J2ME, bluetooth, speech recognition, automation ChatGPT. Also checkout the book: javachatgptbook.comis available for download.
<featureManager>
<feature>restfulWS-4.0</feature>
</featureManager>
Want to explore the potential of ARM (Advanced RISC Machine) architecture for your Jakarta EE workload? Our latest webinar 'Jakarta EE with ARM: Enhance Performance and Efficiency in the Cloud' is now available to watch on-demand on https://www.crowdcast.io/c/jakarta-ee-with-arm-july-2024
Want to explore the potential of ARM (Advanced RISC Machine) architecture for your Jakarta EE workload? Our latest webinar 'Jakarta EE with ARM: Enhance Performance and Efficiency in the Cloud' is now available to watch on-demand on https://www.crowdcast.io/c/jakarta-ee-with-arm-july-2024
Subscribe to airhacks.fm podcast via: spotify| iTunes| RSS
J2ME, bluetooth, speech recognition, automation ChatGPT. Also checkout the book: javachatgptbook.comis available for download.
Welcome to issue number two hundred and thirty-eight of Hashtag Jakarta EE!
I have just arrived back home from JConf Dominica 2024, and have a couple of hours to pack my bags before heading out again for JCrete 2024. Busy times for a developer advocate, but so incredibly great to be able to connect with the Java communities all over the world.
From one island to the other…From @jconfdominicana to @JCreteUnconf
— Ivar Grimstad (@ivar_grimstad) July 20, 2024
STIJFK
CPH
(I don’t know if it was pure luck, or if the stars were aligned just right for me this time, but as it turned out, the only two days I was on the ground this week were the two days with Blue Screen of Death for the airlines.)

The first release candidate of Jakarta EE 11 will be published shortly. There are a couple of the specifications that have released service releases of their API artifacts, so we will gather these and release an RC1 of the Jakarta EE 11 APIs.
All the Jakarta EE 11 XML Schemas are publicly available at https://jakarta.ee/schemas/. Please check them out and let us know if you find something that needs to be corrected before the release is Final.

Another way of providing input, AND possibly winning a FREE T-shirt is to complete the 2024 Cloud Native Java Technical Survey.

A Java conference in the Dominican Republic sounds too good to be true. Well, I can tell you that it is a thing, and it is awesome! JConf Dominicana, The Caribbean Java Technologies Conference is organized by Java Dominicano, the Dominican Java User Group. It is a one-day conference with a half day of workshops the day before.
I hosted a 4-hour Jakarta EE workshop together with Eudris Cabrera. He provided Spanish translations of all the instructions for the participants and explained in Spanish where my English came short. We had a great time, and it looks like the participants enjoyed it as well if you judge from the happy faces in this photo.

Jakarta EE was very well represented at JConfDominicana this year. In addition to the workshop, Shabnam did a keynote titled Empowering Innovation: The Open Source Odyssey of Contribution and Collaboration with Jakarta EE.
The day before the conference, we went out to explore the city and ended up visiting a cigar factory where they had free tours of the facilities. It is amazing to see how cigars are hand-made this way. Our clothes will need a turn in the washer after the visit as almost everyone in there was smoking cigars while working.





It is always such a great experience to speak at conferences like JConfDominica that are organized by and for the local Java Community. I encourage everyone who employs Java developers anywhere in the world to support the local Java community.
Subscribe to airhacks.fm podcast via: spotify| iTunes| RSS
Project Panama, Vector API, Value Types, machine learning, benefits of nullability in API design and new datatypes like e.g. Float16 in Javais available for download.
In this tutorial, we will learn how to map your Data Transfer Objects (DTO) using the MapStruct framework and integrate it into a Jakarta EE application. Understanding DTO Objects DTO Objects are used to decouple the database model from the view that is transferred to the client. They are intended to be immutable objects, used ... Read more
The post How to Map Your DTO Objects with MapStruct appeared first on Mastertheboss.

Ready to explore the potential of ARM (Advanced RISC Machine) architecture for your Jakarta EE workload? Join our next free webinar:
Register: https://www.crowdcast.io/c/jakarta-ee-with-arm-july-2024
Ready to explore the potential of ARM (Advanced RISC Machine) architecture for your Jakarta EE workload? Join our next free webinar:
Register: https://www.crowdcast.io/c/jakarta-ee-with-arm-july-2024
The post AI Glossary for Java Developers appeared first on Thorben Janssen.
Most Java developers encounter problems when learning how to integrate AI into their applications using SpringAI, Langchain4J, or some other library. AI introduces many new terms, acronyms, and techniques you must understand to build a good system. I ran into the same issue when I started learning about AI. In this article, I did my...
The post AI Glossary for Java Developers appeared first on Thorben Janssen.
The 24.0.0.7-beta release introduces enhancements to Jakarta RESTful Web Services 4.0, including new API methods and media type values. It also includes enhanced HTTP request tracking and the beta release of the Audit 2.0 feature, which creates REST Handler records only when a REST Handler application is configured.
