enabled development is accelerating that trend. A single developer can now orchestrate dozens of agents and automated workflows, generating traffic that previously would have required entire teams. In practical terms, that can mean the equivalent load of twenty or more traditional users, with direct impact on compute, bandwidth, storage, security capacity, and operational oversight.
This is not unique to the Open VSX Registry. It is an industry-wide challenge. Stewards of public package registries such as Maven Central, PyPI, crates.io, and Packagist have recently raised the same sustainability concerns in a joint statement on sustainable stewardship. Mike Milinkovich, Executive Director of the Eclipse Foundation, echoed that message in his post on aligning responsibility with usage.
As reliance on shared open infrastructure grows, sustaining it becomes a collective responsibility across the ecosystem.
Open VSX is critical, and often invisible, infrastructure
Many developers and organisations may not realise how often they rely on the Open VSX Registry. It provides the extension infrastructure behind a growing number of modern developer platforms and tools, including Amazon’s Kiro, Cursor, Google Antigravity, Windsurf, VSCodium, IBM’s Project Bob, Trae, Ona (formerly Gitpod), and others.
If you use one of these tools, you use the Open VSX Registry.
The Open VSX Registry remains a neutral, vendor-independent public service, operated in the open and governed by the Eclipse Foundation for the benefit of the entire ecosystem.
For developers, the expectation is simple: Open VSX should remain fast, stable, secure, and dependable as the ecosystem grows.
As more platforms and automated systems rely on the Registry, continuous machine-driven traffic can place sustained load on shared infrastructure. Without clear operational guardrails, that can affect performance and availability for everyone.
A practical step for sustainable and reliable operations
Usage has shifted from primarily human-driven access to continuous automation driven by CI systems, cloud-based tooling, and AI-enabled workflows. That shift requires operational controls that scale predictably.
Rate limiting provides a structured way to manage high-volume automated traffic while preserving the performance developers expect. It also ensures that operational decisions are based on real usage patterns and that expectations for large-scale consumption are clear and transparent.
Rate limits aren’t entirely new. Like most public infrastructure services, the Open VSX Registry has long had baseline protections in place to prevent sustained high-volume usage from degrading performance for everyone. What’s changing now is that we’re moving from a one-size-fits-all approach to defined tiers that more accurately reflect different usage patterns. This allows us to keep the Registry stable and responsive for developers and open source projects, while providing a clear, supported path for sustained at-scale consumption.
For individual developers and open source projects, day-to-day workflows remain unchanged. Publishing extensions, searching the registry, and installing tools will continue to work as they always have for typical usage.
A measured, transparent rollout
Rate limiting will be introduced incrementally, with an emphasis on platform health and operational stability.
The initial phase focuses on visibility and observation before any limits are adjusted. This includes improved insight into traffic patterns for registered consumers, baseline protections for anonymous high-volume usage, and a monitoring period before any limits are adjusted.
This work is being done in the open so the community can follow what is changing and why. Progress and discussion are tracked publicly in the Open VSX deployment issue:
https://github.com/EclipseFdn/open-vsx.org/issues/5970
What this means for the community
The goal is to keep the Open VSX Registry reliable and fair as it scales, while minimizing impact on normal use.
For most users, nothing should feel different. Developers should see little to no impact, and publishers should not experience disruption to normal publishing workflows. Sustained, high-volume automated consumers may need to coordinate with the Registry to ensure their usage can be supported reliably over time.
Organisations that depend on the Open VSX Registry for sustained or commercial-scale usage are encouraged to get in touch. Coordinating early helps us plan capacity, maintain reliability, and support the broader ecosystem. Please contact the Open VSX Registry team at infrastructure@eclipse-foundation.org.
The intent is not restriction, but clarity in support of fairness, stability, and long-term sustainability.
Looking ahead
Automation is reshaping how developer infrastructure is consumed. Responsible rate limiting is one step toward ensuring the Open VSX Registry can continue to serve the ecosystem reliably as those patterns evolve.
We will continue to adapt based on real-world usage and community input, with the goal of keeping the Open VSX Registry a dependable shared resource for the long term.
February 05, 2026
We’re hiring: improving the services that support a global open source community
February 05, 2026 07:02 PM
The Eclipse Foundation supports a global open source community by providing trusted platforms, services, and governance. As a vendor-neutral organisation, we operate infrastructure that enables collaboration across projects, organisations, and industries.
This infrastructure supports project governance, developer tooling, and day-to-day operations across Eclipse open source projects. While much of it runs quietly in the background, it plays a critical role in the health, security, and sustainability of those projects.
We are expanding the Software Development team with two new roles. Both positions involve contributing to the design, development, and operation of services that are widely used, security-sensitive, and expected to operate reliably at scale.
Software engineer: security and detection
One of the roles is a Software Engineer position with a focus on security and detection engineering, alongside general development and operations.
This role will work on Open VSX Registry, an open source registry for VS Code extensions operated by the Eclipse Foundation. As adoption grows, maintaining the integrity and trustworthiness of the registry requires continuous analysis, detection, and operational safeguards.
In this role, you will:
- Analyse suspicious or malicious extensions and related artefacts
- Develop, test, and maintain YARA rules to detect malicious or policy-violating content
- Design, implement and contribute improvements to backend services, including new features, abuse prevention, rate-limiting, and operational safeguards
This is hands-on work that combines backend development with practical security analysis. The outcome directly improves the reliability, integrity, and operation of services that are part of the developer tooling supply chain.
For more context on this work, see my recent post on strengthening supply-chain security in Open VSX.
To apply:
https://eclipsefoundation.applytojob.com/apply/eXFgacP5SJ/Software-Engineer
Software developer: open source project tooling and services
The second role is a Software Developer position focused on improving the tools and services that support Eclipse open source projects.
This work centres on maintaining and evolving systems that our open source projects and contributors rely on every day. It includes:
- Maintaining and modernising project-facing applications such as projects.eclipse.org, built with Drupal and PHP
- Developing Python tooling to automate internal processes and improve project metrics
- Improving services written in Java or JavaScript that support project governance workflows
As with the Software Engineer role, this position involves contributing to production services. The focus is on incremental improvement, reducing technical debt, and ensuring systems remain maintainable, secure, and reliable as they evolve.
To apply:
https://eclipsefoundation.applytojob.com/apply/mvaSS7T8Ox/Software-Developer
What we are looking for
Across both roles, we are looking for people who:
- Take a pragmatic approach to problem solving
- Are comfortable working in a remote, open source environment
- Value clear documentation and thoughtful communication
- Enjoy understanding how systems work and how to improve them over time
If you are interested in working on open source infrastructure with real users and real impact, we would be happy to hear from you.
January 16, 2026

The Ultimate 10 Years Java Garbage Collection Guide (2016–2026) – Choosing the Right GC for Every Workload
by Alexius Dionysius Diakogiannis at January 16, 2026 04:19 PM
First published on foojay.io
Memory management remains the primary factor for application performance in enterprise Java environments. Between 2017 and 2025, the ecosystem shifted from manual tuning to architectural selection. Industry data suggests that 60 percent of Java performance issues and 45 percent of production incidents in distributed systems stem from suboptimal Garbage Collection (GC) behavior. This guide provides a strategic framework for selecting collectors based on workload characteristics. It covers the transition from legacy collectors to Generational ZGC, analyzing trade-offs regarding throughput, latency, and hardware constraints with mathematical precision.
 Introduction
Introduction
The era of “write once, run anywhere” has evolved. In modern cloud-native architectures, you must “tune everywhere.” The migration from bare-metal monoliths to containerized microservices fundamentally changed how the Java Virtual Machine (JVM) interacts with memory.
A collector that performs well for a batch process often fails in a low-latency trading API. Selecting the wrong collector is no longer a minor configuration error. It is an architectural flaw. This flaw leads to cascading latency in microservices, instability in database connections, and wasted cloud resources.
This guide analyzes five primary workload categories. It synthesizes performance data from JDK 8 through JDK 25. It provides a technical decision matrix for Senior Architects and Site Reliability Engineers (SREs).
Workload Analysis and Strategic Selection
We categorize applications based on their resource patterns and business goals. Each category requires a distinct memory management strategy supported by specific mathematical tuning models.
Microservices (Spring Boot/Quarkus)
The Challenge: You must balance Resident Set Size (RSS) efficiency against startup time.
In Kubernetes environments, engineers often restrict pods to fewer than 2 processors and 2 GB of RAM. The JVM ergonomics often default to the Serial GC in these conditions. This happens even if you specify another collector.
The Strategy:
For most microservices, G1 GC is the balanced choice. However, deployment density matters. Research shows that G1 is the most memory-efficient collector for dense environments. In JDK 20 and later, engineers removed one of the marking bitmaps from G1. This reduced its native memory footprint, making it highly suitable for small containers.
Warning on ZGC in Microservices:
Do not blindly apply ZGC to small containers. ZGC requires significant headroom. It typically needs 25 to 35 percent free memory to function without stalling. In an 8 GB container, ZGC images are significantly larger than G1 images. Tests show that ZGC struggles to manage trees of 10 services in constrained RAM. It often fails with Out-Of-Memory (OOM) errors where G1 remains stable.
Legacy JEE (WebLogic/JBoss/Payara)
The Challenge: These systems handle large session states and accumulate legacy memory leaks.
Older applications relied on Concurrent Mark Sweep (CMS). CMS was designed for shorter pauses but required shared processor resources. It was deprecated in JDK 9 and removed in JDK 14.
The Strategy:
G1 GC is the primary successor for these workloads. It handles large heaps up to 128 GB by using region-based incremental collection.
Operators must monitor heap usage after full cycles. If heap usage consistently stays above 85 percent, the application likely has a memory leak. This indicates a code issue rather than a tuning issue.
Stateful UI (Vaadin/JSF)
The Challenge: These frameworks generate numerous medium-lived objects.
User sessions reside in the heap for minutes or hours. This behavior contradicts the “weak generational hypothesis” that most objects die young. Standard configurations often promote these session objects to the Old Generation too quickly. This leads to expensive full-heap collections.
The Strategy:
Tuning the SurvivorRatio is critical here. A standard ratio is 8 to 1. Changing this to 6 to 1 allows objects to stay in the Young Generation longer. Empirical testing shows this reduces premature promotions by 25 to 30 percent. Generational ZGC is also an optimal choice here. It manages mixed collections across generations effectively.
Data Intensive (Spark/Flink/Batch)
The Challenge: The priority is raw throughput.
Batch workloads must complete processing windows quickly. Individual pause times do not matter. A 5-second pause is acceptable if the job finishes 10 minutes earlier.
The Strategy:
Parallel GC (the “throughput collector”) remains the champion. It utilizes all available cores for collection, achieving 95 to 98 percent processing efficiency. However, it requires careful thread configuration on large multi-core servers to prevent OS context-switching overhead.
Mathematical Tuning Model: GC Threads
To optimize Parallel GC, explicitly set the thread count (ThreadsGC) based on your available CPU cores (Ncpu).
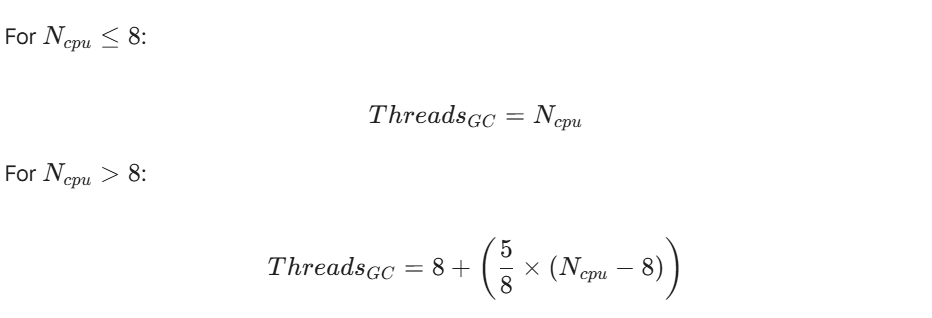
This formula ensures the GC utilizes resources efficiently without overwhelming the operating system scheduler on massive batch servers.
Ultra-Low Latency
The Challenge: High-frequency APIs require sub-millisecond pauses.
Trading systems cannot tolerate the unpredictable pauses of G1 or Parallel GC. However, low-latency collectors like ZGC race against the application’s object creation. If the application creates objects faster than the collector can clean them, you hit an “Allocation Stall.”
The Strategy:
ZGC maintains pause times under 1 millisecond for heaps ranging from 8 GB to 16 TB using colored pointers and load barriers. To ensure stability, you must monitor the Allocation Rate.
Mathematical Tuning Model: Allocation Rate
You must calculate the Allocation Rate (Ralloc) over a time period (t) to determine if your heap headroom is sufficient.
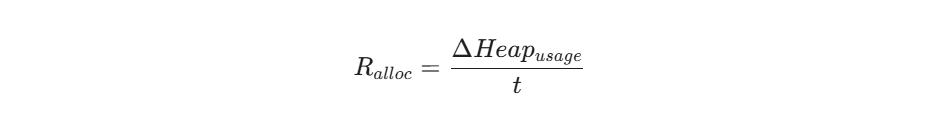
If Ralloc consistently approaches the concurrent collection speed of ZGC, you must either increase the heap size or optimize the code. For modern stacks on JDK 21 or later, Generational ZGC is the superior choice as it handles high allocation rates by frequently clearing the Young Generation, preventing stalls.
Technical Performance Deep Dives
This section explores the specific trade-offs involved in migration and architecture design.
Migration Trade-offs: ParallelOld to ZGC
Migrating from ParallelOld to ZGC is a trade-off between raw speed and predictability.
You trade approximately 7 to 15 percent of raw throughput for a 1000x improvement in pause predictability.
ZGC imposes a “tax” on the system.
- CPU Overhead: ZGC adds an 8 to 20 percent CPU overhead. This comes from the concurrent threads that run alongside your application.
- Cache Efficiency: The use of colored pointers and read barriers impacts the processor cache. L3 cache hit rates often decline by 10 to 15 percent due to pointer metadata operations.
- NUMA Penalty: In Non-Uniform Memory Access (NUMA) architectures, ZGC relocation threads can suffer a 20 to 30 percent performance penalty. You must pin these threads to local memory domains to avoid this.
Microservices and Cumulative Latency
In a microservice architecture, latency accumulates. A single user request often triggers a chain of calls across 5 to 10 services. This creates a “fan-out” effect.
If each service uses a collector like G1 or Parallel, the pauses add up. Cumulative GC pauses across a chain can amplify total latency by 3 to 5 times compared to a monolith.
Using ZGC or Shenandoah dramatically mitigates this. Tests indicate that migrating to low-latency collectors reduces this cascading latency effect by 65 percent. However, this introduces resource contention. The collector competes with application threads for CPU cycles and memory bandwidth.
Database Connectivity Stability
Database connections are heavy, long-lived objects. They test the stability of a collector.
Empirical testing indicates that CMS was historically the most stable collector for database-intensive microservices. It handled the highest number of managed instances before crashing.
Early versions of ZGC (Non-Generational) struggled here. In small container tests with DB connections, non-generational ZGC frequently threw NullPointerException errors. It failed to maintain connectivity due to allocation stalls.
Generational ZGC (JDK 21+) resolves these issues. It frequently collects the young generation where session-related objects reside. This protects the long-lived database connections.
Benchmark: In Apache Cassandra tests, non-generational ZGC failed at 75 concurrent clients. Generational ZGC maintained stability with up to 275 concurrent clients.
Technical Matrix and Decision Logic
Use this data to guide your architectural decisions.
Collector Comparison (JDK 8–25)
| Collector | Supported JDK | Ideal Heap Size | Pause Time Target | CPU Overhead | Key Technology |
| Serial | 8–25 | < 100 MB | N/A (Long STW) | Lowest | Single-threaded STW |
| Parallel | 8–25 | Any | Acceptable STW | Low | Multi-threaded STW |
| G1 | 9–25 (Default) | 6 GB – 128 GB | < 200ms | Medium | Region-based evacuation |
| ZGC | 11–25 | 8 GB – 16 TB | < 1ms | High (8-20%) | Colored pointers |
| Shenandoah | 12–25 | 2 GB – 10 TB | < 10ms | High | Concurrent compaction |
The Decision Tree
Follow this logic to select the correct collector.
Scenario A: The Resource Constraint
Is the environment a tiny container (< 2 cores/2GB RAM) or is the heap < 100 MB?
- Selection: Use Serial GC (
-XX:+UseSerialGC).
Scenario B: The Batch Processor
Is the priority 4–8 hour batch processing windows where total throughput is the only metric?
- Selection: Use Parallel GC (
-XX:+UseParallelGC).
Scenario C: The Generalist
Is the application a general web service with balanced latency and throughput needs? Is the heap-to-container ratio > 80%?
- Selection: Use G1 GC (
-XX:+UseG1GC).
Scenario D: The High-Performance Specialist
Does the application require sub-1ms response times on large heaps (> 32 GB) on JDK 21+? Do you have 25% memory headroom?
- Selection: Use Generational ZGC (
-XX:+UseZGC -XX:+ZGenerational).
Scenario E: The Alternative
Are you on a non-Oracle OpenJDK and require low latency without ZGC multi-mapping?
- Selection: Use Shenandoah GC (
-XX:+UseShenandoahGC).
G1 vs Generational ZGC in 2026
For years, the standard advice was “G1 is always best.” The arrival of Generational ZGC in JDK 21 through JDK 25 challenges this.
The legacy non-generational ZGC suffered from allocation stalls. It had to scan the entire heap to find garbage. This works poorly when an application creates objects faster than the collector can clean them.
Generational ZGC exploits the Weak Generational Hypothesis, most objects die young.
By splitting the heap into generations, it achieves two goals:
- Throughput: It improves throughput by 10 percent compared to its single-generation predecessor.
- Stability: It prevents the allocation stalls that plagued earlier versions in high-concurrency environments.
Architect’s Note:
In JDK 25, G1 remains the most memory-efficient option regarding RSS. For performance-critical stacks on JDK 21+, Generational ZGC should be the baseline, provided you provision the infrastructure with at least 25 percent memory headroom.
The Architect’s Roadmap: Optimization by JDK Version
As a Principal Java Architect, I recognize that being “stuck” on a specific JDK version often involves balancing legacy stability with the need for modern performance. Here is your roadmap for optimization and troubleshooting, depending on which version of the JVM you are currently tethered to.
If you are on Java 8…
- Manage the Metaspace Shift: Since the Permanent Generation was removed in JDK 8, you must monitor your native memory usage for class metadata using
-XX:MaxMetaspaceSize. Avoid the “bad practice” of simply renaming oldMaxPermSizeflags to Metaspace without conducting a fresh analysis of your application’s class-loading needs. - Address the CMS Maintenance Gap: If you are using the Concurrent Mark Sweep (CMS) collector on free builds, be aware that it is no longer maintained and lacks critical backported patches. If performance is degrading, transition to the Parallel GC for throughput or G1 GC for a balance of latency, though be wary that G1 in the Java 8 era utilized significantly more native memory than modern versions.
- Tune for Premature Promotion: If you see high Stop-The-World (STW) durations in the Old generation, increase your
SurvivorRatiofrom the default 8:1 to 6:1. This provides more breathing room for medium-lived objects and can reduce premature promotions by up to 30%. - Leverage Performance Editions: If an upgrade is impossible, consider utilizing specialized runtimes like Liberica JDK Performance Edition, which can provide a ~10% performance boost for legacy workloads.
If you are on Java 11…
- Re-evaluate Inherited Flags: Do not carry over your Java 8 tuning scripts blindly; flags that benefited the Parallel collector often conflict with the G1 GC heuristics now active by default. For example, manually setting the young generation size can prevent G1 from accurately meeting its
MaxGCPauseMillistargets. - Be Cautious with Experimental ZGC: While ZGC was introduced in JDK 11, it was experimental and limited to Linux. It lacks generational capabilities in this version, making it highly susceptible to allocation stalls if your application’s allocation rate is high.
- Monitor G1 Native Footprint: G1 was significantly improved in JDK 11 to reduce its native memory overhead, which was a major complaint in earlier versions. Use Native Memory Tracking (NMT) with
-XX:NativeMemoryTracking=summaryto ensure your container limits are not being breached by the collector’s internal data structures.
If you are on Java 17…
- Commit to ZGC for Large Heaps: Since JDK 15, ZGC has been production-ready and is the primary choice for heaps ranging from 8 GB to 16 TB where sub-millisecond latency is required. However, ensure you have 15-25% memory headroom beyond your peak working set to accommodate ZGC’s concurrent relocation work and metadata.
- Enable Huge Pages: On Linux, enable Transparent Huge Pages (THP) or explicit large pages to achieve a “free lunch” performance boost of approximately 10%.
- Transition from CMS: If you are migrating from Java 8/11 to 17, remember that CMS was removed in JDK 14. You must move to G1 or ZGC; G1 is typically the most stable choice for memory-constrained environments where the heap-to-container ratio exceeds 80%.
- Use Modern Diagnostics: Utilize JDK Flight Recorder (JFR) for profiling with less than 2% overhead to identify fine-grained allocation patterns and object creation rates.
If you are on Java 21…
- Activate Generational ZGC: This is the most significant change in modern JVM performance. Use the flags
-XX:+UseZGC -XX:+ZGenerationalto handle high allocation rates that would have caused stalls in earlier versions. In benchmarks like Apache Cassandra, this version remains stable with up to 275 concurrent clients, whereas the non-generational version often failed at 75. - Exploit the Weak Generational Hypothesis: Generational ZGC improves throughput by 10% compared to legacy ZGC by focusing its collection efforts on the young generation where most objects “die young”.
- Leverage G1 Efficiency: If your environment is extremely memory-constrained, the G1 collector in JDK 21 is more efficient than ever, as it now requires only one marking bitmap instead of two, significantly reducing its Resident Set Size (RSS).
- Adopt Compact Object Headers: Consider enabling the compact object headers feature (experimental in 24, but maturing in late 21 updates) to reduce the memory footprint of every object on the heap, improving overall throughput.
Analogy: Navigating Java versions is like maintaining a building’s HVAC system. Java 8 is an old boiler where you must manually watch the pressure gauges (Metaspace and PermGen). Java 11 and 17 are modern units that work well but require you to clear out the old filters (inherited flags) to be effective. Java 21 is a smart climate control system: by enabling Generational ZGC, the system finally becomes intelligent enough to focus its energy only on the rooms currently in use (the young generation), saving you massive amounts of manual labor and resource cost.
Conclusion
There is no single “best” collector. There is only the right collector for your specific constraints.
Parallel GC is a massive double-decker bus. It carries the most passengers (throughput) but blocks all traffic when it stops. G1 is a fleet of mid-sized shuttles. They cause frequent but short delays. Generational ZGC is a network of drones. They deliver instantly, but they consume more energy and space to operate.
Align your JVM configuration with your business goals. Monitor your allocation rates using the equations provided. And most importantly, stop treating memory management as an afterthought.
References
- Gullapalli, V. (2025). Adaptive JVM Optimization: Charting the Path from ParallelOld to ZGC Excellence. Al-Kindi Publisher. Journal of Computer Science and Technology Studies, 7(8).
- Edelveis, C. (2024). An Overview of Java Garbage Collectors. BellSoft Corporation.
- Cai, Z., Blackburn, S. M., Bond, M. D., & Maas, M. (2022). Distilling the Real Cost of Production Garbage Collectors. arXiv:2204.06782.
- Johansson, S. (2023). Garbage Collection in Java: Choosing the Correct Collector. Oracle Corporation (Java YouTube Channel).
- Oracle Corporation. (2023-2025). Java Platform, Standard Edition HotSpot Virtual Machine Garbage Collection Tuning Guide, Release 21. Oracle Help Center.
- Reddit Community. (2021-2025). How to choose the best Java garbage collector. r/java.
- Korando, B. (2023). Introducing Generational ZGC. Inside Java.
- Johansson, S. (2023). JDK 21: The GCs keep getting better. OpenJDK Performance Blog.
- Ericson, A. (2021). Mitigating garbage collection in Java microservices. Mid Sweden University. DiVA portal.
- Canales, F., Hecht, G., & Bergel, A. (2021). Optimization of Java Virtual Machine Flags using Feature Model and Genetic Algorithm. ACM ICPE ’21 Companion.
- Diakogiannis, A. D. (2024). The Generational Z Garbage Collector (ZGC). JEE.gr.
- Diakogiannis, A. D. (2017). Ta Java VM Options pou prepei na ksereis ti kanoun!. JEE.gr.
by Alexius Dionysius Diakogiannis at January 16, 2026 04:19 PM
December 18, 2025

Jakarta EE 2025: a year of growth, innovation, and global engagement
by Tatjana Obradovic at December 18, 2025 02:07 PM
As 2025 comes to a close, it's a great moment to reflect on what we’ve achieved together as the Jakarta EE community. From major platform updates to refreshing the website and growing developer engagement, this year has been full of meaningful progress.
Celebrating Jakarta EE 11
One of our biggest milestones this year was Jakarta EE 11. This time we did the release in a different way: we released as soon as the profile or platforms were ready! The Core Profile was available in December 2024 and Web Profile in March 2025, and Jakarta EE Platform finalised in June 2025, reflecting the steady progress of the Jakarta EE community. Compatible products followed right away!
Jakarta EE 11 introduces the new Jakarta Data specification, delivers a modernised testing experience with updated TCK infrastructure based on JUnit 5 and Maven, and expands support for Java 21, including virtual threads. It also streamlines the platform by retiring older specifications such as Managed Beans, reinforcing Contexts and Dependency Injection (CDI) as the preferred programming model and continues to provide Java Records support.
This release marks a significant step forward in simplifying enterprise Java development, improving developer productivity, and supporting modern, cloud native applications. It's a true reflection of the community’s collaborative efforts and ongoing commitment to innovation.
Read the Jakarta EE 11 announcement
Introducing Jakarta Agentic AI: A New Standard for Running AI Agents on Jakarta EE
This year marked the introduction of the Jakarta Agentic AI specification project. Aimed at standardising how AI agents run within Jakarta EE runtimes, this new specification will be included in a future release. Much like Jakarta Servlet unified HTTP processing and Jakarta Batch defined batch workflows, Jakarta Agentic AI will provide a clear, annotation-driven API that defines how agents are created, managed, and executed.
Built on CDI as the core component model, the specification will establish consistent lifecycle patterns and usage semantics, making it easier for developers to implement and integrate a wide range of agent types. The project also anticipates deep integration with key Jakarta EE APIs, ensuring seamless interoperability across the platform.
Jakarta Agentic AI is being developed with broad industry collaboration in mind. The project is seeking input from subject-matter experts, vendors, and API consumers both inside and outside the Java ecosystem to build the most open, portable, and future-ready agent execution model possible. Visit the project page to learn more about the specification.
Listening and learning through the Jakarta EE Developer Survey
Our annual Jakarta EE Developer Survey remains one of the best ways to track how developers and organisations are using enterprise Java and shaping their cloud strategies. In 2025, we saw a 20% increase in participation, with over 1,700 participants sharing how they use Jakarta EE in practice.
The results show continued growth and confidence in Jakarta EE across the ecosystem. Notably, even before the full platform release was finalised, 18 percent of respondents were already using Jakarta EE 11, a strong signal of interest and early adoption.
These insights help us better understand where the community is focusing its energy, from modernising applications and adopting newer Java versions to evaluating cloud strategies and driving specification innovation. We're grateful to everyone who participated and shared their views.
Explore the 2025 developer survey findings
Learning and contributing: A growing developer ecosystem
The Jakarta EE Learn page expanded its resources to better support developers at all levels. As part of our broader effort to support community growth, we also introduced a new Contribute page, a dedicated space that outlines how individuals and organisations can get involved with Jakarta EE.
The Contribute page highlights the many ways to participate, from writing code and improving documentation to joining specification discussions or helping with community outreach. It also explains why contributing matters, what contributors gain, and how to get started.
To further support newcomers, we launched the Jakarta EE Mentorship Program, which pairs new contributors with experienced community mentors who can provide guidance, answer questions, and help them navigate the contribution process. Whether you're new to open source or simply new to Jakarta EE, the mentorship experience helps build skills, confidence, and deeper community connections.
Looking ahead: A refreshed web presence
Throughout 2025, our marketing team in collaboration with the Jakarta EE Marketing Committee worked on a major Jakarta EE website refresh to better reflect the clarity, maturity, and momentum of the community. While the full launch is now scheduled for early January, the homepage and navigation redesign is already complete and ready for rollout. The updated site features a bold new homepage, improved navigation through streamlined mega menus, and a new “Why Jakarta EE” section that helps visitors quickly understand the platform’s value.
This is just the beginning. Additional updates and structural improvements will continue rolling out through 2026, with a focus on enhancing messaging, navigation, and the overall user experience. Stay tuned for the official launch and more updates in the months ahead.
Global presence: virtual events, conferences, and community connections
Jakarta EE had a visible and impactful presence at face-to-face (F2F) conferences around the world, especially in the first half of the year. From Devnexus to JCON and beyond, Jakarta EE working group and community members presented talks, engaged with attendees at our sponsored booths, and built valuable relationships.
In 2025, JakartaOne Livestreams continued to grow with successful regional events in China and the annual JakartaOne Livestream, which attracted more than 6,000 viewers globally, with over 3,200 participants. With 20+ sessions, 15+ speakers, and 14+ hours of multilingual content, the JakartaOne Livestream series continued to drive strong community engagement across regions. Chinese JakartaOne Livestream recordings, as well as the annual JakartaOne Livestream recording, are available on our YouTube channel for anyone interested.
JakartaOne F2F Meetups further expanded the program’s regional footprint, with events in China and Japan drawing 170+ registered participants and 100+ in-person attendees, supported by high community approval and strong local participation.
With 17 Jakarta EE Tech Talks delivered in 2025, the program remains a vital channel for community learning, collaboration, and inspiration. Topics ranged from microservices and containers to security and observability. Recordings of these sessions are available on our YouTube channel.
Looking forward to 2026 and beyond
As we conclude an impactful 2025, it’s clear that Jakarta EE continues to strengthen its role as the open, vendor-neutral foundation for modern enterprise Java. The progress we’ve made this year, from delivering Jakarta EE 11 and introducing new specifications like Jakarta Agentic AI, to expanding our global events and deepening community engagement, reflects the dedication, collaboration, and passion of everyone involved.
2026 promises to be another exciting year of innovation and growth.
Thank you to all members, contributors, committers, and the wider community for your continued support. Together, we’re driving the platform forward and building a vibrant, open, and innovative ecosystem.
Here’s to another year of progress, collaboration, and innovation with Jakarta EE.
December 11, 2025
Book Review: Kotlin for Java Developers
December 11, 2025 12:00 AM

General information
- Pages: 414
- Published by: Packt
- Release date: October 2025
Disclaimer: I received this book as part of a collaboration with Packt
TL;DR
Essentially, this is a book that uses a "problem-reasoning-solution" approach to present the building blocks that make Kotlin interesting and different from Java. Hence, it isn't:
- A Kotlin reference book (i.e., it does not provide deep technical documentation)
- A book for learning how to program from scratch
In my opinion, it delivers what it promises.
About the book and how I read it
I work with both Java and Kotlin professionally. However, as a technical trainer I'm always looking for educational resources that can boost students' knowledge, either as a main reference or as a complementary resource. I think this book fits the latter category.
Right from the cover, the book states its value proposition:
Confidently transition from Java to Kotlin through hands-on examples and idiomatic Kotlin practices
I believe it achieves that, although at least in the first two chapters the writing style can make the book somewhat hard to read.
A rocket that takes time to launch but can reach Mars
The book is divided into four sections:
- Getting started with Kotlin
- Object-Oriented Programming
- Functional Programming
- Coroutines, Testing and DSLs
My least favorite section was the first, especially the first two chapters. The first chapter tries to give an overview of Kotlin versus Java, but it is too superficial and perhaps even unnecessary. I imagine the goal of this chapter is to spark interest in Kotlin, but it also anticipates that everything will be covered in more detail later. Personally, I almost skipped this chapter because I knew I would see the topics in more depth later. I suppose that's a matter of taste.
Then, the second chapter sketches out Maven and Gradle without going in depth, which felt redundant since the book is targeted at Java developers. I expected more detail in this section about which plugins are used in the build process, how they interact with Maven lifecycles, and other specific topics. But the book delegates this responsibility to the IDE wizard and that's it.
From chapter three onward something magical happens. The book finally launches and its value proposition starts to materialize. Starting in chapter three the writing style changes and consistently presents concept by concept. Almost every chapter is structured like this:
- A common problem is discussed, often respectfully from a Java perspective
- The Kotlin design decision is presented and how it aims to improve the problem
- A concise, self-contained Kotlin snippet explains the programming concept
This last part is what gives the book its value. Studying a programming language — especially when you already know how to program — is a different process than learning to program for the first time. This book recognizes that and discusses Kotlin's value propositions in technical terms, presenting self-contained snippets that readers can try in their IDE or download from the book's official repository.
If I were to use a rocket analogy, imagine that the following chapters are like Apollo 11 in full ascent from Cape Canaveral.
Part I
- Null and non-nullable types
- Extension Functions and the apply function
Part II
- Object-Oriented programming basics
- Generics and variance
- Data and sealed classes
Because this is not a reference book or official documentation, up to this point the book presents each concept well without diving into corner cases — which is fine. With practice, the book can be completed in about a week and provides a solid foundation for moving to the next level, whether that's Android development or Kotlin backend programming.
From Part III there is a noticeable shift: we leave the Java-centric atmosphere and enter idiomatic Kotlin territory. Java-only developers will likely notice this change, as we move into structures that are often too abstract to have direct equivalents in Java, including:
Part III - All this in the "Kotlin way"
- Basics of functional programming
- Lambdas
- Collections and sequences
Part IV
- Coroutines
- Synchronous and asynchronous programming
Finally, once we're in orbit the book presents two topics that are useful for day-to-day development but are not strictly part of the language:
- Kotlin testing
- Domain-specific languages (DSLs)
Things that could be improved
As with any review, this is the most difficult section to write. Besides the first two chapters, I noticed a few things that could cause confusion:
- The null safety chapter omits any mention of Java's
Optional - The coroutines section briefly mentions Virtual Threads but then presents Loom as a separate effort and likens it to Quasar (a library ecosystem). In reality, Virtual Threads are part of Project Loom
- The book inconsistently presents different JDK recommendations across chapters; sometimes it suggests Corretto while other times it simply suggests OpenJDK
- Also on the JVM side, most of the time it suggests Java 17. I imagine this was related to the time of writing. I can say that all samples worked just fine on Java 25 (the latest LTS at the time of this review), so you should be fine using that or Java 21 (officially supported by Kotlin compiler).
Most of these are not deal-breakers, this is still an enyojable book.
Who should read this book?
- Java developers exploring the Kotlin ecosystem, those interested in Android development, or developers considering switching to Kotlin as their primary language
December 01, 2025
The Darkside of AI: Risks and Realities – Talk at Voxxed Days Luxembourg 2025
by Alexius Dionysius Diakogiannis at December 01, 2025 01:11 PM
I’m excited to share the video recording of my talk, “The Darkside of AI: Risks and Realities,” presented at Voxxed Days Luxembourg 2025!
The rapid acceleration of Artificial Intelligence is transforming every aspect of our lives, from how we work and communicate to how we make critical decisions. While the headlines are often filled with the amazing potential and groundbreaking advancements, it’s crucial to pause and critically examine the inherent risks and complexities that come with such powerful technology.
Speaker: Alexius Dionysius Diakogiannis Event: Voxxed Days Luxembourg 2025 Room: AmigaOS
What the Talk Covers
This session went beyond the hype to explore the challenging realities that AI introduces. During the talk, we dove deep into several critical areas:
-
Bias and Fairness: How inherited biases in training data can lead to discriminatory and unfair outcomes, perpetuating societal inequalities.
-
The Ethics of Autonomy: The difficult questions surrounding liability and control as AI systems become more autonomous, especially in high-stakes fields like medicine and transportation.
-
Security Vulnerabilities: Exploring new attack vectors, such as adversarial examples, that can subtly trick AI models, and the risk of AI-driven misinformation campaigns (deepfakes).
-
Socio-economic Disruption: Analyzing the impact of mass automation on the job market and the imperative for proactive reskilling and policy-making.
by Alexius Dionysius Diakogiannis at December 01, 2025 01:11 PM
November 27, 2025