The Open Liberty 24.0.0.7-beta includes the following beta features (along with all GA features):
See also previous Open Liberty beta blog posts.
Jakarta RESTful Web Services provides a foundational API to develop web services based on the REST architectural pattern. The Jakarta Restful Web Services 4.0 update introduces several enhancements to make web service development more efficient and effective.
The new features, restfulWS-4.0 and restfulWSClient-4.0, are primarily aimed at application developers. This release brings incremental improvements to Jakarta RESTful Web Services. It provides the following new convenience API methods:
The containsHeaderString() method is added to ContainerRequestContext, ContainerResponseContext, and HttpHeaders to help determine whether a header contains a specified value.
The UriInfo.getMatchedResourceTemplate() method is a new addition that returns a full template for a request.
New MediaType values to handle specific media types are introduced, including APPLICATION_JSON_PATCH_JSON and APPLICATION_MERGE_PATCH_JSON.
These updates streamline the process of developing RESTful services. To implement these new features, add the following code to your server.xml file.
For the RESTful web services feature:
<featureManager>
<feature>restfulWS-4.0</feature>
</featureManager>For the RESTful web services client feature:
<featureManager>
<feature>restfulWSClient-4.0</feature>
</featureManager>For more information, see the Jakarta RESTful Web Services 4.0 specification and the Javadoc.
Open Liberty introduces a significant update that enhances the tracking of HTTP connections that are made to the server. With the Monitor-1.0 feature (monitor-1.0) and any Jakarta EE 10 feature that uses the servlet engine, Open Liberty can now record detailed information about HTTP requests into an HttpStatsMXBean. This includes the request method, response status, duration, HTTP route, and other attributes that align with the Open Telemetry HTTP metric semantic convention.
If the mpMetrics-5.0 or mpMetrics-5.1 feature is also active, Open Liberty creates corresponding HTTP metrics, such as http.server.request.duration, using a Timer type metric. To use these metrics effectively, configure histogram buckets explicitly for Timer and Histogram type metrics by using the MicroProfile Metrics feature. For more details, see the mp.metrics.distribution.timer.buckets property on the MicroProfile Config Properties page.
This update ensures that operations teams responsible for monitoring can now have a detailed and comprehensive view of HTTP requests, enhancing the monitoring and management capabilities within Open Liberty environments.
Previously, Open Liberty tracked servlet and JAX-RS/RESTful resource requests to the server as separate MBeans (servlet MBeans and REST MBeans). This data might then be forwarded to the mpMetrics feature to create corresponding metrics. Monitoring tools like Prometheus and Grafana could visualize this metric data to showcase server performance and responsiveness.
With the new update, HTTP connections are now tracked more comprehensively, combining request details into a unified HttpStatsMXBean. This approach simplifies monitoring and provides a more cohesive view of server performance, making it easier for operations teams to ensure optimal server responsiveness.
This enhancement is an auto-feature that activates with monitor-1.0 and any feature that uses the servlet engine currently supporting Jakarta EE 10 features like servlet-6.0, pages-3.1, and restfulWS-3.1. It also supports registering HTTP metrics with mpMetrics-5.x features. To enable this function, add the following to your server.xml file:
<featureManager>
<feature>monitor-1.0</feature>
<feature>servlet-6.0</feature>
<feature>mpMetrics-5.0</feature>
</featureManager>For detailed configuration, see the MicroProfile Config Properties page.
For more information about the HTTP semantic convention used, see the Open Telemetry HTTP semantic convention page.
Jakarta Faces is a Model-View-Controller (MVC) framework for building web applications, offering many convenient features, such as state management and input validation. The Jakarta Faces 4.1 (faces-4.1) update introduces a range of incremental improvements to enhance the developer experience. These enhancements include increased use of generics in FacesMessages and other locations, as well as improved CDI integration by requiring events for @Initialized, @BeforeDestroyed, and @Destroyed for built-in scopes like FlowScoped and ViewScoped. The current Flow can also now be injected into a backing bean. Finally, a new UUIDConverter is added to the API, which simplifies the handling of UUIDs.
This update also includes some deprecations and removals. The composite:extension tag and references to the Security Manager are removed, and the full state saving mechanism is deprecated. To enable the Jakarta Faces 4.1 feature in your application, add the following to your server.xml file:
<featureManager>
<feature>faces-4.1</feature>
</featureManager>For more information, see the Jakarta Faces 4.1 specification and the Javadoc.
The Audit 2.0 feature (audit-2.0) is now in beta release. The feature is designed for users that are not using REST Handler applications.
It provides the same audit records as the Audit 1.0 feature (audit-1.0) but it does not generate records for REST Handler applications.
Customers that need to keep audit records for REST Handler applications must continue to use the Audit 1.0 feature.
To enable the Audit 2.0 feature in your application, add the following to your server.xml file:
<featureManager>
<feature>audit-2.0</feature>
</featureManager>To try out these features, update your build tools to pull the Open Liberty All Beta Features package instead of the main release. The beta works with Java SE 21, Java SE 17, Java SE 11, and Java SE 8.