AI Glossary for Java Developers
by Thorben Janssen at November 27, 2025 01:36 PM
The post AI Glossary for Java Developers appeared first on Thorben Janssen.
AI introduces many new terms, acronyms, and techniques you must understand to build a good AI-based system. That makes it hard for many Java developers to learn how to integrate AI into their applications using SpringAI, Langchain4J, or some other library. I ran into the same issue when I started learning about AI. In this...
The post AI Glossary for Java Developers appeared first on Thorben Janssen.
November 26, 2025
Offset and Keyset Pagination with Spring Data JPA
by Thorben Janssen at November 26, 2025 01:20 PM
The post Offset and Keyset Pagination with Spring Data JPA appeared first on Thorben Janssen.
Pagination is a common and easy approach to ensure that huge result sets don’t slow down your application. The idea is simple. Instead of fetching the entire result set, you only fetch the subset you want to show in the UI or process in your business code. When doing that, you can choose between 2...
The post Offset and Keyset Pagination with Spring Data JPA appeared first on Thorben Janssen.
November 06, 2025

End of Life: Changes to Eclipse Jetty and CometD
by Jesse McConnell at November 06, 2025 03:36 PM
Webtide (https://webtide.com) is the company behind the open-source Jetty and CometD projects. Since 2006, Webtide has fully funded the Jetty and CometD projects through services and support, including migration assistance, production support, developer assistance, and CVE resolution.
First, the change.
Starting January 1, 2026, Webtide will no longer publish releases for Jetty 9, Jetty 10, and Jetty 11, as well as CometD 5, 6, and 7 to Maven Central or other public repositories.
Take a look at the primary announcement if you’re interested.
So, the motivation.
Why we are in this situation now harks back to the beginnings of Webtide. Briefly, Greg Wilkins founded the Jetty project in 1995 as part of a contest created by Sun Microsystems for a new language called Java. For a decade, he and Jan Bartel carefully stewarded the project as part of their consulting company Mort Bay Consulting. Around the Jetty 6 timeframe, in 2006, Webtide was founded as an LLC to evolve the project further commercially. Still, at its core, the goal was to support the incredible community that had developed over the years. When I joined in 2007, we began working to join the Eclipse Foundation. We took steps to formalize our development processes, aiming to add more commercial predictability to the open-source project. Joining the Eclipse Foundation also meant adhering to their rigorous IP policy for both the Jetty codebase and its dependencies, an essential step in improving corporate uptake.
This was also the time for the project to handle the end-of-life process for Jetty 6, while establishing Jetty 7 and Jetty 8. This was the opportunity that Webtide needed to support the project’s development by offering commercial services and support for EOL Jetty 6, while focusing on supporting and funding the future of Jetty 7 and Jetty 8.
It was the crux; after careful consideration, we decided that all commercial support releases would be open-source for the benefit of all. While not a traditional business decision, it aligned with our values and dedication to the community, which was rewarded as the community continued to grow its usage of Jetty.
This worked wonderfully for almost 20 years.
Something shifted…
We started to notice a shift in the community a few years ago. For almost 20 years, the companies we spoke with valued how our support could help them become more successful, with many ultimately becoming customers who truly understood the benefits of supporting open-source. Every single one of them saw the value in releasing EOL releases freely. When I became CEO a decade ago and Webtide became 100% developer-owned and operated, we were able to continue operating in this commercial environment with ease, to such an extent that the future of Webtide and the Jetty project is assured for many years to come.
So what changed? The tone of many companies we spoke to. Increasingly, while explaining the model that served Webtide well for so many years, where I used to hear ‘That makes so much sense, this works great!’, I now hear “So it’s just free? Great, I need to check a box.” Followed up with the galling question “Could you put this policy of yours in writing on your company letterhead?”.
And today?
Twenty years ago, things were different; Maven 2 dominance was emerging, and Maven Central was gaining ubiquity. Managing transitive dependencies was novel in many circles. Managing CVEs in a corporate setting was in its infancy, particularly with Java developer software stacks.
Now, build tooling is diverse, Maven Central is a global central repository system, and corporations should have their own caching repository servers, or they really should! Even JavaEE was rebranded as Jakarta at the Eclipse Foundation. So much change, but the one I’ll highlight is the emergence of business units focused on corporate software policies, complete with BOM files containing ever more metadata and checkboxes to click, managing CVE risks associated with software developed internally. Developers, the primary people Webtide has interacted with over the years, are increasingly far removed from software maintenance activities.
Now our approach to endlessly updating EOL releases seems remarkably outdated. Look at Jetty 9, which we have been releasing since 2013. It turns out our approach of making things as easy as possible for the community, for software that should have officially gone EOL years ago, was a benefit to many, but also enabled far more to grow complacent. Instead of scheduling migrations and updating to more recent versions, we inadvertently provided an environment that allowed companies to deploy onto software well over a decade old, when newer, more performant options were readily available. Then, when security postures started changing and businesses began looking deeper into their dependencies, they realized they were using outdated software, three or more major versions behind. Then, to our shock, many are perfectly fine with that so long as it is free and someone tells them it is ok.
If we have learned one thing within this time, it is that the EOL policy needs to be so much clearer, using established industry terminology. Looking back, we have been guilty of inventing terminology and inadvertently exacerbating the situation.
What is heartening is seeing other organizations work to address EOL as well; notably, MITRE has been developing changes to the CVE system to support EOL concepts fully. If you have ever seen the text “Unsupported When Assigned” in a CVE, then you have encountered the early efforts for EOL in a CVE.
You have to applaud the efforts of businesses to prioritize security and sane open-source policies.
However, this is also a call to open-source projects like Jetty, as we are operating in a different world. Everyone understands that ‘End-of-Life’ does not mean ‘End-of-Use’. Clearly, the system for many companies has changed from a Developer Support perspective to a Security Support perspective. EOL Software support is purchased differently now. There are companies, like Sonar (formerly Tidelift), that exist to manage security metadata about open-source software, enabling companies to manage their software risk more effectively.
EOL Jetty and CometD by Webtide
To address this industry evolution, Webtide has launched a partnership program that enables businesses relying on EOL Jetty and CometD versions to obtain CVE resolutions officially and predictably.
Webtide continues to resolve CVEs and issues for EOL Jetty and CometD in support of our commercial customers. However, the resulting binaries are now distributed directly to our commercial support customers and through our partnership network. No longer are we calling software EOL but deploying to Maven Central with a nod and a wink.
Our partners are established leaders in the open-source EOL landscape, creating products that directly address the problems the security and business industries are facing.
This synergy works perfectly with Webtide, as we are the company that offers services and support on Jetty and CometD. Migrations, developer assistance, production support, and performance are the things that directly influence the ongoing development of the open-source projects we steward. We can continue to focus on our strengths, and our partners can focus on theirs.
At last, the partners!
We are pleased to announce two partnerships. With these partners, you will be able to build a secure EOL solution for your software stack, not just for your usage of Jetty or CometD. Best yet, if you are interested in Webtide’s Lifecycle Support, you can use these partner versions in conjunction with our support!

TuxCare secures the open-source software the world builds on. Today, we protect over 1.2 million workloads – keeping them secure, compliant, and unstoppable at scale. From operating systems to development libraries and production applications, we power your open-source stack with enterprise-grade security and support, including endless lifecycle extensions for out-of-support software versions, rebootless patching for every major Linux distribution, enterprise-optimized support for community Linux, and our Linux-first vulnerability scanner that cuts through the noise.

HeroDevs provides secure, long-term maintenance for open-source frameworks that have reached End-of-Life. Through our Never-Ending Support (NES) initiative, we deliver continuous CVE remediation and compliance-grade updates, allowing your team to migrate at your own pace. Our engineers monitor upstream changes, backport verified fixes, and publish fully tested binaries for seamless drop-in replacement. With NES for Jetty and NES for CometD, you can stay secure, stable, and compliant—without refactoring or rushing a migration.
If your business is interested in our partner program, please direct inquiries to partnership@webtide.com.
Wrapping it up.
One important thing to note is that Webtide will continue to support the Jetty Project with a standard open-source release process, ensuring that older versions are released to provide the community with ample time to update to newer versions through a transition period. When Jetty 13 is released, Jetty 12.1 will continue to receive updates for a period, just as Jetty 12.0 does currently. If that is six months or a year, it remains to be seen. Once we finalize this release strategy with timelines, we will make sure the community is well-informed.
Fundamentally, the change coming is that the End of Life versions for Jetty and CometD will no longer be an empty EOL notice and quiet deployments to Maven Central. It will mean EOL and provide established industry solutions to address those who need additional support.
October 01, 2025
Key Highlights from the 2025 Jakarta EE Developer Survey Report
by Tatjana Obradovic at October 01, 2025 02:09 PM
The results are in! The State of Enterprise Java: 2025 Jakarta EE Developer Survey Report has just been released, offering the industry’s most comprehensive look at the state of enterprise Java. Now in its eighth year, the report captures the perspectives of more than 1700 developers, architects, and decision-makers, a 20% increase in participation compared to 2024.
The survey results give us insight into Jakarta EE’s role as the leading framework for building modern, cloud native Java applications. With the release of Jakarta EE 11, the community’s commitment to modernisation is clear, and adoption trends confirm its central role in shaping the future of enterprise Java. Here are a few of the major findings from this year’s report:
Jakarta EE Adoption Surpasses Spring
For the first time, more developers reported using Jakarta EE (58%) than Spring (56%). This clearly indicates growing awareness that Jakarta EE provides the foundation for popular frameworks like Spring. This milestone underscores Jakarta EE’s momentum and the community’s confidence in its role as the foundation for enterprise Java in the cloud era.
Rapid Uptake of Jakarta EE 11
Released earlier this year, Jakarta EE 11 has already been adopted by 18% of respondents. Thanks to its staged release model, with Core and Web Profiles first, followed by the full platform release, developers are migrating faster than ever from older versions.
Shifts in Java SE Versions
The community continues to embrace newer Java versions. Java 21 adoption leapt to 43%, up from 30% in 2024, while older versions like Java 8 and 17 declined. Interestingly, Java 11 showed a rebound at 37%, signaling that organisations continue to balance modernisation with stability.
Cloud Migration Strategies Evolve
While lift-and-shift (22%) remains the dominant approach, developers are increasingly exploring modernisation paths. Strategies include gradual migration with microservices (14%), modernising apps to leverage cloud-native features (14%), and full cloud-native builds (14%). At the same time, 20% remain uncertain, highlighting a need for clear guidance in this complex journey.
Community Priorities
Survey respondents reaffirmed priorities around cloud native readiness and faster specification adoption, while also emphasising innovation and strong alignment with Java SE.
Why This Matters
These findings highlight not only Jakarta EE’s accelerating momentum but also the vibrant role the community plays in steering its evolution. With enterprise Java powering mission-critical systems across industries, the insights from this survey provide a roadmap for organisations modernising their applications in an increasingly cloud native world.
A Call to the Community
The Jakarta EE Developer Survey continues to serve as a vital barometer of the ecosystem. With the Jakarta EE Working Group hard at work on the next release, including innovative features, there’s never been a better time to get involved. Whether you’re a developer, architect, or enterprise decision-maker, now is the perfect time to get involved:
- Explore the full report
- Join the Jakarta EE Working Group: Shape the platform’s future while engaging directly with the community.
- Contribute: Your feedback, participation, and innovations help Jakarta EE evolve faster.
With the Jakarta EE Working Group already preparing for the next release, including new cloud native capabilities, the momentum is undeniable. Together, we are building the future of enterprise Java.
May 17, 2025

Foundation Laid for Faster Text I/O
by Markus Karg at May 17, 2025 06:06 PM
Hey guys! How’s it going?
Another six months are over and you might wonder what the old shaggy prepared this time?  No wonder, it certainly is another OpenJDK contribution!
No wonder, it certainly is another OpenJDK contribution!  This time, it speeds up reading from
This time, it speeds up reading from CharSequence, and it will allow faster Write::append. 
Never heard of CharSequence? Well, it’s the common interface of String, StringBuilder, CharBuffer, and quite some custom classes out there. But wait! There are other text classes than String?  Maybe you never thought abot that…
Maybe you never thought abot that…  And why would you want to speed that up? Because a program never is fast enough, but more urgently, because it reduces power consumption! So, once more, we gain fun from faster apps, plus saving the climate.
And why would you want to speed that up? Because a program never is fast enough, but more urgently, because it reduces power consumption! So, once more, we gain fun from faster apps, plus saving the climate.  Ain’t that great? So read on!
Ain’t that great? So read on!
So for long time, you did not think about what happens “under the hood” when you concatenated Strings, like "abc" + "def". But then someone came and told you not to do “+” but use StringBuild::append, as that would be way faster (which it was). And then someone else came and told you, that this is an urban legend, as javac meanwhile does exactly that for you (which it does). But in fact, what happens still is that (directly or indirectly) memory is allocated which is the size of "abc" plus the size of "def" (even worse, it is not even stack memory but heap memory, but let’s put that aside for today). Actually, there is even more work done: As Strings are compressed internally, an compression algorithm chimes in. And yes, that needs time and memory, and energy, too.  Indeed there is even more going on internally, but more or less we could say: Concatinating
Indeed there is even more going on internally, but more or less we could say: Concatinating Strings is effectively making a compressed copy, then throwing away both original values, even in the Java 25 age. And “throwing away” means, leaving behind holes in the linear memory space. So besides pure Garbage Collection (“vacuuming”), we need memory defragmentation (“waste grinding”), which is another nice word for: moving even more bytes around in memory. And that costs even more time and power. And guess what: Your app concatenates Strings a lot, right? And guess what: The Java Runtime (JRE) itself internally concatenates even more Strings! So copy, reallocate, compress, deallocate, GC, defrag all the time. But for what? For nothing!  Sigh.
Sigh.
For nothing? Yes, for nothing. Because you could spare a lot of that – when further using StringBuilder instead of String. Ok, you know that since long time, so you do that, and so is javac (it replaces String+String by a StringBuilder “under good conditions”), and so is the JRE itself. But here comes the bad news: In the end, you, just like javac, just like the JRE itself, are calling toString() eventually. Don’t you? You do! And that means… right: Pointless power consumption, as toString() produces another temporary copy on the heap!
So why not omitting toString()? Just directly pass around your StringBuilder everywhere, instead of toString()’ing it! This spares lots of toString(). (cheer) So all is fine now? Nope. (cheer stops). Once you want to output your StringBuilder, or once you want to input text into a StringBuilder, you’re facing a problem: Your surrounding frameworks do not accept StringBuilder! Typically these all work with String, or, like in the case we’re talking about today (to finally come to the copic of today’s posting), they do accept CharSequence – but they internally toString() it. 
For example: Java’s Writer classes (you know, like good old BufferedWriter, PrintWriter, and all those) just pretend to accept not only Strings (like in write(String)), but also any other kind of CharSequence (like in append(myStringBuilder)). That looks just as what we want to spare that toString() heap clutter. But wait!  Take a look at the implementation first… it does… tada…
Take a look at the implementation first… it does… tada… toString()!  So that nice trick that
So that nice trick that javac internally uses a StringBuilder to implement “+” is good for nothing, as finally you end up with another time-squandering copy as soon as you output the result. 
But stopy crying! I am here to help!  The other day Oracle kindly adopted my latest OpenJDK contribution, and this finally paves the way to fix these troubles. To understand my solution, let’s dive deeper into
The other day Oracle kindly adopted my latest OpenJDK contribution, and this finally paves the way to fix these troubles. To understand my solution, let’s dive deeper into Writer, and why it does toString() on any CharSequence (even on Strings themselves). The cause is: Performance. Shocking!  If you copy text “char-by-char” this would be totally slow, as computers can pass around much larger clusters of information with a single command. So what
If you copy text “char-by-char” this would be totally slow, as computers can pass around much larger clusters of information with a single command. So what Writer::write internally does is, it asks the String to put all its characters into a char array with a single command (which ontop is lightning-fast machine code  ). That command is
). That command is String::getChars(int, int, char[], int). So why doing that only with Strings, but not with other CharSequences? Because CharSequence does not have that command. It’s as embarrasing as that! CharSequence only can be asked for one character at a time, so you need a loop in Java – which means, in 99% of you cases, an interpreted loop (unless you do it 10.000 times to get it hot spotted eventually). And that is not just slow, it is even super-slow! 
So what I did is that I added that exact getChars(int, int, char[], int) method signature that String always had to the CharSequence interface. Sounds easy, but took six months of discussions and a lot of convincing (for example, I had to proof that “not many” code exists on earth that already has such a method but that method does something else – as that code would silently do the wrong thing once executed on Java 25). This foundational change is now found in Java 25, and if you download a pre-release build, you can play with it right now – or already prepare your application if it does a “char-by-char” loop or temporary toString() currently.
So what about Writer? I’m working on it. Just today I filed the first of a set of pull requests towards getting this new method used in all Writers in OpenJDK. So while nothing will get faster “magically” in JDK 25, the foundation is laid, and by the time, eventually your code runs more efficient, without recompiling it. So… stay tuned…! 
May 16, 2025

Building AI Assistant Application in Java
by dmitrykornilov at May 16, 2025 12:57 PM

In my previous article, I discussed how Helidon integrates with LangChain4J. While the article provided a solid foundation, some readers pointed out the lack of a complete, hands-on example. This time, we’ll fix that by building a fully functional, practical AI-powered Java application.
We’ll create the Helidon Assistant — a chatbot with a web UI trained to answer questions about the Helidon framework. By “trained,” I mean it will be capable of answering questions based on the full Helidon documentation.

In this article, we’ll explore how to preprocess AsciiDoc files for ingestion into an embedding store and how to make the application stateless using an AI-powered summarization mechanism. Let’s dive in!
The Project Overview
The Helidon Assistant is built with the following technologies:
- Java 21
- Helidon SE 4 as the runtime
- LangChain4J for AI integration
- In-memory Embedding Store for storing and retrieving document embeddings
- OpenAI GPT-4o as the default chat model
- Helidon SE static content feature for serving the web UI
- Bulma CSS framework for clean and minimalistic UI styling
The application is organized into three main layers:
- RESTful Service Layer – defines the public REST API and serves the web UI.
- AI Services Layer – defines LangChain4J AI services: one for answering user questions, and another for summarizing the conversation.
- RAG Layer – handles ingestion: reading AsciiDoc files, preprocessing content, creating embeddings, and storing them in the embedding store.
The architecture diagram is shown below:

Building and Running the Project
The project is available on GitHub here. You can either clone the repository or browse the sources directly on GitHub. I’ll refer to it throughout the article.
Before building and running the project, you need to configure the path to the AsciiDoc documentation the assistant will work with. If you already have the documentation locally—great! If not, you can clone the Helidon repository from GitHub:
git clone https://github.com/helidon-io/helidon.git
The documentation files are located in docs/src/main/asciidoc/mp.
Next, update the application configuration file located at src/main/resources/application.yaml with the path to your AsciiDoc files:
app:
root: "//home/dmitry/github/helidon/docs/src/main/asciidoc/mp"
inclusions: "*.adoc"
Make sure to adjust the root path to match your local environment. You can also use the inclusions and exclusions properties to filter which files under the root directory should be included during ingestion.
Now you’re ready to build the application:
mvn clean package
And launch it:
java -jar target/helidon-assistant.jar
Once running, open your browser and go to http://localhost:8080. You’ll be greeted with the assistant’s web interface, where you can start asking questions.
Here are a few example questions to get you started:
- How to use metrics with Helidon?
- What does the
@Retryannotation do? - How can I configure a web server?
- How can I connect to a database?
In the next section, we’ll take a closer look at the build script and project dependencies.
Dependencies
The project uses a standard Maven pom.xml configuration recommended for Helidon SE applications, with several additional dependencies specific to this use case. Below is a commented snippet explaining the purpose of each dependency:
<dependencies>
<!-- Helidon integration with LangChain4J -->
<dependency>
<groupId>io.helidon.integrations.langchain4j</groupId>
<artifactId>helidon-integrations-langchain4j</artifactId>
</dependency>
<!-- OpenAI provider: required for using the GPT-4o chat model.
Replace this with another provider if using a different LLM. -->
<dependency>
<groupId>io.helidon.integrations.langchain4j.providers</groupId>
<artifactId>helidon-integrations-langchain4j-providers-open-ai</artifactId>
</dependency>
<!-- LangChain4J embeddings model used for RAG functionality -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embeddings-all-minilm-l6-v2</artifactId>
</dependency>
<!-- AsciidoctorJ: used to parse and process AsciiDoc documentation files -->
<dependency>
<groupId>org.asciidoctor</groupId>
<artifactId>asciidoctorj</artifactId>
<version>${version.lib.asciidoctorj}</version>
</dependency>
<!-- Various Helidon dependencies needed for the application proper
functionality -->
<dependency>
<groupId>io.helidon.webserver</groupId>
<artifactId>helidon-webserver</artifactId>
</dependency>
<dependency>
<groupId>io.helidon.webserver</groupId>
<artifactId>helidon-webserver-static-content</artifactId>
</dependency>
<dependency>
<groupId>io.helidon.http.media</groupId>
<artifactId>helidon-http-media-jsonp</artifactId>
</dependency>
<dependency>
<groupId>io.helidon.config</groupId>
<artifactId>helidon-config-yaml</artifactId>
</dependency>
<!-- Logging -->
<dependency>
<groupId>io.helidon.logging</groupId>
<artifactId>helidon-logging-jul</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-jdk14</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
You can use these dependencies for other AI-powered projects with minimal changes.
Application main class
The ApplicationMain class serves as the application’s entry point. It contains the main method, which performs the following steps:
- Enables runtime logging.
- Loads the application configuration.
- Ingests documentation into the embedding store.
- Sets up web server routing to serve static web pages and handle user requests.
- Starts the web server.
Below is a snippet of the main method:
public static void main(String[] args) {
// Make sure logging is enabled as the first thing
LogConfig.configureRuntime();
var config = Services.get(Config.class);
// Initialize embedding store
Services.get(DocsIngestor.class)
.ingest();
// Static content setup
var staticContentFeature = StaticContentFeature.builder()
.addClasspath(cl -> cl.location("WEB")
.context("/ui")
.welcome("index.html"))
.build();
// Initialize and start web server
WebServerConfig.builder()
.addFeature(staticContentFeature)
.config(config.get("server"))
.routing(ApplicationMain::routing)
.build()
.start();
}
In the next section, I’ll explain how the embedding store is created and initialized.
Preparing AsciiDoc Files for Embeddings
Although AsciiDoc is lightweight and human-readable, the source content isn’t immediately ready for use in AI-powered retrieval. AsciiDoc files often contain structural directives like include statements, developer comments, attribute substitutions, and variables intended for conditional rendering or reuse. These elements are meaningful for human readers or documentation generators but can confuse or mislead a language model if left unprocessed. Additionally, formatting artifacts and metadata can introduce noise. Without proper preprocessing, the resulting embeddings might be irrelevant or misleading, which degrades the quality and accuracy of the assistant’s responses.
To address this, we apply a structured preprocessing pipeline.
- AsciiDocJ Integration: We use the official AsciiDocJ parser to fully parse AsciiDoc documents. This library resolves include directives automatically and gives us a structured representation of the content.
- Section-Based Chunking: We group content elements by their surrounding section and generate one embedding per section. This preserves logical and thematic boundaries and helps ensure responses remain relevant.
- Preserve Atomic Elements: We make sure that tables and code snippets are not split across chunks. This is critical to retain the contextual meaning of examples and structured content.
- Attach Metadata: Each chunk is enriched with metadata such as document title, relative file path, and section index. This helps reconstruct the document context when presenting answers.
- Repeat for Each File: This process is repeated for each .adoc file identified by the inclusion pattern in the configuration.
This preprocessing ensures that the AI retrieves precise, coherent documentation segments in response to user queries, resulting in more accurate and helpful answers.
Here’s how the implementation is structured:
- AsciiDocPreprocessor.java parses the file and produces a list of document chunks.
- ChunkGrouper.java groups chunks into section-based logical units.
- FileLister.java reads the directory path and applies inclusion/exclusion patterns.
- DocsIngestor.java orchestrates the overall process: listing files, extracting and grouping chunks, converting them to TextSegment objects, and storing the resulting embeddings.
A simplified snippet from DocsIngestor.java demonstrates the ingestion logic:
public void ingest() {
var files = FileLister.listFiles(root, exclusions, inclusions);
var processor = new AsciiDocPreprocessor();
var grouper = new ChunkGrouper(1000);
for (Path path : files) {
var chunks = processor.extractChunks(path.toFile());
var groupedChunks = grouper.groupChunks(chunks);
List<TextSegment> segments = new ArrayList<>();
for (int i = 0; i < groupedChunks.size(); i++) {
var chunk = groupedChunks.get(i);
var metadata = new Metadata()
.put("source", path.toFile().getAbsolutePath())
.put("chunk", String.valueOf(i + 1))
.put("type", chunk.type().name())
.put("section", chunk.sectionPath());
segments.add(TextSegment.from(chunk.text(), metadata));
}
var embeddings = embeddingModel.embedAll(segments);
embeddingStore.addAll(embeddings.content(), segments);
}
}
Serving static web pages
The UI consists of a single index.html file located in the resources/WEB directory. It’s styled using the Bulma CSS framework, which is designed to be JavaScript free.
But there is a small piece of the JavaScript code anyway. It sends user messages to the backend when the Send button is clicked, updates the chat window with the response, and manages conversation summary state.
To serve this page, we register a StaticContentFeature during the web server startup. The code below demonstrated how it’s done in the main method.
// Static content setup
var staticContentFeature = StaticContentFeature.builder()
.addClasspath(cl -> cl.location("WEB")
.context("/ui")
.welcome("index.html"))
.build();
// Initialize and start web server
WebServerConfig.builder()
.addFeature(staticContentFeature)
...
/ui path is registered to serve the static content. It user tries to open another path, he will be redirected to /ui. It’s done in the routing method.
static void routing(HttpRouting.Builder routing) {
routing.any("/", (req, res) -> {
// showing the capability to run on any path, and redirecting from root
res.status(Status.MOVED_PERMANENTLY_301);
res.headers().set(UI_REDIRECT);
res.send();
})
.register("/chat", Services.get(ChatBotService.class));
}
Processing user requests
When the user clicks the Send button in the UI, a server call to the /chat endpoint is initiated. This request sends the user’s message along with a conversation summary to the server. We’ll discuss conversation summaries in a later section—let’s first focus on how the request is processed on the server side.
User requests to /chat are handled by the ChatBotService.java class. This class is registered during web server initialization, as shown in ApplicationMain.java. Below is a simplified snippet that demonstrates how it’s done:
static void routing(HttpRouting.Builder routing) {
routing.register("/chat", Services.get(ChatBotService.class));
...
}
The ChatBotService class contains the chatWithAssistant method, which handles incoming requests. It performs the following steps:
- Extracts the user’s message and conversation summary from the request.
- Invokes
ChatAiService, passing the message and summary to generate a response. - Uses
SummaryAiServiceto create an updated conversation summary. - Builds a JSON object containing the response and the updated summary, and sends it back to the client.
Here’s the simplified code for the chatWithAssistant method:
private void chatWithAssistant(ServerRequest req, ServerResponse res) {
var json = req.content().as(JsonObject.class);
var message = json.getString("message");
var summary = json.getString("summary");
var answer = chatAiService.chat(message, summary);
var updatedSummary = summaryAiService.chat(summary, message, answer);
var returnObject = JSON.createObjectBuilder()
.add("message", answer)
.add("summary", updatedSummary)
.build();
res.send(returnObject);
}
The ChatAiService.java class is implemented as a Helidon AI service. You can learn more about AI services and how to implement them in my previous article.
Here’s the relevant code:
@Ai.Service
public interface ChatAiService {
@SystemMessage("""
You are Frank, a helpful Helidon expert.
Only answer questions related to Helidon and its components. If a question is not relevant to Helidon,
politely decline.
Use the following conversation summary to keep context and maintain continuity:
{(summary})
""")
String chat(@UserMessage String question, @V("summary") String previousConversationSummary);
}
Making the Application Stateless
In a typical chat application, the backend must maintain the full history of the conversation in order to understand the user’s intent. This is because language models like OpenAI’s GPT rely heavily on context — they need to see the dialogue leading up to the current question to provide an accurate and helpful answer. The longer and more complex the conversation, the more memory is required to hold that context.
However, storing chat history introduces challenges. If you’re running a single backend instance, you might store this state in memory. But in a production environment, especially in cloud-native deployments, applications often scale horizontally — meaning multiple instances of the backend may be running behind a load balancer. In such setups, traditional in-memory storage for chat history doesn’t work: the next request from the same user might be routed to a different backend instance that has no access to prior state.
This is where statelessness becomes critical. Stateless services are inherently scalable, easier to maintain, and more resilient. But to make a chatbot stateless without sacrificing conversation quality, we need a way to preserve and compress context — and that’s where AI-powered summarization comes in.
By summarizing the chat history into a compact form after every message, we replace a long list of messages with a lightweight, synthetic memory that still captures the user’s intent and context. This summary is sent along with the next message, enabling consistent, relevant responses while allowing each request to be handled independently.
The Helidon Assistant uses this technique to remain stateless and cloud-native, ensuring it can scale easily while maintaining meaningful conversations with users.
Summarizer implemented as an AI service. You can read more about AI services and how to implement them in my previous article.
@Ai.Service
public interface SummaryAiService {
@SystemMessage("""
You are a conversation summarizer for an AI assistant. Your job is to keep a concise summary of the
ongoing conversation to preserve context.
Given the previous summary, the latest user message, and the AI's response, update the summary so it
reflects the current state of the conversation.
Keep it short, factual, and focused on what the user is doing or trying to achieve. Avoid rephrasing the
entire response or repeating long parts verbatim.
""")
@UserMessage("""
Previous Summary:
{{summary}}
Last User Message:
{{lastUserMessage}}
Last AI Response:
{{aiResponse}}
"""
)
String chat(@V("summary") String previousSummary,
@V("lastUserMessage") String latestUserMessage,
@V("aiResponse") String aiResponse);
}
Wrapping Up
That’s it — we’ve built a fully working, stateless AI assistant powered by Helidon and LangChain4J. Hopefully, everything is clear and nothing important was left out. But if something feels confusing or needs more explanation, I’d love to hear your thoughts. Feedback is always welcome — whether it’s a bug, a missing step, or just a better way to do things.
Want to dive into the code or try it yourself? You’ll find everything here:
Thanks for reading — and happy coding!
March 13, 2025
Developing AI-Powered Applications with Helidon and LangChain4J
by dmitrykornilov at March 13, 2025 01:33 PM