If you’re using Maven, you can install the All Beta Features package using:
<plugin>
<groupId>io.openliberty.tools</groupId>
<artifactId>liberty-maven-plugin</artifactId>
<version>3.10.3</version>
<configuration>
<runtimeArtifact>
<groupId>io.openliberty.beta</groupId>
<artifactId>openliberty-runtime</artifactId>
<version>24.0.0.7-beta</version>
<type>zip</type>
</runtimeArtifact>
</configuration>
</plugin>You must also add dependencies to your pom.xml file for the beta version of the APIs that are associated with the beta features that you want to try. For example, the following block adds dependencies for two example beta APIs:
<dependency>
<groupId>org.example.spec</groupId>
<artifactId>exampleApi</artifactId>
<version>7.0</version>
<type>pom</type>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>example.platform</groupId>
<artifactId>example.example-api</artifactId>
<version>11.0.0</version>
<scope>provided</scope>
</dependency>Or for Gradle:
buildscript {
repositories {
mavenCentral()
}
dependencies {
classpath 'io.openliberty.tools:liberty-gradle-plugin:3.8.3'
}
}
apply plugin: 'liberty'
dependencies {
libertyRuntime group: 'io.openliberty.beta', name: 'openliberty-runtime', version: '[24.0.0.7-beta,)'
}Or if you’re using container images:
FROM icr.io/appcafe/open-liberty:betaOr take a look at our Downloads page.
If you’re using IntelliJ IDEA, Visual Studio Code or Eclipse IDE, you can also take advantage of our open source Liberty developer tools to enable effective development, testing, debugging and application management all from within your IDE.
For more information on using a beta release, refer to the Installing Open Liberty beta releases documentation.
Let us know what you think on our mailing list. If you hit a problem, post a question on StackOverflow. If you hit a bug, please raise an issue.
The post How to define a repository with Jakarta Data and Hibernate appeared first on Thorben Janssen.
Repositories are a commonly used pattern for persistence layers. They abstract from the underlying data store or persistence framework and hide the technical details from your business code. Using Jakarta Data, you can easily define such a repository as an interface, and you’ll get an implementation of it based on Jakarta Persistence or Jakarta NoSQL....
The post How to define a repository with Jakarta Data and Hibernate appeared first on Thorben Janssen.
The Generational Z Garbage Collector (GenZGC) in JDK 21 represents a significant evolution in Java’s approach to garbage collection, aiming to enhance application performance through more efficient memory management. This advancement builds upon the strengths of the Z Garbage Collector (ZGC) by introducing a generational approach to garbage collection within the JVM.
Generational Hypothesis: Generational ZGC leverages the “weak generational hypothesis,” which posits that most objects die young. By dividing the heap into young and old regions, GenZGC can focus its efforts on the young region where most objects become unreachable, thereby optimizing garbage collection efficiency and reducing CPU overhead
Heap Division and Collection Cycles: The heap is divided into two logical parts: the young generation and the old generation. Newly allocated objects are placed in the young generation, which is frequently scanned for garbage collection. Objects that survive several collection cycles are then promoted to the old generation, which is scanned less often. This division allows for more frequent collection of short-lived objects while reducing the overhead of collecting long-lived objects.
Throughput and Latency Internal performance tests have shown that Generational ZGC offers about a 10% improvement in throughput over its single-generation predecessors in both JDK 17 and JDK 21, despite a slight regression in average latency measured in microseconds. However, the most notable improvement is observed in maximum pause times, with a 10-20% improvement in P99 pause times. This reduction in pause times significantly enhances the predictability and responsiveness of applications, particularly those requiring low latency.
A crucial advantage of Generational ZGC is its ability to mitigate allocation stalls, which occur when the rate of object allocation outpaces the garbage collector’s ability to reclaim memory. This capability is particularly beneficial in high-throughput applications, such as those using Apache Cassandra, where Generational ZGC maintains performance stability even under high concurrency levels.
Transition and Adoption: While JDK 21 introduces Generational ZGC, single-generation ZGC remains the default for now. Developers can opt into using Generational ZGC through JVM arguments (`-XX:+UseZGC -XX:+ZGenerational`). The plan is for Generational ZGC to eventually become the default, with single-generation ZGC being deprecated and removed. This phased approach allows developers to gradually adapt to the new system.
Diagnostic and Profiling Tools: For those evaluating or transitioning to Generational ZGC, tools like GC logging and JDK Flight Recorder (JFR) offer valuable insights into GC behavior and performance. GC logging, accessible via the `-Xlog` argument, and JFR data can be analyzed in JDK Mission Control (JMC) to assess garbage collection behavior and application performance implications.
Generational ZGC represents a significant step forward in Java’s garbage collection technology, offering improved throughput, reduced pause times, and enhanced overall application performance. Its design reflects a deep understanding of application memory management needs, particularly the efficient collection of short-lived objects. As Java applications continue to grow in complexity and scale, the adoption of Generational ZGC could be a pivotal factor in achieving the performance goals of modern, high-demand applications.
The transition from Java 17 to Java 21 heralds a new era of Java development, characterized by significant improvements in performance, security, and developer-friendly features. The API changes and enhancements discussed above are just the tip of the iceberg, with Java 21 offering a wealth of other features and improvements designed to cater to the evolving needs of modern application development. As developers, embracing Java 21 and leveraging its new features and improvements can significantly impact the efficiency, performance, and security of Java applications. Whether it’s through the enhanced I/O capabilities, improved serialization exception handling, or the new Unicode support in the `Character` class, Java 21 offers a compelling upgrade path from Java 17, promising to enhance the Java ecosystem for years to come. In conclusion, the evolution from Java 17 to Java 21 is a testament to the ongoing commitment to advancing Java as a language and platform. By exploring and adopting these new features, developers can ensure their Java applications remain cutting-edge, secure, and performant in the face of future challenges.
As we all know, Java is a constantly evolving programming language. With each new release, we get a plethora of new features, enhancements, and sometimes, a few deprecations. In this blog post, we will analyse the significant differences between Java 17 and Java 21 API. We will navigate through the changes, with a focus on deprecated features, new library additions, security enhancements, and performance improvements.
Released on September 19, 2023, Java 21 is celebrated for its comprehensive set of specifications that define the behaviour of the Java language, API, and virtual machine. It represents a Long Term Support (LTS) version, ensuring extended updates and support from various vendors, making it a pivotal release for developers and organizations alike.
One of the key aspects of Java’s evolution is the deprecation of features that are no longer relevant or have been replaced by more efficient alternatives. In the transition from Java 17 to Java 21, several features, methods and classes have been deprecated or removed. These are the following:
ObjectOutputStream.PutFieldwrite(ObjectOutput) – Marked for removalEnum.finalize() – Deprecated and marked for removalRuntime.exec(String) – DeprecatedRuntime.exec(String, String[]) – DeprecatedRuntime.exec(String, String[], File) – DeprecatedRuntime.runFinalization() – Deprecated and marked for removalSystem.runFinalization() – Deprecated and marked for removalThreadDeath – Deprecated and marked for removalThreadGroup.allowThreadSuspension(boolean) – RemovedThread.countStackFrames() – RemovedThread.getId() – DeprecatedThread.resume() – RemovedThread.stop() – Marked for removalThread.suspend() – RemovedURL(String) – DeprecatedURL(String, String, String) – DeprecatedURL(String, String, int, String) – DeprecatedURL(String, String, int, String, URLStreamHandler) – DeprecatedURL(URL, String) – DeprecatedURL(URL, String, URLStreamHandler) – Deprecatedjava.security.spec.PSSParameterSpec.DEFAULT – DeprecatedPSSParameterSpec(int) – DeprecatedMemoryMXBean.getObjectPendingFinalizationCount() – DeprecatedAlso the following Classes were removed
ClassSpecializer.FactoryClassSpecializer.SpeciesDataCompilerFdLibm.CbrtFdLibm.HypotFdLibm.PowMLetContentMLetPrivateMLetMLetMBeanjavax.management.remote.rmi.RMIConnector.getMBeanServerConnection(Subject)javax.management.remote.RMIIIOPServerImpljavax.management.remote.JMXConnector.getMBeanServerConnection(Subject)ProcessBuilder processBuilder = new ProcessBuilder(command, arguments); Process process = processBuilder.start(); // Handle process output and errors as needed
String threadName = Thread.currentThread().getName(); // Get current thread name boolean isThreadAlive = Thread.currentThread().isAlive(); // Check if thread is alive
URL url = new URL("https://example.com/", MyClassLoader.class.getClassLoader());Java 21 introduces several new features
Transitioning from `final` to `sealed`, this change in the Console class introduces more controlled subclassing, allowing developers to extend functionality within a restricted hierarchy
The introduction of the `charset()` method in `PrintStream` allows developers to ascertain the charset used by the PrintStream, enhancing support for internationalization.
Let’s see some specific usage scenarios where the new features and API changes introduced in Java 21 can be particularly beneficial. These scenarios will illustrate how developers can leverage these enhancements to address real-world development challenges.
Scenario: A developer is working on a network application that requires the efficient transfer of large files from a server to multiple clients. The application needs to maximize throughput and minimize latency.
Java 21 Solution: Utilize the `transferTo(OutputStream)` method in classes such as `BufferedInputStream` for efficient data transfer. This method allows for direct transfer of bytes between streams, reducing the overhead of copying data to an intermediate buffer.
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
public class FileServer {
public static void main(String[] args) throws IOException {
try (ServerSocket serverSocket = new ServerSocket( /* port number */ );
Socket clientSocket = serverSocket.accept();
BufferedInputStream fileInput = new BufferedInputStream(new FileInputStream("largeFile.bin"));
OutputStream clientOutput = clientSocket.getOutputStream()) {
fileInput.transferTo(clientOutput);
System.out.println("File transferred successfully to client.");
} catch (IOException e) {
e.printStackTrace();
}
}
}
Benefits: This approach minimizes the I/O overhead and system resource utilization, leading to faster file transfers and improved application performance.