Introduction
The rise of Large Language Models (LLMs) has opened new doors for AI-powered applications, enabling dynamic interactions, natural language processing, and retrieval-augmented generation (RAG). However, integrating these powerful models into Java applications can be challenging. This is where LangChain4J comes in – a framework designed to simplify AI development in Java.
To take things a step further, in version 4.2, Helidon introduced seamless LangChain4J integration, making it easier to build AI-driven applications while leveraging Helidon’s programming model and style. In this blog post, we’ll explore how this integration simplifies AI application development and how you can use it in your projects.
What is LangChain4J?
LangChain4J is a Java framework that facilitates building AI-powered applications using LLMs from providers like OpenAI, Cohere, Hugging Face, and others. It provides:
- AI Services: A declarative and type-safe API to interact with models.
- Retrieval-Augmented Generation (RAG): Enhancing responses with external knowledge sources.
- Embeddings and Knowledge Retrieval: Working with vector-based search systems.
- Memory and Context: Managing conversational memory for intelligent interactions.
However, integrating LangChain4J manually into an application requires configuring components, managing dependencies, and handling injections manually. This is where Helidon’s integration module provides significant advantages.
How Helidon Simplifies LangChain4J Integration
Before we proceed, note that Helidon’s LangChain4J integration is a preview feature in Helidon 4.2. This means that while it’s production-ready, the Helidon team reserves the right to modify APIs in minor versions.
Helidon’s LangChain4J integration introduces:
- Helidon Inject Support: LangChain4J components are automatically created and registered in the Helidon service registry based on configuration.
- Convention Over Configuration: Reduces boilerplate by using sensible defaults.
- Declarative AI Services: Uses annotations to define AI services in a clean, structured manner.
- CDI Integration: Components work seamlessly in Helidon MP.
These features significantly reduce the complexity of incorporating AI into Helidon applications.
Setting Up LangChain4J in Helidon
To use LangChain4J with Helidon, add the following dependency to your Maven project:
<dependency>
<groupId>io.helidon.integrations.langchain4j</groupId>
<artifactId>helidon-integrations-langchain4j</artifactId>
</dependency>
Include the necessary annotation processors in the <build><plugins> section of your pom.xml:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<annotationProcessorPaths>
<path>
<groupId>io.helidon.codegen</groupId>
<artifactId>helidon-codegen-apt</artifactId>
</path>
<path>
<groupId>io.helidon.integrations.langchain4j</groupId>
<artifactId>helidon-integrations-langchain4j-codegen</artifactId>
</path>
</annotationProcessorPaths>
</configuration>
</plugin>
Using different LLM providers may require additional dependencies. For example, using OpenAI models requires adding a dependency to the OpenAI provider, while using Ollama requires adding the Ollama provider. This modular approach helps keep applications lightweight. For more information about providers and dependencies, refer to the documentation.
Creating AI Components in Helidon
When I refer to AI components, I mean the public API classes provided by LangChain4J. Examples include various models such as OpenAiChatModel and OllamaChatModel, embedding stores like InMemoryEmbeddingStore, content retrievers such as EmbeddingStoreContentRetriever, and ingestors like EmbeddingStoreIngestor, among others.
Some components are natively supported by the Helidon LangChain4J integration and can be automatically created when the corresponding configuration is present. The currently supported components include:
- LangChain4J Core
- EmbeddingStoreContentRetriever
- MessageWindowChatMemory
- Open AI
- OpenAiChatModel
- OpenAiStreamingChatModel
- OpenAiEmbeddingModel
- OpenAiImageModel
- OpenAiLanguageModel
- OpenAiModerationModel
- Ollama
- OllamaChatModel
- OllamaStreamingChatModel
- OllamaEmbeddingModel
- OllamaLanguageModel
- Cohere
- CohereEmbeddingModel
- CohereScoringModel
- Oracle
- OracleEmbeddingStore
For example, the OpenAI chat model can be automatically created by defining the following configuration in application.yaml:
langchain4j:
open-ai:
chat-model:
enabled: true
api-key: "demo"
model-name: "gpt-4o-mini"
With this configuration, an instance of OpenAiChatModel is automatically created and can be injected into other application components.
A key element in this setup is the enabled property. The component is only created if this property is set to true. This provides an easy way to disable component creation while retaining its configuration in the file for future use.
If you need to create a component that is not in the list above and register it in the Helidon service registry, you can use a Supplier Factory:
@Service.Singleton
@Service.Named("MyChatModel")
class ChatModelFactory implements Supplier<ChatLanguageModel> {
@Override
public ChatLanguageModel get() {
return OpenAiChatModel.builder()
.apiKey("demo")
.build();
}
}
This method allows you to register custom embedding models and other AI components dynamically. Service.Named("MyChatModel") annotation is optional. You can add it to define a name for your component for future reference.
Using AI Components
Helidon Inject makes it easy to use AI components within your application:
@Service.Singleton
public class MyService {
private final ChatLanguageModel chatModel;
@Service.Inject
public MyService(ChatLanguageModel chatModel) {
this.chatModel = chatModel;
}
}
For named components, use:
@Service.Inject
public MyService(@Service.Named("MyChatModel") ChatLanguageModel chatModel) {
this.chatModel = chatModel;
}
Alternatively, you can manually retrieve a component from the service registry as follows:
var chatModel = Services.get(OpenAiChatModel.class);
AI Services
Most often AI-powered components require a combination of different components working together. For example, a simple chat assistant requires a chat model to communicate with users, embedding store to store data, embedding model to retrieve and query the data, chat memory for keeping conversation context, etc. LangChain4J AI Services provide a way of combining different kinds of AI functionality behind a simple API which significantly reduces the boilerplate code.
Helidon’s LangChain4J integration introduces a declarative Helidon Inject-based approach for creating AI Services. It supports the following components:
- Chat Model:
dev.langchain4j.model.chat.ChatLanguageModel
- Streaming Chat Model:
dev.langchain4j.model.chat.StreamingChatLanguageModel
- Chat Memory:
dev.langchain4j.memory.ChatMemory
- Chat Memory Provider:
dev.langchain4j.memory.chat.ChatMemoryProvider
- Moderation Model:
dev.langchain4j.model.moderation.ModerationModel
- RAG:
- Content Retriever:
dev.langchain4j.rag.content.retriever.ContentRetriever - Retrieval Augmentor:
dev.langchain4j.rag.RetrievalAugmentor
- Content Retriever:
- Callback Functions:
- Methods annotated with
dev.langchain4j.agent.tool.Tool
- Methods annotated with
Helidon makes it simple to define AI services using annotations:
@Ai.Service
public interface ChatAiService {
String chat(String question);
}
In this scenario all LangChain4J components from the list above are taken from the service registry. User still has an ability to manually control the process by putting any of the following annotations which specify a service name which must be used for this particular function instead of discovering it automatically.
| Annotation | Description |
|---|---|
| Ai.ChatModel | Specifies the name of a service in the service registry that implements ChatModel to be used in the annotated AI Service. Mutually exclusive with Ai.StreamingChatModel. |
| Ai.StreamingChatModel | Specifies the name of a service in the service registry that implements StreamingChatModel to use in the annotated Ai Service. Mutually exclusive with Ai.ChatModel. |
| Ai.ChatMemory | Specifies the name of a service in the service registry that implements ChatMemory to use in the annotated Ai Service. Mutually exclusive with Ai.ChatMemoryWindow and Ai.ChatMemoryProvider. |
| Ai.ChatMemoryWindow | Adds a MessageWindowChatModel with the specified window size to the annotated AI Service. Mutually exclusive with Ai.ChatMemory and Ai.ChatMemoryProvider. |
| Ai.ChatMemoryProvider | Specifies the name of a service in the service registry that implements ChatMemoryProvider to use in the annotated Ai Service. Mutually exclusive with Ai.ChatMemory and Ai.ChatMemoryWindow. |
| Ai.ModerationModel | Specifies the name of a service in the service registry that implements ModerationModel to use in the annotated Ai Service. |
| Ai.ContentRetriever | Specifies the name of a service in the service registry that implements ContentRetriever to use in the annotated Ai Service. Mutually exclusive with Ai.RetrievalAugmentor. |
| Ai.RetrievalAugmentor | Specifies the name of a service in the service registry that implements RetrievalAugmentor to use in the annotated Ai Service. Mutually exclusive with Ai.ContentRetriever. |
For example, in the snippet below a service with name “MyChatModel” will be used as chat model and all other components are discovered automatically.
@Ai.Service
@Ai.ChatModel("MyChatModel")
public interface ChatAiService {
String chat(String question);
}
There is a possibility to switch off automatic discovery by using @Ai.Service(autodicovery=false). In this case the service components are not discovered automatically and users must add components manually using annotations specified above. @ChatModel or @StreamingChatModel annotations are required.
Tools: Enhancing AI with Custom Logic
LangChain4J tools enable AI models to invoke external functions during execution. This is useful when an LLM needs to perform an action during its conversation with a user, such as retrieving data, calling an external service, or executing code.
LangChain4J provides the @Tool annotation, which, when applied to a method, makes that method accessible for the LLM to call. The integration code scans the project for classes containing @Tool-annotated methods and automatically adds them to AI Services. The only requirement is that these classes must be Helidon Inject services.
@Service.Singleton
public class OrderService {
@Tool("Get order details for specified order number")
public Order getOrderDetails(String orderNumber) {
// Business logic here
}
}
If you are using Helidon MP, an additional step is required. You must annotate the service containing tools with the @Ai.Tool annotation. Additionally, the integration supports tools within CDI beans.
Samples
We have created several sample applications for you to explore. These samples demonstrate all aspects of using LangChain4J in Helidon applications.
Coffee Shop Assistant
The Coffee Shop Assistant is a demo application that showcases how to build an AI-powered assistant for a coffee shop. This assistant can answer questions about the menu, provide recommendations, and create orders. It utilizes an embedding store initialized from a JSON file.
Key features:
- Integration with OpenAI chat models
- Utilization of embedding models, an embedding store, an ingestor, and a content retriever
- Helidon Inject for dependency injection
- Embedding store initialization from a JSON file
- Support for callback functions to enhance interactions
Check it out:
Hands-on Lab
We also offer a Hands-on Lab with step-by-step instructions on how to build the Coffee Shop Assistant:
Useful Resources
Ready to get started? Here are some useful resources:
March 03, 2025

Jakarta EE Ambassadors Gather at Devnexus 2025 to Deliver Sessions on Jakarta EE
by mpredli01 at March 03, 2025 04:54 PM
Devnexus 2025 will be held Tuesday-Thursday, March 4-6, 2025 at the Georgia World Congress Center in Atlanta, Georgia. Members of the Jakarta EE Ambassadors will be in attendance to deliver presentations on Jakarta EE.
On March 4, developers will be able to choose from five workshops:
AI-Driven Development: Enhancing Java with the latest AI Innovations by Brian Benz
Developer to Architect by Nate Schutta
Migration Engineering with OpenRewrite: The Recipe for Success by Jonathan Schneider
Practical AI Lab for Enterprise Java Developers: From Zero to Hero by Daniel Oh, Eric Deandrea and James Falkner
Stream Processing As You’ve Never Seen Before (Seriously): Apache Flink for Java Developers by Viktor Gamov and Sandon Jacobs
Concurrent with the workshops are two summits for Java User Group leaders and Java Champions as they discuss issues that affect their respective Java User Groups and the roles of a Java Champion within the Java community.
On March 5-6, developers can expect many sessions on topics such as, AI, Architecture, Jakarta EE and Core Java (among many others).
The Jakarta EE track, in particular, includes 10 sessions, namely:
A Developer’s Guide to Jakarta EE 11 by Michael Redlich
AI Tools for Jakarta EE by Gaurav Gupta
Foundations of Modern Java Server Apps by Kito Mann
Java + LLMs: A hands-on guide to building LLM Apps in Java with JakartaEE by Bazlur Rahman and Shaaf Syed
Migrating from Java EE – to Spring Boot or something else? by Ondro Mihályi
Jakarta EE meets AI: Beyond the chatbot with LangChain4j by Jorge CajasDuke on CRaC with Jakarta EE by Ivar Grimstad and Rustam Mehmandarov
Concurrency redefined: what’s new in Jakarta Concurrency 3.1 by Chuck Bridgham and Harry Hoots III
Jakarta EE: Connected Industries with an Edge by Petr Aubrecht
Case Study: Journey to Cloud with Jakarta EE and MicroProfile by Julian Ortiz
Developers can also expect keynote addresses throughout the conference and peruse the vendors that will display their wares. The Eclipse Foundation will also have a booth where folks from the Java community involved in Jakarta EE and MicroProfile will be on hand for conversation and for example applications that demonstrate new features offered in Jakarta EE 11.
November 02, 2024
Reader.of(CharSequence)
by Markus Karg at November 02, 2024 01:21 PM
Hi guys, how’s it going? Long time no see!
In fact, I had been very silent in the past months, and as you could imagine, it has a reason: I just had no time to share all the great stuff with you that I was involved with recently. In particular, creating video content for Youtube is such time-consuming that I decided to stop with that by end of 2023, at least “for some time”, until my personal stress level is “normalized” again. Unfortunately, now by end of 2024, it still is at 250%… Anyways!
Having said that, I decided to restart my blog. While many people told me that blogging is @depreceated since the invention of VLogs, I need to say, it is just so much easier for me to write a blog article, that I decided to ignore them and write some lines about my latest Open Source contribution. So here it is: My first blog entry in years!
But enough about me. What I actually wanted to tell you today is that I am totally happy these days. The reason is that since this week, JDK 24 EA b22 is available for download, and as you can see in the preliminary JavaDocs, my very first addition to the official Java API is contained: Reader.of(CharSequence)  !
!
You might wonder what’s so crazy about that, because (as you certainly know) I am a contributor to OpenJDK since many years. Well, yes, I did contribute to OpenJDK (alias “to Java”) for long time, but all my contributions where just “under the hood”. I have optimized execution performance, I improved JavaDocs, I added unit tests, and I refactored code. But this time, I added a complete new feature to the public API. It really feels so amazing to see that my work of the past few weeks now will help Java developers in their future projects to spare some microseconds and some kilobytes per call, and in sum, those approx. ten million developers (according to Oracle marketing) will sum up to considerable amounts of CO2 that my invention will spare! 

Okay, so what actually is Reader.of(CharSequence) all about, how can you use it, and how does it spare resources?
I think you all know what the class StringReader is, and what to use it for: You need (for whatever reason) an implementation of the Reader interface, and the source is a String. At least that what it was made for decades ago. In fact, looking at the actual uses in 2024, more often than not the source isn’t a String actually, but is (mostly for performance reasons) a StringBuilder or StringBuffer, and sometimes (mostly for technical reasons) a CharBuffer. These classes all share one common interface, CharSequence, which is “the” interface of the class String, too. Unfortunately, StringReader is unable to accept CharSequence; it only accepts String. That’s too bad, because it means, most uses of StringReader actually perform an intermediate toString() operation, which creates a temporary copy of the full content on the heap – just to throw it away later!  Creating this copy is anything but free! It imposes time to search a free place on the heap, to copy the content onto the heap, and to lateron GC (dispose and defragment) the otherwise unused copy in turn. Time is not just money – This operation costs power, and power costs (even these days) CO2!
Creating this copy is anything but free! It imposes time to search a free place on the heap, to copy the content onto the heap, and to lateron GC (dispose and defragment) the otherwise unused copy in turn. Time is not just money – This operation costs power, and power costs (even these days) CO2! 
Ontop of that, most (possibly all) uses of StringReader are single-threaded. I investigated for some time but could find not a single reason for accessing a StringReader in a multi-threaded fashion. Unfortunately, StringReader is thread-safe: It internally uses the synchronized keyword in every single method. Each time. For each single read in possibly a loop of thousand iterations! And yes, you guess right: synchronized a everything by fast. It slows down code considerably, for zero benefit! And: No, the JVM has no a trick to speed this up in the single-threaded use cases – that trick (“Biased Locking”) went away years ago and the result is that synchronized is slow again!
Imagine you are writing a RESTful web server which returns JSON on GET. JSON is nothing else but a character sequence. You build it from a non-trivial algorithm using a StringBuilder. That particular JSON unfortunately is non-cachable, as it contains information sent with the request or changing over time or provided by the real physical world. So the server possibly produces tens of thousands of StringBuilders per second and reads it using a StringReader. Could you imagine what happens to your performance? Thanks to the combination of both effects described earlier, you’re losing money with every other customer contacting your server. YOUR money, BTW.
This is exactly what happend in my latest commercial project, so I tried to get rid of StringReader. My first idea was to use Apache IO’s CharSequenceReader, which looks a bit old-school, but immediately got me rid of both effects instantly! The problem with Apache IO is that it is rather huge. Using lots of KBs of transitive dependencies just for one single use case didn’t sound like a smart option (but yes, this is the code actually in production still – at least unless JDK 24 is published in Q1/25). Also, the customer was not very pleased to adopt another third-party library into the game. And finally, the code of Apache IO is not really eagerly maintained; they do bug fixes, but they abstain from using modern Java APIs (not even using multi-release JARs). Some will hate me for writing this, but the actual change rate didn’t look like “stable”, it looked to “dead” – agreed, this is subject to my personal interpretation. 
Being an enthusiastic Open Source committer since decades, and being an OpenJDK contributor since years, I had the idea to tackle the problem at its root: StringReader. So I proposed to provide a PR for a new public API, which was very much appreciated by the OpenJDK team. It was Alan Bateman himself (Group Lead of JDK Core Libraries) who came up with the proposal to have a static factory, which culminated in me posting a PR on Github about adding Reader.of(CharSequence). After accepting the mandatory CSR it recently got merged, and since JDK 24’s Eary Access Build 22 it is publicly available.
BTW, look at the implementation of that Reader’s bulk-read method. There is an ugly sequence of tricks to speed up performance. I will address this in a subsequent upcoming PR. Stay tuned!
So if you want to gain the performance benefit, here is what you need to do:
- Run your app on Java 24 EA b22+.
- Replace all occurances of
new StringReader(x)andnew CharSequenceReader(x)byReader.of(x). - If
xends with.toString()then remove that trailing.toString()– unless the left side ofxis effectively not aCharSequence. - Note: If you actually use multiple threads to access the
Reader, don’t stick withStringReader, but simply surround your calls by a modern means of synchronization, like a Lock – locks are faster thansynchronized.
Please exterminate StringReader but adopt Reader.of() ASAP!
I would be happy if you could report the results. Just leave a comment!
So far for today! PARTY ON! 
May 16, 2024
Back to the Future with Cross-Context Dispatch
by gregw at May 16, 2024 01:31 AM
Cross-Context Dispatch reintroduced to Jetty-12
With the release of Jetty 12.0.8, we’re excited to announce the (re)implementation of a somewhat maligned and deprecated feature: Cross-Context Dispatch. This feature, while having been part of the Servlet specification for many years, has seen varied levels of use and support. Its re-introduction in Jetty 12.0.8, however, marks a significant step forward in our commitment to supporting the diverse needs of our users, especially those with complex legacy and modern web applications.
Understanding Cross-Context Dispatch
Cross-Context Dispatch allows a web application to forward requests to or include responses from another web application within the same Jetty server. Although it has been available as part of the Servlet specification for an extended period, it was deemed optional with Servlet 6.0 of EE10, reflecting its status as a somewhat niche feature.
Initially, Jetty 12 moved away from supporting Cross-Context Dispatch, driven by a desire to simplify the server architecture amidst substantial changes, including support for multiple environments (EE8, EE9, and EE10). These updates mean Jetty can now deploy web applications using either the javax namespace (EE8) or the jakarta namespace (EE9 and EE10), all using the latest optimized jetty core implementations of HTTP: v1, v2 or v3.
Reintroducing Cross-Context Dispatch
The decision to reintegrate Cross-Context Dispatch in Jetty 12.0.8 was influenced significantly by the needs of our commercial clients, some who still leveraging this feature in their legacy applications. Our commitment to supporting our clients’ requirements, including the need to maintain and extend legacy systems, remains a top priority.
One of the standout features of the newly implemented Cross-Context Dispatch is its ability to bridge applications across different environments. This means a web application based on the javax namespace (EE8) can now dispatch requests to, or include responses from, a web application based on the jakarta namespace (EE9 or EE10). This functionality opens up new pathways for integrating legacy applications with newer, modern systems.
Looking Ahead
The reintroduction of Cross-Context Dispatch in Jetty 12.0.8 is more than just a nod to legacy systems; it can be used as a bridge to the future of Java web development. By allowing for seamless interactions between applications across different Servlet environments, Jetty-12 opens the possibility of incremental migration away from legacy web applications.
January 10, 2024