Scenario: A development team is building a custom framework that relies heavily on reflection for dynamic operation. They need a way to debug and validate the access levels of various members (methods, fields, etc.) at runtime to ensure correct behavior.
Java 21 Solution: Use the `accessFlags()` method from reflective classes (`Method`, `Field`) to get detailed access level information. This can help in logging, debugging, or runtime validation of application components.
import java.lang.reflect.Method;
import java.lang.reflect.Modifier;
public class MyClassInspector {
public static void main(String[] args) throws ClassNotFoundException {
Class<?> clazz = Class.forName("MyClass"); // Replace "MyClass" with the actual class name
Method[] methods = clazz.getDeclaredMethods();
for (Method method : methods) {
int flags = method.getModifiers();
System.out.printf("Method: %s, Access Flags: %s%n", method.getName(), Modifier.toString(flags));
}
}
}
Benefits: This capability enhances debugging and introspection, allowing developers to programmatically check and handle access levels, leading to more robust and secure applications.
Scenario: A social media platform aims to enhance its text processing capabilities to better support emojis, ensuring that user-generated content including emojis is correctly validated and displayed across different devices.
Java 21 Solution: Leverage the expanded Unicode and emoji support in the `Character` class to identify, validate, and process emojis within user content.
String userComment = "Hello world!";
userComment.codePoints().forEach(cp -> {
if (Character.isEmoji(cp)) {
System.out.printf("Found an emoji: %s%n", new String(Character.toChars(cp)));
}
});
Benefits: By accurately processing emojis, the platform can enhance user experience, ensuring correct display and interaction with emojis across various devices and locales, thereby supporting global user engagement. ### Conclusion The scenarios outlined above demonstrate the practical application of Java 21’s new features in addressing common development challenges. Whether it’s through more efficient data handling, improved debugging and validation mechanisms, or enhanced support for global character sets and emojis, Java 21 provides developers with powerful tools to build more efficient, secure, and user-friendly applications. As Java continues to evolve, staying abreast of these changes and understanding how to apply them in real-world contexts is crucial for developers looking to maximize their productivity and leverage the full power of the Java platform.
The Generational Z Garbage Collector (GenZGC) in JDK 21 represents a significant evolution in Java’s approach to garbage collection. It builds upon the Z Garbage Collector (ZGC) by introducing a generational approach, aiming to enhance application performance through more efficient memory management.
Generational ZGC leverages the “weak generational hypothesis,” which suggests that most objects die young. By dividing the heap into young and old regions, GenZGC can focus on the young region where most objects become unreachable, thereby optimizing garbage collection efficiency and reducing CPU overhead. This division allows for more frequent collection of short-lived objects while reducing the overhead of collecting long-lived objects. Internal performance tests have shown that Generational ZGC offers about a 10% improvement in throughput over its single-generation predecessors. A crucial advantage is its ability to mitigate allocation stalls, which significantly benefits high-throughput applications.
While JDK 21 introduces Generational ZGC, single-generation ZGC remains the default for now. Developers can opt into using Generational ZGC through JVM arguments. The plan is for Generational ZGC to eventually become the default. Tools like GC logging and JDK Flight Recorder (JFR) offer valuable insights into GC behavior and performance for those evaluating or transitioning to Generational ZGC.
Generational ZGC represents a significant step forward in Java’s garbage collection technology, offering improved throughput, reduced pause times, and enhanced overall application performance. Its design reflects a deep understanding of application memory management needs. As Java applications continue to grow in complexity and scale, the adoption of Generational ZGC could be a pivotal factor in achieving the performance goals of modern, high-demand applications.
The transition from Java 17 to Java 21 heralds a new era of Java development, characterized by significant improvements in performance, security, and developer-friendly features. The API changes and enhancements discussed above are just the tip of the iceberg, with Java 21 offering a wealth of other features and improvements designed to cater to the evolving needs of modern application development. As developers, embracing Java 21 and leveraging its new features and improvements can significantly impact the efficiency, performance, and security of Java applications. Whether it’s through the enhanced I/O capabilities, improved serialization exception handling, or the new Unicode support in the `Character` class, Java 21 offers a compelling upgrade path from Java 17, promising to enhance the Java ecosystem for years to come. In conclusion, the evolution from Java 17 to Java 21 is a testament to the ongoing commitment to advancing Java as a language and platform. By exploring and adopting these new features, developers can ensure their Java applications remain cutting-edge, secure, and performant in the face of future challenges.
In this article, we will provide an overview of the upcoming Jakarta RESTful Web Services 4.0 features. We will show how to test the latest version of this API on WildFly and how to run some examples with it. What’s New in Jakarta REST 4.0: Key Features and Enhancements The latest Jakarta REST 4.0 release ... Read more
The post Getting started with Jakarta REST Services 4.0 appeared first on Mastertheboss.
The 24.0.0.6-beta release includes previews of the Jakarta Validation and Jakarta Data implementations, both of which are part of Jakarta EE 11. The release also includes enhancements for histogram and timer metrics in MicroProfile 3.0 and 4.0 and InstantOn support for distributed HTTP session caching.
The Open Liberty 24.0.0.6-beta includes the following beta features (along with all GA features):
See also previous Open Liberty beta blog posts.
Jakarta Validation provides a mechanism to validate constraints that are imposed on Java objects by using annotations. The most noticeable change in version 3.1 is the name change, from Jakarta Bean Validation to Jakarta Validation. This version also includes explicit support for validating Java record classes, which were added in Java 16. Records reduce much of the boilerplate code in simple data classes, and pair nicely with Jakarta Validation.
The following examples demonstrate the simplicity of defining a Java record with Jakarta Validation annotations, as well as performing validation.
In this example, an Employee record is defined with two fields, empid and email.
public record Employee(@NotEmpty String empid, @Email String email) {}The @NotEmpty annotation specifies that empid cannot be an empty string, while the @Email annotation specifies that the value for email must be a properly formatted email address.
In this example, a validator is created to check the specified Employee values against the constraints that were set in the previous example.
Employee employee = new Employee("12432", "mark@example.com");
Set<ConstraintViolation<Employee>> violations = validator.validate(employee);Jakarta Data is a new Jakarta EE specification being developed in the open that aims to standardize the popular Data Repository pattern across various providers. Open Liberty 24.0.0.6-beta includes the Jakarta Data 1.0 release candidate 1, which decouples sorting from pagination, improves the static metamodel, and completes the initial definition of Jakarta Data Query Language (JDQL).
The Open Liberty beta includes a test implementation of Jakarta Data that we are using to experiment with proposed specification features. You can try out these features and provide feedback to influence the Jakarta Data 1.0 specification as it continues to be developed. The test implementation currently works with relational databases and operates by redirecting repository operations to the built-in Jakarta Persistence provider.
Jakarta Data 1.0 Release Candidate 1 completes the definition of Jakarta Data Query Language (JDQL) as a subset of Jakarta Persistence Query Language (JPQL). JDQL allows basic comparison and update operations on a single type of entity (an entity identifier variable is not used), as well as the ability to perform deletion and count operations. Find operations in JDQL consist of SELECT, FROM, WHERE, and ORDER BY clauses, all of which are optional.
Jakarta Data 1.0 Release Candidate 1 decouples sorting from pagination, allowing you to request pages of results without needing to duplicate the specification of the entity type that is queried.
The static metamodel, which allows for more type-safe usage, is streamlined in Release Candidate 1 to allow the use of interface classes with constant fields to define the metamodel.
To use these capabilities, you need an Entity and a Repository.
Start by defining an entity class that corresponds to your data. With relational databases, the entity class corresponds to a database table and the entity properties (public methods and fields of the entity class) generally correspond to the columns of the table. An entity class can be:
Annotated with jakarta.persistence.Entity and related annotations from Jakarta Persistence
A Java class without entity annotations, in which case the primary key is inferred from an entity property that is named id or ends with Id and an entity property that is named version designates an automatically incremented version column.
You define one or more repository interfaces for an entity, annotate those interfaces as @Repository, and inject them into components by using @Inject. The Jakarta Data provider supplies the implementation of the repository interface for you.
The following example shows a simple entity:
@Entity
public class Product {
@Id
public long id;
public boolean isDiscounted;
public String name;
public float price;
@Version
public long version;
}Here is a repository that defines operations relating to the entity. Your repository interface can inherit from built-in interfaces, such as BasicRepository and CrudRepository, to gain various general-purpose repository methods for inserting, updating, deleting, and querying for entities. You can add methods to further customize it.
@Repository(dataStore = "java:app/jdbc/my-example-data")
public interface Products extends BasicRepository<Product, Long> {
@Insert
Product add(Product newProduct);
// query-by-method name pattern:
List<Product> findByNameIgnoreCaseContains(String searchFor, Order<Product> orderBy);
// parameter based query that does not require -parameters because it explicitly specifies the name
@Find
Page<Product> find(@By("isDiscounted") boolean onSale,
PageRequest pageRequest,
Order <Product> orderBy);
// find query in JDQL that requires compilation with -parameters to preserve parameter names
@Query("SELECT price FROM Product WHERE id=:productId")
Optional<Float> getPrice(long productId);
// update query in JDQL:
@Query("UPDATE Product SET price = price - (?2 * price), isDiscounted = true WHERE id = ?1")
boolean discount(long productId, float discountRate);
// delete query in JDQL:
@Query("DELETE FROM Product WHERE name = ?1")
int discontinue(String name);
}Observe that the repository interface includes type parameters in PageRequest<Product> and Order<Product>. These parameters help ensure that the page request and sort criteria are for a Product entity rather than some other entity. To accomplish this, you can optionally define a static metamodel class for the entity (or various IDEs might generate one for you after the 1.0 specification is released). Here is one that can be used with the Product entity:
@StaticMetamodel(Product.class)
public interface _Product {
String ID = "id";
String IS_DISCOUNTED = "isDiscounted";
String NAME = "name";
String PRICE = "price";
String VERSION = "version";
SortableAttribute<Product> id = new SortableAttributeRecord(ID);
SortableAttribute<Product> isDiscounted = new SortableAttributeRecord(IS_DISCOUNTED);
TextAttribute<Product> name = new TextAttributeRecord(NAME);
SortableAttribute<Product> price = new SortableAttributeRecord(PRICE);
SortableAttribute<Product> version = new SortableAttributeRecord(VERSION);
}The following example shows the repository and static metamodel being used:
@DataSourceDefinition(name = "java:app/jdbc/my-example-data",
className = "org.postgresql.xa.PGXADataSource",
databaseName = "ExampleDB",
serverName = "localhost",
portNumber = 5432,
user = "${example.database.user}",
password = "${example.database.password}")
public class MyServlet extends HttpServlet {
@Inject
Products products;
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
// Insert:
Product prod = ...