Monitoring Java Virtual Threads
by Jean-François James at January 10, 2024 05:14 PM
October 12, 2023
Moving from javax to jakarta namespace
by Jean-Louis Monteiro at October 12, 2023 02:32 PM
This blog aims at giving some pointers in order to address the challenge related to the switch from `javax` to `jakarta` namespace. This is one of the biggest changes in Java of the latest 20 years. No doubt. The entire ecosystem is impacted. Not only Java EE or Jakarta EE Application servers, but also libraries of any kind (Jackson, CXF, Hibernate, Spring to name a few). For instance, it took Apache TomEE about a year to convert all the source code and dependencies to the new `jakarta` namespace.
This blog is written from the user perspective, because the shift from `javax` to `jakarta` is as impacting for application providers than it is for libraries or application servers. There have been a couple of attempts to study the impact and investigate possible paths to make the change as smooth as possible.
The problem is harder than it appears to be. The `javax` package is of course in the import section of a class, but it can be in Strings as well if you use the Java Reflection API for instance. Using Byte Code tools like ASM also makes the problem more complex, but also service loader mechanisms and many more. We will see that there are many ways to approach the problem, using byte code, converting the sources directly, but none are perfect.
Bytecode enhancement approach
The first legitimate approach that comes to our mind is the byte code approach. The goal is to keep the `javax` namespace as much as possible and use bytecode enhancement to convert binaries.
Compile time
It is possible to do a post treatment on the libraries and packages to transform archives such as then are converted to `jakarta` namespace.
- https://maven.apache.org/plugins/maven-shade-plugin/[Maven Shade plugin]
The Maven shade plugin has the ability to relocate packages. While the primary purpose isn’t to move from `javax` to `jakarta` package, it is possible to use it to relocate small libraries when they aren’t ready yet. We used this approach in TomEE itself or in third party libraries such as Apache Johnzon (JSONB/P implementation).
Here is an example in TomEE where we use Maven Shade Plugin to transform the Apache ActiveMQ Client library https://github.com/apache/tomee/blob/main/deps/activemq-client-shade/pom.xml
This approach is not perfect, especially when you have a multi module library. For Instance, if you have a project with 2 modules, A depends on B. You can use the shade plugin to convert the 2 modules and publish them using a classifier. The issue then is when you need A, you have to exclude B so that you can include it manually with the right classifier.
We’d say it works fine but for simple cases because it breaks the dependency management in Maven, especially with transitive dependencies. It also break IDE integration because sources and javadoc won’t match.
- https://projects.eclipse.org/projects/technology.transformer[Eclipse Transformer]
The Eclipse Transformer is also a generic tool, but it’s been heavily developed for the `javax` to `jakarta` namespace change. It operates on resources such as
Simple resources:
- Java class files
- OSGi feature manifest files
- Properties files
- Service loader configuration files
- Text files (of several types: java source, XML, TLD, HTML, and JSP)
Container resources:
- Directories
- Java archives (JAR, WAR, RAR, and EAR files)
- ZIP archives
It can be configured using Java Properties files to properly convert Java Modules, classes, test resources. This is the approach we used for Apache TomEE 9.0.0-M7 when we first tried to convert to `jakarta`. It had limitation, so we had to then find tricks to solve issues. As it was converting the final distribution and not the individual artifacts, it was impossible for users to use Arquillian or the Maven plugin. They were not converted.
- https://github.com/apache/tomcat-jakartaee-migration[Apache Tomcat Migration tool]
This tool can operate on a directory or an archive (zip, ear, jar, war). It can migrate quite easily an application based on the set of specifications supported in Tomcat and a few more. It has the notion of profile so that you can ask it to convert more.
You can run it using the ANT task (within Maven or not), and there is also a command line interface to run it easily.
Deploy time
When using application server, it is sometimes possible to step in the deployment process and do the conversion of the binaries prior to their deployment.
- https://github.com/apache/tomcat-jakartaee-migration[Apache Tomcat/TomEE migration tool]
Mind that by default, the tool converts only what’s being supported by Apache Tomcat and a couple of other APIs. It does not convert all specifications supported in TomEE, like JAX RS for example. And Tomcat does not provide yet any way to configure it.
Runtime
We haven’t seen any working solution in this area. Of course, we could imagine a JavaAgent approach that converts the bytecode right when it gets loaded by the JVM. The startup time is seriously impacted, and it has to be done every time the JVM restarts or loads a class in a classloader. Remember that a class can be loaded multiple times in different classloaders.
Source code enhancement approach
This may sound like the most impacting but this is probably also the most secured one. We also strongly believe that embracing the change sooner is preferable rather than later. As mentioned, this is one of the biggest breaking change in Java of the last 20 years. Since Java EE moved to Eclipse to become Jakarta, we have noticed a change in the release cadence. Releases are not more frequent and more changes are going to happen. Killing the technical depth as soon as possible is probably the best when it’s so impacting.
There are a couple of tools we tried. There are probably more in the ecosystem, and also some in-house developments.
[IMPORTANT]
This is usually a one shoot operation. It won’t be perfect and no doubt it will require adjustment because there is no perfect tool that can handle all cases.
IntelliJ IDEA
IntelliJ IDEA added a refactoring capability to its IDE in order to convert sources to the new `jakarta` namespace. I haven’t tested it myself, but it may help to do the first big step when you don’t really master the scripting approach below.
Scripting approach
For simple case, and we used that approach to do most of the conversion in TomEE, you can create your own simple tool to convert sources. For instance, SmallRye does that with their MicroProfile implementations. Here is an example https://github.com/smallrye/smallrye-config/blob/main/to-jakarta.sh
Using basic Linux commands, it converts from `javax` to `jakarta` namespace and then the result is pushed to a dedicated branch. The benefit is that they have 2 source trees with different artifacts, the dependency management isn’t broken.
One source tree is the reference and they add to the script the necessary commands to convert additional things on demand.
- https://projects.eclipse.org/projects/technology.transformer[Eclipse Transformer]
Because the Eclipse Transformer can operate on text files, it can be easily used to migrate the sources from `javax` to `jakarta` namespace.
Producing converted artifacts for applications for consumption
Weather you are working on Open Source or not, someone will consume your artifacts. If you are using Maven for example, you may ask yourself what option is the best especially if you maintain the 2 branches `javax` and `jakarta`.
[NOTE]
It does not matter if you use the bytecode or the source code approach.
Updating version or artifactId
This is probably the more practical solution. Some project like Arquillian for example decided to go using a different artifact name (-jakarta suffix) because the artifact is the same and solves the same problem, so why bringing a technical concerned into the name? I’m more in favor of using the version to mark the namespace change. It is somehow an major API change that I’d rather emphasize using a major version update.
[IMPORTANT]
Mind that this only works if both `javax` and `jakarta` APIs are backward compatible. Otherwise, it won’t work
Using Maven classifiers
This is not an option we would recommend. Unfortunately some of our dependencies use this approach and it has many drawbacks. It’s fine for a quick test, but as I mentioned previously, it badly impacts how Maven works. If you pull a transformed artifact, you may get a transitive and not transformed dependency. This is the case for multi module project as well.
Another painful side effect is that javadoc and sources are still linked to the original artifact, so you will have a hard time to debug in the IDE.
Conclusion
We tried the bytecode approach ourselves in TomEE with the hope we could avoid maintaining 2 source trees, one for `javax` and the other one for `jakarta` namespace. Unfortunately, as we have seen before the risk is too important and there are too many edge cases not covered. Apache TomEE runs about 60k tests (including TCK) and our confidence wasn’t good enough. Even though the approach has some benefits and can work for simple use cases, like converting a small utility tool, it does not fit in our opinion for real applications.
The post Moving from javax to jakarta namespace appeared first on Tomitribe.
September 20, 2023
Running MicroProfile reactive with Helidon Nima and Virtual Threads
by Jean-François James at September 20, 2023 05:29 PM
September 19, 2023

New Survey: How Do Developers Feel About Enterprise Java in 2023?
by Mike Milinkovich at September 19, 2023 01:00 PM
The results of the 2023 Jakarta EE Developer Survey are now available! For the sixth year in a row, we’ve reached out to the enterprise Java community to ask about their preferences and priorities for cloud native Java architectures, technologies, and tools, their perceptions of the cloud native application industry, and more.
From these results, it is clear that open source cloud native Java is on the rise following the release of Jakarta EE 10.The number of respondents who have migrated to Jakarta EE continues to grow, with 60% saying they have already migrated, or plan to do so within the next 6-24 months. These results indicate steady growth in the use of Jakarta EE and a growing interest in cloud native Java overall.
When comparing the survey results to 2022, usage of Jakarta EE to build cloud native applications has remained steady at 53%. Spring/Spring Boot, which relies on some Jakarta EE specifications, continues to be the leading Java framework in this category, with usage growing from 57% to 66%.
Since the September 2022 release, Jakarta EE 10 usage has grown to 17% among survey respondents. This community-driven release is attracting a growing number of application developers to adopt Jakarta EE 10 by offering new features and updates to Jakarta EE. An equal number of developers are running Jakarta EE 9 or 9.1 in production, while 28% are running Jakarta EE 8. That means the increase we are seeing in the migration to Jakarta EE is mostly due to the adoption of Jakarta EE 10, as compared to Jakarta EE 9/9.1 or Jakarta EE 8.
The Jakarta EE Developer Survey also gives us a chance to get valuable feedback on features from the latest Jakarta EE release, as well as what direction the project should take in the future.
Respondents are most excited about Jakarta EE Core Profile, which was introduced in the Jakarta EE 10 release as a subset of Web Profile specifications designed for microservices and ahead-of-time compilation. When it comes to future releases, the community is prioritizing better support for Kubernetes and microservices, as well as adapting Java SE innovations to Jakarta EE — a priority that has grown in popularity since 2022. This is a good indicator that the Jakarta EE 11 release plan is on the right direction by adopting new Java SE 21 features.
2,203 developers, architects, and other tech professionals participated in the survey, a 53% increase from last year. This year’s survey was also available in Chinese, Japanese, Spanish & Portuguese, making it easier for Java enthusiasts around the world to share their perspectives. Participation from the Chinese Jakarta EE community was particularly strong, with over 27% of the responses coming from China. By hearing from more people in the enterprise Java space, we’re able to get a clearer picture of what challenges developers are facing, what they’re looking for, and what technologies they are using. Thank you to everyone who participated!
Learn More
We encourage you to download the report for a complete look at the enterprise Java ecosystem.
If you’d like to get more information about Jakarta EE specifications and our open source community, sign up for one of our mailing lists or join the conversation on Slack. If you’d like to participate in the Jakarta EE community, learn how to get started on our website.
November 19, 2022

Jakarta EE and MicroProfile at EclipseCon Community Day 2022
by Reza Rahman at November 19, 2022 10:39 PM
Community Day at EclipseCon 2022 was held in person on Monday, October 24 in Ludwigsburg, Germany. Community Day has always been a great event for Eclipse working groups and project teams, including Jakarta EE/MicroProfile. This year was no exception. A number of great sessions were delivered from prominent folks in the community. The following are the details including session materials. The agenda can still be found here. All the materials can be found here.

Jakarta EE Community State of the Union
The first session of the day was a Jakarta EE community state of the union delivered by Tanja Obradovic, Ivar Grimstad and Shabnam Mayel. The session included a quick overview of Jakarta EE releases, how to get involved in the work of producing the specifications, a recap of the important Jakarta EE 10 release and as well as a view of what’s to come in Jakarta EE 11. The slides are embedded below and linked here.
Jakarta Concurrency – What’s Next
Payara CEO Steve Millidge covered Jakarta Concurrency. He discussed the value proposition of Jakarta Concurrency, the innovations delivered in Jakarta EE 10 (including CDI based @Asynchronous, @ManagedExecutorDefinition, etc) and the possibilities for the future (including CDI based @Schedule, @Lock, @MaxConcurrency, etc). The slides are embedded below and linked here. There are some excellent code examples included.
Jakarta Security – What’s Next
Werner Keil covered Jakarta Security. He discussed what’s already done in Jakarta EE 10 (including OpenID Connect support) and everything that’s in the works for Jakarta EE 11 (including CDI based @RolesAllowed). The slides are embedded below and linked here.
Jakarta Data – What’s Coming
IBM’s Emily Jiang kindly covered Jakarta Data. This is a brand new specification aimed towards Jakarta EE 11. It is a higher level data access abstraction similar to Spring Data and DeltaSpike Data. It encompasses both Jakarta Persistence (JPA) and Jakarta NoSQL. The slides are embedded below and linked here. There are some excellent code examples included.
MicroProfile Community State of the Union
Emily also graciously delivered a MicroProfile state of the union. She covered what was delivered in MicroProfile 5, including alignment with Jakarta EE 9.1. She also discussed what’s coming soon in MicroProfile 6 and beyond, including very clear alignment with the Jakarta EE 10 Core Profile. The slides are embedded below and linked here. There are some excellent technical details included.
MicroProfile Telemetry – What’s Coming
Red Hat’s Martin Stefanko covered MicroProfile Telemetry. Telemetry is a brand new specification being included in MicroProfile 6. The specification essentially supersedes MicroProfile Tracing and possibly MicroProfile Metrics too in the near future. This is because the OpenTracing and OpenCensus projects merged into a single project called OpenTelemetry. OpenTelemetry is now the de facto standard defining how to collect, process, and export telemetry data in microservices. It makes sense that MicroProfile moves forward with supporting OpenTelemetry. The slides are embedded below and linked here. There are some excellent technical details and code examples included.
See You There Next Time?
Overall, it was an honor to organize the Jakarta EE/MicroProfile agenda at EclipseCon Community Day one more time. All speakers and attendees should be thanked. Perhaps we will see you at Community Day next time? It is a great way to hear from some of the key people driving Jakarta EE and MicroProfile. You can attend just Community Day even if you don’t attend EclipseCon. The fee is modest and includes lunch as well as casual networking.
November 04, 2022

JFall 2022
November 04, 2022 09:56 AM

An impression of JFall by yours truly.
keynote
Sold out!

Packet room!


Very nice first keynote speaker by Saby Sengupta about the path to transform.
He is a really nice storyteller. He had us going.
Dutch people, wooden shoes, wooden hat, would not listen
- Saby
lol
Get the answer to three why questions. If the answers stop after the first why. It may not be a good idea.

This great first keynote is followed by the very well known Venkat Subramaniam about The Art of Simplicity.


The question is not what can we add? But What can we remove?
Simple fails less
Simple is elegant
All in al a great keynote! Loved it.
Design Patterns in the light of Lambdas
By Venkat Subramaniam

The GOF are kind of the grand parents of our industry. The worst thing they have done is write the damn book.
— Venkat
The quote is in the context of that writing down grandmas fantastic recipe does not work as it is based on the skill of grandma and not the exact amount of the ingredients.
The cleanup is the responsibility of the Resource class. Much better than asking developers to take care of it. It will be forgotten!
The more powerful a language becomes the less we need to talk about patterns. Patterns become practices we use. We do not need to put in extra effort.
I love his way of presenting, but this is the one of those times - I guess - that he is hampered by his own succes. The talk did not go deep into stuff. During his talk I just about covered 5 not too difficult subjects. I missed his speed and depth.
Still a great talk though.
lunch
Was actually very nice!
NLJUG update keynote

The Java Magazine was mentioned we (as Editors) had to shout for that!
Please contact me (@ivonet) if you have ambitions to either be an author or maybe even as a fellow editor of the magazine. We are searching for a new Editor now.
Then the voting for the Innovation Awards.
I kinda missed the next keynote by ING because I was playing with a rubix cube and I did not really like his talk
jakarta EE 10 platform
by Ivar Grimstad

Ivar talks about the specification of Jakarta EE.



To create a lite version of CDI it is possible to start doing things at build time and facilitate other tools like GraalVM and Quarkus.

He gives nice demos on how to migrate code to work in de jakarta namespace.
To start your own Jakarta EE application just go to start.jakarta.ee en follow the very simple UI instructions
I am very proud to be the creator of that UI. Thanks, Ivar for giving me a shoutout for that during your talk. More cool stuff will follow soon.



Be prepared to do some namespace changes when moving from Java EE 8 to Jakarta EE.

All slides here
conclusion
I had a fantastic day. For me, it is mainly about the community and seeing all the people I know in the community. I totally love the vibe of the conference and I think it is one of the best organized venues.
See you at JSpring.
Ivo.
September 26, 2022
Survey Says: Confidence Continues to Grow in the Jakarta EE Ecosystem
by Mike Milinkovich at September 26, 2022 01:00 PM
The results of the 2022 Jakarta EE Developer Survey are very telling about the current state of the enterprise Java developer community. They point to increased confidence about Jakarta EE and highlight how far Jakarta EE has grown over the past few years.
Strong Turnout Helps Drive Future of Jakarta EE
The fifth annual survey is one of the longest running and best-respected surveys of its kind in the industry. This year’s turnout was fantastic: From March 9 to May 6, a total of 1,439 developers responded.
This is great for two reasons. First, obviously, these results help inform the Java ecosystem stakeholders about the requirements, priorities and perceptions of enterprise developer communities. The more people we hear from, the better picture we get of what the community wants and needs. That makes it much easier for us to make sure the work we’re doing is aligned with what our community is looking for.
The other reason is that it helps us better understand how the cloud native Java world is progressing. By looking at what community members are using and adopting, what their top goals are and what their plans are for adoption, we can better understand not only what we should be working on today, but tomorrow and for the future of Jakarta EE.
Findings Indicate Growing Adoption and Rising Expectations
Some of the survey’s key findings include:
- Jakarta EE is the basis for the top frameworks used for building cloud native applications.
- The top three frameworks for building cloud native applications, respectively, are Spring/Spring Boot, Jakarta EE and MicroProfile, though Spring/Spring Boot lost ground this past year. It’s important to note that Spring/SpringBoot relies on Jakarta EE developments for its operation and is not competitive with Jakarta EE. Both are critical ingredients to the healthy enterprise Java ecosystem.
- Jakarta EE 9/9.1 usage increased year-over-year by 5%.
- Java EE 8, Jakarta EE 8, and Jakarta EE 9/9.1 hit the mainstream with 81% adoption.
- While over a third of respondents planned to adopt, or already had adopted Jakarta EE 9/9.1, nearly a fifth of respondents plan to skip Jakarta EE 9/9.1 altogether and adopt Jakarta EE 10 once it becomes available.
- Most respondents said they have migrated to Jakarta EE already or planned to do so within the next 6-24 months.
- The top three community priorities for Jakarta EE are:
- Native integration with Kubernetes (same as last year)
- Better support for microservices (same as last year)
- Faster support from existing Java EE/Jakarta EE or cloud vendors (new this year)
Two of the results, when combined, highlight something interesting:
- 19% of respondents planned to skip Jakarta EE 9/9.1 and go straight to 10 once it’s available
- The new community priority — faster support from existing Java EE/Jakarta EE or cloud vendors — really shows the growing confidence the community has in the ecosystem
After all, you wouldn’t wait for a later version and skip the one that’s already available, unless you were confident that the newer version was not only going to be coming out on a relatively reliable timeline, but that it was going to be an improvement.
And this growing hunger from the community for faster support really speaks to how far the ecosystem has come. When we release a new version, like when we released Jakarta EE 9, it takes some time for the technology implementers to build the product based on those standards or specifications. The community is becoming more vocal in requesting those implementers to be more agile and quickly pick up the new versions. That’s definitely an indication that developer demand for Jakarta EE products is growing in a healthy way.
Learn More
If you’d like to learn more about the project, there are several Jakarta EE mailing lists to sign up for. You can also join the conversation on Slack. And if you want to get involved, start by choosing a project, sign up for its mailing list and start communicating with the team.
September 22, 2022
Jakarta EE 10 has Landed!
by javaeeguardian at September 22, 2022 03:48 PM
The Jakarta EE Ambassadors are thrilled to see Jakarta EE 10 being released! This is a milestone release that bears great significance to the Java ecosystem. Jakarta EE 8 and Jakarta EE 9.x were important releases in their own right in the process of transitioning Java EE to a truly open environment in the Eclipse Foundation. However, these releases did not deliver new features. Jakarta EE 10 changes all that and begins the vital process of delivering long pending new features into the ecosystem at a regular cadence.