prod = products.add(prod);
// Find the price of one product:
price = products.getPrice(productId).orElseThrow();
// Find all, sorted:
List<Product> all = products.findByNameIgnoreCaseContains(searchFor, Order.by(
_Product.price.desc(),
_Product.name.asc(),
_Product.id.asc()));
// Find the first 20 most expensive products on sale:
Page<Product> page1 = products.find(onSale, PageRequest.ofSize(20), Order.by(
_Product.price.desc(),
_Product.name.asc(),
_Product.id.asc()));
...
}
}This release introduces MicroProfile Config properties for MicroProfile 3.0 and 4.0 that are used for configuring the statistics that are tracked and outputted by the histogram and timer metrics. These changes are already available in MicroProfile Metrics 5.1.
In previous MicroProfile Metrics 3.0 and 4.0 releases, histogram and timer metrics tracked only the following values:
Min/max recorded values
The sum of all values
The count of the recorded values
A static set of percentiles for the 50th, 75th, 95th, 98th, 99th and 99.9th percentile.
These values are output to the /metrics endpoint in Prometheus format.
The new properties can define a custom set of percentiles as well as custom set of histogram buckets for the histogram and timer metrics. Other new configuration properties can enable a default set of histogram buckets, including properties that define an upper and lower bound for the bucket set.
With these properties, you can define a semicolon-separated list of value definitions that use the following syntax:
<metric name>=<value-1>[,<value-2>…<value-n>]
Some properties can accept multiple values for a given metric name, while others can accept only a single value.
You can use an asterisk ( *) as a wildcard at the end of the metric name.
Property |
Description |
mp.metrics.distribution.percentiles |
Defines a custom set of percentiles for matching Histogram and Timer metrics to track and output. Accepts a set of integer and decimal values for a metric name pairing. Can be used to disable percentile output if no value is provided with a metric name pairing. |
mp.metrics.distribution.histogram.buckets |
Defines a custom set of (cumulative) histogram buckets for matching Histogram metrics to track and output. Accepts a set of integer and decimal values for a metric name pairing. |
mp.metrics.distribution.timer.buckets |
Defines a custom set of (cumulative) histogram buckets for matching Timer metrics to track and output. Accepts a set of decimal values with a time unit appended (that is, ms, s, m, h) for a metric name pairing. |
mp.metrics.distribution.percentiles-histogram.enabled |
Configures any matching Histogram or Timer metric to provide a large set of default histogram buckets to allow for percentile configuration with a monitoring tool. Accepts a true/false value for a metric name pairing. |
mp.metrics.distribution.histogram.max-value |
When percentile-histogram is enabled for a Timer, this property defines an upper bound for the buckets reported. Accepts a single integer or decimal value for a metric name pairing. |
mp.metrics.distribution.histogram.min-value |
When percentile-histogram is enabled for a Timer, this property defines a lower bound for the buckets reported. Accepts a single integer or decimal value for a metric name pairing. |
mp.metrics.distribution.timer.max-value |
When percentile-histogram is enabled for a Histogram, this property defines an upper bound for the buckets reported. Accepts a single decimal value with a time unit appended (that is, ms, s, m, h) for a metric name pairing. Accepts a single decimal value with a time unit appended (that is, ms, s, m, h) for a metric name pairing. |
mp.metrics.distribution.timer.min-value |
When percentile-histogram is enabled for a Histogram, this property defines a lower bound for the buckets reported. Accepts a single decimal value with a time unit appended (that is, ms, s, m, h) for a metric name pairing. |
You can define the mp.metrics.distribution.percentiles property similar to the following example.
mp.metrics.distribution.percentiles=alpha.timer=0.5,0.7,0.75,0.8;alpha.histogram=0.8,0.85,0.9,0.99;delta.*=
This property creates the alpha.timer timer metric to track and output the 50th, 70th, 75th, and 80th percentile values. The alpha.histogram histogram metric outputs the 80th, 85th, 90th, and 99th percentile values. Percentiles for any histogram or timer metric that matches with delta.* are disabled.