There are quite a few changes that were delivered – here are some key themes and highlights:
- CDI Alignment
- @Asynchronous in Concurrency
- Better CDI support in Batch
- Java SE Alignment
- Support for Java SE 11, Java SE 17
- CompletionStage, ForkJoinPool, parallel streams in Concurrency
- Bootstrap APIs for REST
- Closing standardization gaps
- OpenID Connect support in Security, @ManagedExecutorDefinition, UUID as entity keys, more SQL support in Persistence queries, multipart/form-data support in REST, @ClientWindowScoped in Faces, pure Java Faces views
- CDI Lite/Core Profile to enable next generation cloud native runtimes – MicroProfile will likely align with CDI Lite/Jakarta EE Core
- Deprecation/removal
- @Context annotation in REST, EJB Entity Beans, embeddable EJB container, deprecated Servlet/Faces/CDI features
While there are many features that we identified in our Jakarta EE 10 Contribution Guide that did not make it yet, this is still a very solid release that everyone in the Java ecosystem will benefit from, including Spring, MicroProfile and Quarkus. You can see here what was delivered, what’s on the way and what gaps still remain. You can try Jakarta EE 10 out now using compatible implementations like GlassFish, Payara, WildFly and Open Liberty. Jakarta EE 10 is proof in the pudding that the community, including major stakeholders, has not only made it through the transition to the Eclipse Foundation but now is beginning to thrive once again.
Many Ambassadors helped make this release a reality such as Arjan Tijms, Werner Keil, Markus Karg, Otavio Santana, Ondro Mihalyi and many more. The Ambassadors will now focus on enabling the community to evangelize Jakarta EE 10 including speaking, blogging, trying out implementations, and advocating for real world adoption. We will also work to enable the community to continue to contribute to Jakarta EE by producing an EE 11 Contribution Guide in the coming months. Please stay tuned and join us.
Jakarta EE is truly moving forward – the next phase of the platform’s evolution is here!
July 13, 2022

Java Reflections unit-testing
by Vladimir Bychkov at July 13, 2022 09:06 PM
May 05, 2022
Java EE - Jakarta EE Initializr
May 05, 2022 02:23 PM

Getting started with Jakarta EE just became even easier!
Get started
Hot new Update!
Moved from the Apache 2 license to the Eclipse Public License v2 for the newest version of the archetype as described below.
As a start for a possible collaboration with the Eclipse start project.
New Archetype with JakartaEE 9
JakartaEE 9 + Payara 5.2022.2 + MicroProfile 4.1 running on Java 17
- And the docker image is also ready for x86_64 (amd64) AND aarch64 (arm64/v8) architectures!
February 21, 2022
FOSDEM 2022 Conference Report
by Reza Rahman at February 21, 2022 12:24 AM
FOSDEM took place February 5-6. The European based event is one of the most significant gatherings worldwide focused on all things Open Source. Named the “Friends of OpenJDK”, in recent years the event has added a devroom/track dedicated to Java. The effort is lead by my friend and former colleague Geertjan Wielenga. Due to the pandemic, the 2022 event was virtual once again. I delivered a couple of talks on Jakarta EE as well as Diversity & Inclusion.

Fundamentals of Diversity & Inclusion for Technologists
I opened the second day of the conference with my newest talk titled “Fundamentals of Diversity and Inclusion for Technologists”. I believe this is an overdue and critically important subject. I am very grateful to FOSDEM for accepting the talk. The reality for our industry remains that many people either have not yet started or are at the very beginning of their Diversity & Inclusion journey. This talk aims to start the conversation in earnest by explaining the basics. Concepts covered include unconscious bias, privilege, equity, allyship, covering and microaggressions. I punctuate the topic with experiences from my own life and examples relevant to technologists. The slides for the talk are available on SpeakerDeck. The video for the talk is now posted on YouTube.
Jakarta EE – Present and Future
Later the same day, I delivered my fairly popular talk – “Jakarta EE – Present and Future”. The talk is essentially a state of the union for Jakarta EE. It covers a little bit of history, context, Jakarta EE 8, Jakarta EE 9/9.1 as well as what’s ahead for Jakarta EE 10. One key component of the talk is the importance and ways of direct developer contributions into Jakarta EE, if needed with help from the Jakarta EE Ambassadors. Jakarta EE 10 and the Jakarta Core Profile should bring an important set of changes including to CDI, Jakarta REST, Concurrency, Security, Faces, Batch and Configuration. The slides for the talk are available on SpeakerDeck. The video for the talk is now posted on YouTube.
I am very happy to have had the opportunity to speak at FOSDEM. I hope to contribute again in the future.
December 12, 2021

Infinispan Apache Log4j 2 CVE-2021-44228 vulnerability
December 12, 2021 10:00 PM
Infinispan 10+ uses Log4j version 2.0+ and can be affected by vulnerability CVE-2021-44228, which has a 10.0 CVSS score. The first fixed Log4j version is 2.15.0.
So, until official patch is coming, - you can update used logger version to the latest in few simple steps
- Download Log4j version 2.15.0: https://www.apache.org/dyn/closer.lua/logging/log4j/2.15.0/apache-log4j-2.15.0-bin.zip
- Unpack distributive
- Replace affected libraries
wget https://downloads.apache.org/logging/log4j/2.15.0/apache-log4j-2.15.0-bin.zip
unzip apache-log4j-2.15.0-bin.zip
cd /opt/infinispan-server-10.1.8.Final/lib/
rm log4j-*.jar
cp ~/Downloads/apache-log4j-2.15.0-bin/log4j-api-2.15.0.jar ./
cp ~/Downloads/apache-log4j-2.15.0-bin/log4j-core-2.15.0.jar ./
cp ~/Downloads/apache-log4j-2.15.0-bin/log4j-jul-2.15.0.jar ./
cp ~/Downloads/apache-log4j-2.15.0-bin/log4j-slf4j-impl-2.15.0.jar ./
Please, note - patch above is not official, but according to initial tests it works with no issues
November 18, 2021
JPA query methods: influence on performance
by Vladimir Bychkov at November 18, 2021 07:22 AM
September 30, 2021
Custom Identity Store with Jakarta Security in TomEE
by Jean-Louis Monteiro at September 30, 2021 11:42 AM
In the previous post, we saw how to use the built-in ‘tomcat-users.xml’ identity store with Apache TomEE. While this identity store is inherited from Tomcat and integrated into Jakarta Security implementation in TomEE, this is usually good for development or simple deployments, but may appear too simple or restrictive for production environments.
This blog will focus on how to implement your own identity store. TomEE can use LDAP or JDBC identity stores out of the box. We will try them out next time.
Let’s say you have your own file store or your own data store like an in-memory data grid, then you will need to implement your own identity store.
What is an identity store?
An identity store is a database or a directory (store) of identity information about a population of users that includes an application’s callers.
In essence, an identity store contains all information such as caller name, groups or roles, and required information to validate a caller’s credentials.
How to implement my own identity store?
This is actually fairly simple with Jakarta Security. The only thing you need to do is create an implementation of `jakarta.security.enterprise.identitystore.IdentityStore`. All methods in the interface have default implementations. So you only have to implement what you need.
public interface IdentityStore {
Set DEFAULT_VALIDATION_TYPES = EnumSet.of(VALIDATE, PROVIDE_GROUPS);
default CredentialValidationResult validate(Credential credential) {
}
default Set getCallerGroups(CredentialValidationResult validationResult) {
}
default int priority() {
}
default Set validationTypes() {
}
enum ValidationType {
VALIDATE, PROVIDE_GROUPS
}
}
By default, an identity store is used for both validating user credentials and providing groups/roles for the authenticated user. Depending on what #validationTypes() will return, you will have to implement #validate(…) and/or #getCallerGroups(…)
#getCallerGroups(…) will receive the result of #valide(…). Let’s look at a very simple example:
@ApplicationScoped
public class TestIdentityStore implements IdentityStore {
public CredentialValidationResult validate(Credential credential) {
if (!(credential instanceof UsernamePasswordCredential)) {
return INVALID_RESULT;
}
final UsernamePasswordCredential usernamePasswordCredential = (UsernamePasswordCredential) credential;
if (usernamePasswordCredential.compareTo("jon", "doe")) {
return new CredentialValidationResult("jon", new HashSet<>(asList("foo", "bar")));
}
if (usernamePasswordCredential.compareTo("iron", "man")) {
return new CredentialValidationResult("iron", new HashSet<>(Collections.singletonList("avengers")));
}
return INVALID_RESULT;
}
}
In this simple example, the identity store is hardcoded. Basically, it knows only 2 users, one of them has some roles, while the other has another set of roles.
You can easily extend this example and query a local file, or an in-memory data grid if you need. Or use JPA to access your relational database.
IMPORTANT: for TomEE to pick it up and use it in your application, the identity store must be a CDI bean.
The complete and runnable example is available under https://github.com/apache/tomee/tree/master/examples/security-custom-identitystore
The post Custom Identity Store with Jakarta Security in TomEE appeared first on Tomitribe.
April 02, 2021
Undertow AJP balancer. UT005028: Proxy request failed: java.nio.BufferOverflowException
April 02, 2021 09:00 PM
Wildfly provides great out of the box load balancing support by Undertow and modcluster subsystems
Unfortunately, in case HTTP headers size is huge enough (close to 16K), which is so actual in JWT era - pity error happened:
ERROR [io.undertow.proxy] (default I/O-10) UT005028: Proxy request to /ee-jax-rs-examples/clusterdemo/serverinfo failed: java.io.IOException: java.nio.BufferOverflowException
at io.undertow.server.handlers.proxy.ProxyHandler$HTTPTrailerChannelListener.handleEvent(ProxyHandler.java:771)
at io.undertow.server.handlers.proxy.ProxyHandler$ProxyAction$1.completed(ProxyHandler.java:646)
at io.undertow.server.handlers.proxy.ProxyHandler$ProxyAction$1.completed(ProxyHandler.java:561)
at io.undertow.client.ajp.AjpClientExchange.invokeReadReadyCallback(AjpClientExchange.java:203)
at io.undertow.client.ajp.AjpClientConnection.initiateRequest(AjpClientConnection.java:288)
at io.undertow.client.ajp.AjpClientConnection.sendRequest(AjpClientConnection.java:242)
at io.undertow.server.handlers.proxy.ProxyHandler$ProxyAction.run(ProxyHandler.java:561)
at io.undertow.util.SameThreadExecutor.execute(SameThreadExecutor.java:35)
at io.undertow.server.HttpServerExchange.dispatch(HttpServerExchange.java:815)
...
Caused by: java.nio.BufferOverflowException
at java.nio.Buffer.nextPutIndex(Buffer.java:521)
at java.nio.DirectByteBuffer.put(DirectByteBuffer.java:297)
at io.undertow.protocols.ajp.AjpUtils.putString(AjpUtils.java:52)
at io.undertow.protocols.ajp.AjpClientRequestClientStreamSinkChannel.createFrameHeaderImpl(AjpClientRequestClientStreamSinkChannel.java:176)
at io.undertow.protocols.ajp.AjpClientRequestClientStreamSinkChannel.generateSendFrameHeader(AjpClientRequestClientStreamSinkChannel.java:290)
at io.undertow.protocols.ajp.AjpClientFramePriority.insertFrame(AjpClientFramePriority.java:39)
at io.undertow.protocols.ajp.AjpClientFramePriority.insertFrame(AjpClientFramePriority.java:32)
at io.undertow.server.protocol.framed.AbstractFramedChannel.flushSenders(AbstractFramedChannel.java:603)
at io.undertow.server.protocol.framed.AbstractFramedChannel.flush(AbstractFramedChannel.java:742)
at io.undertow.server.protocol.framed.AbstractFramedChannel.queueFrame(AbstractFramedChannel.java:735)
at io.undertow.server.protocol.framed.AbstractFramedStreamSinkChannel.queueFinalFrame(AbstractFramedStreamSinkChannel.java:267)
at io.undertow.server.protocol.framed.AbstractFramedStreamSinkChannel.shutdownWrites(AbstractFramedStreamSinkChannel.java:244)
at io.undertow.channels.DetachableStreamSinkChannel.shutdownWrites(DetachableStreamSinkChannel.java:79)
at io.undertow.server.handlers.proxy.ProxyHandler$HTTPTrailerChannelListener.handleEvent(ProxyHandler.java:754)
The same request directly to backend server works well. Tried to play with ajp-listener and mod-cluster filter "max-*" parameters, but have no luck.
Possible solution here is switch protocol from AJP to HTTP which can be bit less effective, but works well with big headers:
/profile=full-ha/subsystem=modcluster/proxy=default:write-attribute(name=listener, value=default)
July 06, 2020

Jakarta EE Cookbook
by Elder Moraes at July 06, 2020 07:19 PM
About one month ago I had the pleasure to announce the release of the second edition of my book, now called “Jakarta EE Cookbook”. By that time I had recorded a video about and you can watch it here:
[embedyt] https://www.youtube.com/watch?v=SFbDs1HKEyA[/embedyt]
And then came a crazy month and just now I had the opportunity to write a few lines about it! 
So, straight to the point, what you should know about the book (in case you have any interest in it).
Target audience
Java developers working on enterprise applications and that would like to get the best from the Jakarta EE platform.
Topics covered
I’m sure this is one of the most complete books of this field, and I’m saying it based on the covered topics:
- Server-side development
- Building services with RESTful features
- Web and client-server communication
- Security in the enterprise architecture
- Jakarta EE standards (and how does it save you time on a daily basis)
- Deployment and management using some of the best Jakarta EE application servers
- Microservices with Jakarta EE and Eclipse MicroProfile
- CI/CD
- Multithreading
- Event-driven for reactive applications
- Jakarta EE, containers & cloud computing
Style and approach
The book has the word “cookbook” on its name for a reason: it follows a 100% practical approach, with almost all working code available in the book (we only omitted the imports for the sake of the space).
And talking about the source code being available, it is really available on my Github: https://github.com/eldermoraes/javaee8-cookbook
PRs and Stars are welcomed!
Bonus content
The book has an appendix that would be worthy of another book! I tell the readers how sharing knowledge has changed my career for good and how you can apply what I’ve learned in your own career.
Surprise, surprise
In the first 24 hours of its release, this book simply reached the 1st place at Amazon among other Java releases! Wow!

Of course, I’m more than happy and honored for such a warm welcome given to my baby…
If you are interested in it, we are in the very last days of the special price in celebration of its release. You can take a look here http://book.eldermoraes.com
Leave your comments if you need any clarification about it. See you!
January 19, 2020

Jakarta EE 8 CRUD API Tutorial using Java 11
by Philip Riecks at January 19, 2020 03:07 PM
As part of the Jakarta EE Quickstart Tutorials on YouTube, I’ve now created a five-part series to create a Jakarta EE CRUD API. Within the videos, I’m demonstrating how to start using Jakarta EE for your next application. Given the Liberty Maven Plugin and MicroShed Testing, the endpoints are developed using the TDD (Test Driven Development) technique.
The following technologies are used within this short series: Java 11, Jakarta EE 8, Open Liberty, Derby, Flyway, MicroShed Testing & JUnit 5
Part I: Introduction to the application setup
This part covers the following topics:
- Introduction to the Maven project skeleton
- Flyway setup for Open Liberty
- Derby JDBC connection configuration
- Basic MicroShed Testing setup for TDD
Part II: Developing the endpoint to create entities
This part covers the following topics:
- First JAX-RS endpoint to create
Personentities - TDD approach using MicroShed Testing and the Liberty Maven Plugin
- Store the entities using the
EntityManager
Part III: Developing the endpoints to read entities
This part covers the following topics:
- Develop two JAX-RS endpoints to read entities
- Read all entities and by its id
- Handle non-present entities with a different HTTP status code
Part IV: Developing the endpoint to update entities
This part covers the following topics:
- Develop the JAX-RS endpoint to update entities
- Update existing entities using HTTP PUT
- Validate the client payload using Bean Validation
Part V: Developing the endpoint to delete entities
This part covers the following topics:
- Develop the JAX-RS endpoint to delete entities
- Enhance the test setup for deterministic and repeatable integration tests
- Remove the deleted entity from the database
The source code for the Maven CRUD API application is available on GitHub.
For more quickstart tutorials on Jakarta EE, have a look at the overview page on my blog.
Have fun developing Jakarta EE CRUD API applications,
Phil
The post Jakarta EE 8 CRUD API Tutorial using Java 11 appeared first on rieckpil.
January 07, 2020
Deploy a Jakarta EE application to the root context
by Philip Riecks at January 07, 2020 06:24 AM
With the presence of Docker, Kubernetes and cheaper hardware, the deployment model of multiple applications inside one application server has passed. Now, you deploy one Jakarta EE application to one application server. This eliminates the need for different context paths. You can use the root context / for your Jakarta EE application. With this blog post, you’ll learn how to achieve this for each Jakarta EE application server.
The default behavior for Jakarta EE application server
Without any further configuration, most of the Jakarta EE application servers deploy the application to a context path based on the filename of your .war. If you e.g. deploy your my-banking-app.war application, the server will use the context prefix /my-banking-app for your application. All you JAX-RS endpoints, Servlets, .jsp, .xhtml content is then available below this context, e.g /my-banking-app/resources/customers.
This was important in the past, where you deployed multiple applications to one application server. Without the context prefix, the application server wouldn’t be able to route the traffic to the correct application.
As of today, the deployment model changed with Docker, Kubernetes and cheaper infrastructure. You usually deploy one .war within one application server running as a Docker container. Given this deployment model, the context prefix is irrelevant. Mapping the application to the root context / is more convenient.
If you configure a reverse proxy or an Ingress controller (in the Kubernetes world), you are happy if you can just route to / instead of remembering the actual context path (error-prone).
Deploying to root context: Payara & Glassfish
As Payara is a fork of Glassfish, the configuration for both is quite similar. The most convenient way for Glassfish is to place a glassfish-web.xml file in the src/main/webapp/WEB-INF folder of your application:
<!DOCTYPE glassfish-web-app PUBLIC "-//GlassFish.org//DTD GlassFish Application Server 3.1 Servlet 3.0//EN" "http://glassfish.org/dtds/glassfish-web-app_3_0-1.dtd"> <glassfish-web-app> <context-root>/</context-root> </glassfish-web-app>
For Payara the filename is payara-web.xml:
<!DOCTYPE payara-web-app PUBLIC "-//Payara.fish//DTD Payara Server 4 Servlet 3.0//EN" "https://raw.githubusercontent.com/payara/Payara-Server-Documentation/master/schemas/payara-web-app_4.dtd"> <payara-web-app> <context-root>/</context-root> </payara-web-app>
Both also support configuring the context path of the application within their admin console. IMHO this less convenient than the .xml file solution.
Deploying to root context: Open Liberty
Open Liberty also parses a proprietary web.xml file within src/main/webapp/WEB-INF: ibm-web-ext.xml
<web-ext xmlns="http://websphere.ibm.com/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://websphere.ibm.com/xml/ns/javaee http://websphere.ibm.com/xml/ns/javaee/ibm-web-ext_1_0.xsd" version="1.0"> <context-root uri="/"/> </web-ext>
Furthermore, you can also configure the context of your application within your server.xml:
<server>
<featureManager>
<feature>servlet-4.0</feature>
</featureManager>
<httpEndpoint id="defaultHttpEndpoint" httpPort="9080" httpsPort="9443"/>
<webApplication location="app.war" contextRoot="/" name="app"/>
</server>
Deploying to root context: WildFly
WildFly also has two simple ways of configuring the root context for your application. First, you can place a jboss-web.xml within src/main/webapp/WEB-INF:
<!DOCTYPE jboss-web PUBLIC "-//JBoss//DTD Web Application 2.4//EN" "http://www.jboss.org/j2ee/dtd/jboss-web_4_0.dtd"> <jboss-web> <context-root>/</context-root> </jboss-web>
Second, while copying your .war file to your Docker container, you can name it ROOT.war:
FROM jboss/wildfly ADD target/app.war /opt/jboss/wildfly/standalone/deployments/ROOT.war
For more tips & tricks for each application server, have a look at my cheat sheet.
Have fun deploying your Jakarta EE applications to the root context,
Phil
The post Deploy a Jakarta EE application to the root context appeared first on rieckpil.
April 08, 2019

Specification Scope in Jakarta EE
by waynebeaton at April 08, 2019 02:56 PM
With the Eclipse Foundation Specification Process (EFSP) a single open source specification project has a dedicated project team of committers to create and maintain one or more specifications. The cycle of creation and maintenance extends across multiple versions of the specification, and so while individual members may come and go, the team remains and it is that team that is responsible for the every version of that specification that is created.
The first step in managing how intellectual property rights flow through a specification is to define the range of the work encompassed by the specification. Per the Eclipse Intellectual Property Policy, this range of work (referred to as the scope) needs to be well-defined and captured. Once defined, the scope is effectively locked down (changes to the scope are possible but rare, and must be carefully managed; the scope of a specification can be tweaked and changed, but doing so requires approval from the Jakarta EE Working Group’s Specification Committee).
Regarding scope, the EFSP states:
Among other things, the Scope of a Specification Project is intended to inform companies and individuals so they can determine whether or not to contribute to the Specification. Since a change in Scope may change the nature of the contribution to the project, a change to a Specification Project’s Scope must be approved by a Super-majority of the Specification Committee.
As a general rule, a scope statement should not be too precise. Rather, it should describe the intention of the specification in broad terms. Think of the scope statement as an executive summary or “elevator pitch”.
Elevator pitch: You have fifteen seconds before the elevator doors open on your floor; tell me about the problem your specification addresses.
The scope statement must answer the question: what does an implementation of this specification do? The scope statement must be aspirational rather than attempt to capture any particular state at any particular point-in-time. A scope statement must not focus on the work planned for any particular version of the specification, but rather, define the problem space that the specification is intended to address.
For example:
Jakarta Batch provides describes a means for executing and managing batch processes in Jakarta EE applications.
and:
Jakarta Message Service describes a means for Jakarta EE applications to create, send, and receive messages via loosely coupled, reliable asynchronous communication services.
For the scope statement, you can assume that the reader has a rudimentary understanding of the field. It’s reasonable, for example, to expect the reader to understand what “batch processing” means.
I should note that the two examples presented above are just examples of form. I’m pretty sure that they make sense, but defer to the project teams to work with their communities to sort out the final form.
The scope is “sticky” for the entire lifetime of the specification: it spans versions. The plan for any particular development cycle must describe work that is in scope; and at the checkpoint (progress and release) reviews, the project team must be prepared to demonstrate that the behavior described by the specifications (and tested by the corresponding TCK) cleanly falls within the scope (note that the development life cycle of specification project is described in Eclipse Foundation Specification Process Step-by-Step).
In addition the specification scope which is required by the Eclipse Intellectual Property Policy and EFSP, the specification project that owns and maintains the specification needs a project scope. The project scope is, I think, pretty straightforward: a particular specification project defines and maintains a specification.
For example:
The Jakarta Batch project defines and maintains the Jakarta Batch specification and related artifacts.
Like the specification scope, the project scope should be aspirational. In this regard, the specification project is responsible for the particular specification in perpetuity. Further the related artifacts, like APIs and TCKs can be in scope without actually being managed by the project right now.
Today, for example, most of the TCKs for the Jakarta EE specifications are rolled into the Jakarta EE TCK project. But, over time, this single monster TCK may be broken up and individual TCKs moved to corresponding specification projects. Or not. The point is that regardless of where the technical artifacts are currently maintained, they may one day be part of the specification project, so they are in scope.
I should back up a bit and say that our intention right now is to turn the “Eclipse Project for …” projects that we have managing artifacts related to various specifications into actual specification projects. As part of this effort, we’ll add Git repositories to these projects to provide a home for the specification documents (more on this later). A handful of these proto-specification projects currently include artifacts related to multiple specifications, so we’ll have to sort out what we’re going to do about those project scope statements.
We might consider, for example, changing the project scope of the Jakarta EE Stable APIs (note that I’m guessing a future new project name) to something simple like:
Jakarta EE Stable APIs provides a home for stable (legacy) Jakarta EE specifications and related artifacts which are no longer actively developed.
But, all that talk about specification projects aside, our initial focus needs to be on describing the scope of the specifications themselves. With that in mind, the EE4J PMC has created a project board with issues to track this work and we’re going to ask the project teams to start working with their communities to put these scope statements together. If you have thoughts regarding the scope statements for a particular specification, please weigh in.
Note that we’re in a bit of a weird state right now. As we engage in a parallel effort to rename the specifications (and corresponding specification projects), it’s not entirely clear what we should call things. You’ll notice that the issues that have been created all use the names that we guess we’re going to end up using (there’s more more information about that in Renaming Java EE Specifications for Jakarta EE).
April 04, 2019
Renaming Java EE Specifications for Jakarta EE
by waynebeaton at April 04, 2019 02:17 PM
It’s time to change the specification names…
When we first moved the APIs and TCKs for the Java EE specifications over to the Eclipse Foundation under the Jakarta EE banner, we kept the existing names for the specifications in place, and adopted placeholder names for the open source projects that hold their artifacts. As we prepare to engage in actual specification work (involving an actual specification document), it’s time to start thinking about changing the names of the specifications and the projects that contain their artifacts.
Why change? For starters, it’s just good form to leverage the Jakarta brand. But, more critically, many of the existing specification names use trademarked terms that make it either very challenging or impossible to use those names without violating trademark rules. Motivation for changing the names of the existing open source projects that we’ll turn into specification projects is, I think, a little easier: “Eclipse Project for …” is a terrible name. So, while the current names for our proto-specification projects have served us well to-date, it’s time to change them. To keep things simple, we recommend that we just use the name of the specification as the project name.
With this in mind, we’ve come up with a naming pattern that we believe can serve as a good starting point for discussion. To start with, in order to keep things as simple as possible, we’ll have the project use the same name as the specification (unless there is a compelling reason to do otherwise).
The naming rules are relatively simple:
- Replace “Java” with “Jakarta” (e.g. “Java Message Service” becomes “Jakarta Message Service”);
- Add a space in cases where names are mashed together (e.g. “JavaMail” becomes “Jakarta Mail”);
- Add “Jakarta” when it is missing (e.g. “Expression Language” becomes “Jakarta Expression Language”); and
- Rework names to consistently start with “Jakarta” (“Enterprise JavaBeans” becomes “Jakarta Enterprise Beans”).
This presents us with an opportunity to add even more consistency to the various specification names. Some, for example, are more wordy or descriptive than others; some include the term “API” in the name, and others don’t; etc.
We’ll have to sort out what we’re going to do with the Eclipse Project for Stable Jakarta EE Specifications, which provides a home for a small handful of specifications which are not expected to change. I’ll personally be happy if we can at least drop the “Eclipse Project for” from the name (“Jakarta EE Stable”?). We’ll also have to sort out what we’re going to do about the Eclipse Mojarra and Eclipse Metro projects which hold the APIs for some specifications; we may end up having to create new specification projects as homes for development of the corresponding specification documents (regardless of how this ends up manifesting as a specification project, we’re still going to need specification names).
Based on all of the above, here is my suggested starting point for specification (and most project) names (I’ve applied the rules described above; and have suggested tweaks for consistency by strike out):
- Jakarta
APIsfor XML Messaging - Jakarta
Architecture forXML Binding - Jakarta
API forXML-basedWeb Services - Jakarta Common Annotations
- Jakarta Enterprise Beans
- Jakarta Persistence
API - Jakarta Contexts and Dependency Injection
- Jakarta EE Platform
- Jakarta
API forJSON Binding - Jakarta Servlet
- Jakarta
API forRESTful Web Services - Jakarta Server Faces
- Jakarta
API forJSON Processing - Jakarta
EESecurityAPI - Jakarta Bean Validation
- Jakarta Mail
- Jakarta Beans Activation
Framework - Jakarta Debugging Support for Other Languages
- Jakarta Server Pages Standard Tag Library
- Jakarta EE Platform Management
- Jakarta EE Platform Application Deployment
- Jakarta
API forXML Registries - Jakarta
API forXML-based RPC - Jakarta Enterprise Web Services
- Jakarta Authorization
Contract for Containers - Jakarta Web Services Metadata
- Jakarta Authentication
Service Provider Interface for Containers - Jakarta Concurrency Utlities
- Jakarta Server Pages
- Jakarta Connector Architecture
- Jakarta Dependency Injection
- Jakarta Expression Language
- Jakarta Message Service
- Jakarta Batch
- Jakarta
API forWebSocket - Jakarta Transaction
API
We’re going to couple renaming with an effort to capture proper scope statements (I’ll cover this in my next post). The Eclipse EE4J PMC Lead, Ivar Grimstad, has blogged about this recently and has created a project board to track the specification and project renaming activity (as of this writing, it has only just been started, so watch that space). We’ll start reaching out to the “Eclipse Project for …” teams shortly to start engaging this process. When we’ve collected all of the information (names and scopes), we’ll engage in a restructuring review per the Eclipse Development Process (EDP) and make it all happen (more on this later).
Your input is requested. I’ll monitor comments on this post, but it would be better to collect your thoughts in the issues listed on the project board (after we’ve taken the step to create them, of course), on the related issue, or on the EE4J PMC’s mailing list.
January 08, 2019
Top 20 Jakarta EE Experts to Follow on Twitter
by Elder Moraes at January 08, 2019 12:47 AM

This is the most viewed post of this blog, so I believe it deserves an update now in 2020! Its first version was written back in 2017.
There’s a lot of different opinions in this kind of lists, and there will be always somebody or something missing… just don’t be too passionate or take things personally, ok?! 
******************************************************
We all have to agree: there are tons of tons of information shared through social media. It’s no different on Twitter.
When we talk about staying tuned with some technology, it’s important to have some kind of focus. Otherwise, you could end up confused or, worst, getting bad and/or wrong information.
For these reasons I have a small but incredible list of people/accounts that I use to follow on Twitter to get really good information about Jakarta EE.
If you are passionate about Jakarta EE like me, I truly hope this list may be helpful to you. If you are not, I hope you enjoy as well!
Important: the list isn’t a ranking, so don’t judge the account by the position at the list. In fact, don’t judge anyone by anything…
Jakarta EE – @JakartaEE
The official Jakarta EE handle.
Wayne Beaton – @waynebeaton
Wayne is a Director of Open Source Projects at the Eclipse Foundation. Undoubtedly, Jakarta EE is one of the biggest projects at Eclipse today (if not the biggest one), so it’s important to stay tunned with Wayne has to say.
Adam Bien – @AdamBien
Adam works as a freelancer with Java since JDK 1.0, with Servlets/EJB since 1.0 and before the advent of J2EE in several large-scale applications. He is an architect and developer (with usually 20/80 distribution) in Java (SE / EE / FX) projects. He has written several books about JavaFX, J2EE, and Java EE, and he is the author of Real World Java EE Patterns—Rethinking Best Practices and Real World Java EE Night Hacks—Dissecting The Business Tier.
He is also a Java Champion, NetBeans Dream Team Founding Member, Oracle ACE Director, Java Developer of the Year 2010 and has a huge amount of nominations as JavaOne Rockstar.
Kevin Sutter – @kwsutter
Kevin Sutter is the lead architect for the Jakarta EE and JPA solutions for WebSphere Application Server and the WebSphere Liberty Profile. He is also very active with Java and open-source strategies as they relate to IBM’s application middleware.
Ivar Grimstad – @ivar_grimstad
Ivar Grimstad is Java Champion, JUG Leader, JCP Spec Lead, EC and EG Member, NetBeans Dream Team and International Speaker.
He is the PMC (Project Management Committee) Lead of EE4J and Jakarta EE Developer Advocate at Eclipse Foundation.
David Blevins – @dblevins
David Blevins is the founder of Tomitribe and a veteran of open source Jakarta EE. He has been both implementing and defining Enterprise Java specifications for more than 10 years and has a strong drive to see it simple, testable, and as light as Java SE. Blevins is cofounder of OpenEJB (1999), Geronimo (2003), and TomEE (2011). He is a member of the EJB 3.0, EJB 3.1, EJB 3.2, Java EE 6, Java EE 7, and Java EE 8 Security Expert Groups, and a member of the Apache Software Foundation. Blevins is a contributing author to Component-Based Software Engineering: Putting the Pieces Together (Addison Wesley). Blevins is also a regular speaker at JavaOne, Devoxx, ApacheCon, OSCon, JAX, and other Java-focused conferences.
Otavio Santana – @otaviojava
Otávio Santana is a developer and enthusiast of open source. He is an evangelist and practitioner of agile philosophy and polyglot development in Brazil. Santana is a JUG leader of JavaBahia and SouJava, and a strong supporter of Java communities in Brazil, where he also leads the BrasilJUGs initiative to incorporate Brazilian JUGs into joint activities.
He is also the co-creator of Jakarta NoSQL, a Java framework that streamlines the integration of Java applications with NoSQL databases. It defines a set of APIs to interact with NoSQL databases and provides a standard implementation for most NoSQL databases. This helps to achieve very low coupling with the underlying NoSQL technologies used.
Java Champions – @Java_Champions
Well, why the Java Champions handle is here? Because many Java Champions are Jakarta EE experts, so following the official Twitter is nice to be in touch with what they are saying about it.
Alex Theedom – @alextheedom
Trainer, Java Champion, Jakarta EE spec committee, author of Jakarta EE books and courses. Conference speaker and blogger.
OmniFaces – @OmniFaces
OmniFaces is a utility library for JSF 2 that focusses on utilities that ease everyday tasks with the standard JSF API. OmniFaces is a response to frequently recurring problems encountered during ages of professional JSF development and from questions being asked on Stack Overflow.
Dmitry Kornilov – @m0mus
Dmitry has over 20 years of experience in design and implementation of complex software systems, defining systems architecture, team leading and project management. He has worked as project leader of EclipseLink and Yasson and as spec lead of JSON-P and JSON-B specifications.
Steve Millidge – @l33tj4v4
Steve is the Founder and Director of Payara and C2B2 Consulting. Having used Java extensively since pre1.0, Steve has over 15 years’ experience as a field-based Professional Service Consultant along with extensive knowledge of Java middleware.
Before running his own business, Steve worked for Oracle as a Principal Consultant in Oracle’s Technology Architecture Practice, specializing in Business Process Integration and scalable n-tier component architectures.
Emily Jiang – @emilyfhjiang
Emily is a Java Champion and has been working on MicroProfile since 2016. She also leads the specifications of MicroProfile Config, Fault Tolerance and Service Mesh. She works for IBM as Liberty Architect for MicroProfile and CDI and is heavily involved in Java EE implementation in Liberty releases.
Arjan Tijms – @arjan_tijms
Arjan is a Jakarta EE committer and member of the Jakarta EE Steering Committee.
MicroProfile – @MicroProfileIO
MicroProfile is a baseline platform definition that optimizes Enterprise Java for a microservices architecture and delivers application portability across multiple MicroProfile runtimes. The initially planned baseline is JAX-RS + CDI + JSON-P, with the intent of the community having an active role in the MicroProfile definition and roadmap.
Sebastian Daschner – @DaschnerS
Sebastian has been working with Java enterprise software development for many years. Besides his work for clients, he set a high priority in educating developers in conference presentations, video courses, and training. He believes that teaching others not only greatly improves their situation but also educates yourself.
David Heffelfinger – @ensode
David R. Heffelfinger is an independent consultant based in the greater Washington DC area. He has authored several books on Java EE and related technologies. Heffelfinger has been architecting, designing, and developing software professionally since 1995. He has been using Java as his primary programming language since 1996. He has worked on many large-scale projects for several clients, including the US Department of Homeland Security, Freddie Mac, Fannie Mae, and the US Department of Defense. He has a master’s degree in software engineering from Southern Methodist University, Dallas, Texas. Heffelfinger is a frequent speaker at Java conferences such as Oracle Code One (forme JavaOne).
John Clingan – @jclingan
John is Product Manager at Red Hat and an ex Java EE PM. He is also a MicroProfile co-founder.
Josh Juneau – @javajuneau
Josh Juneau works as an application developer, system analyst, and database administrator. He is active in many fields of application development but primarily focuses on Jakarta EE. Juneau is a technical writer for Oracle Technology Network, Java Magazine, and Apress. He is a member of the NetBeans Dream Team, the JCP, and a part of the JSR 372 Expert Group. He enjoys working with the Java community—he is the director of meetings for the Chicago Java User Group.
Tanja Obradovic – @TanjaEclipse
Tanja is the Jakarta EE Program Manager at Eclipse Foundation.