We’ll expand on this example and define histogram buckets for the alpha.timer timer metric by using the mp.metrics.distribution.timer.buckets property.
mp.metrics.distribution.timer.buckets=alpha.timer=100ms,200ms,1s
This configuration tells the metrics runtime to track and output the count of durations that fall within 0-100ms, 0-200ms and 0-1 seconds. This output is due to the histogram buckets working in a cumulative fashion.
The corresponding prometheus output for the alpha.timer metric at the /metrics REST endpoint is similar to the following example:
# TYPE application_alpha_timer_mean_seconds gauge
application_alpha_timer_mean_seconds 2.9700022497975187
# TYPE application_alpha_timer_max_seconds gauge
application_alpha_timer_max_seconds 5.0
# TYPE application_alpha_timer_min_seconds gauge
application_alpha_timer_min_seconds 1.0
# TYPE application_alpha_timer_stddev_seconds gauge
application_alpha_timer_stddev_seconds 1.9997750210918204
# TYPE alpha_timer_seconds histogram (1)
application_alpha_timer_seconds_bucket{le="0.1"} 0.0 (2)
application_alpha_timer_seconds_bucket{le="0.2"} 0.0 (2)
application_alpha_timer_seconds_bucket{le="1.0"} 1.0 (2)
application_alpha_timer_seconds_bucket{le="+Inf"} 2.0 (2) (3)
application_alpha_timer_seconds_count 2
application_alpha_timer_seconds_sum 6.0
application_alpha_timer_seconds{quantile="0.5"} 1.0
application_alpha_timer_seconds{quantile="0.7"} 5.0
application_alpha_timer_seconds{quantile="0.75"} 5.0
application_alpha_timer_seconds{quantile="0.8"} 5.0
| 1 | The Prometheus metric type is histogram. Both the quantiles/percentile and buckets are represented under this type. |
| 2 | The le tag represents less than and is for the defined buckets, which are converted to seconds. |
| 3 | Prometheus requires that a +Inf bucket counts all hits. |
Open Liberty InstantOn provides fast startup times for MicroProfile and Jakarta EE applications. With InstantOn, your applications can start in milliseconds, without compromising on throughput, memory, development-production parity, or Java language features. InstantOn uses the Checkpoint/Restore In Userspace (CRIU) feature of the Linux kernel to take a checkpoint of the JVM that can be restored later.
The 24.0.0.6-beta release provides InstantOn support for the JCache Session Persistence feature. This feature uses a JCache provider to create a distributed in-memory cache. Distributed session caching is achieved when the server is connected to at least one other server to form a cluster. Open Liberty servers can behave in the following ways in a cluster.
Client-server model: An Open Liberty server can act as the JCache client and connect to a dedicated JCache server.
Peer-to-Peer model: An Open Liberty server can connect with other Open Liberty servers that are also running with the JCache Session Persistence feature and configured to be part of the same cluster.
To enable JCache Session Persistence, the sessionCache-1.0 feature must be enabled in your server.xml file:
<feature>sessionCache-1.0</feature>You can configure the client/server model in the server.xml file, similar to the following example.
<library id="InfinispanLib">
<fileset dir="${shared.resource.dir}/infinispan" includes="*.jar"/>
</library>
<httpSessionCache cacheManagerRef="CacheManager"/>
<cacheManager id="CacheManager">
<properties
infinispan.client.hotrod.server_list="infinispan-server:11222"
infinispan.client.hotrod.auth_username="sampleUser"
infinispan.client.hotrod.auth_password="samplePassword"
infinispan.client.hotrod.auth_realm="default"
infinispan.client.hotrod.sasl_mechanism="PLAIN"
infinispan.client.hotrod.java_serial_whitelist=".*"
infinispan.client.hotrod.marshaller=
"org.infinispan.commons.marshall.JavaSerializationMarshaller"/>
<cachingProvider jCacheLibraryRef="InfinispanLib" />
</cacheManager>You can configure the peer-to-peer model in the server.xml file, similar to the following example.
<library id="JCacheLib">
<file name="${shared.resource.dir}/hazelcast/hazelcast.jar"/>
</library>
<httpSessionCache cacheManagerRef="CacheManager"/>
<cacheManager id="CacheManager" >
<cachingProvider jCacheLibraryRef="JCacheLib" />
</cacheManager>Note:
To provide InstantOn support for the peer-to-peer model by using Infinispan as a JCache Provider, you must use Infinispan 12 or later. You must also enable MicroProfile Reactive Streams 3.0 or later and MicroProfile Metrics 4.0 or later in the server.xml file, in addition to the JCache Session Persistence feature.
The environment can provide vendor-specific JCache configuration properties when the server is restored from the checkpoint. The following configuration uses server list, username, and password values as variables defined in the restore environment.
<httpSessionCache libraryRef="InfinispanLib">
<properties infinispan.client.hotrod.server_list="${INF_SERVERLIST}"/>
<properties infinispan.client.hotrod.auth_username="${INF_USERNAME}"/>
<properties infinispan.client.hotrod.auth_password="${INF_PASSWORD}"/>
<properties infinispan.client.hotrod.auth_realm="default"/>
<properties infinispan.client.hotrod.sasl_mechanism="PLAIN"/>
</httpSessionCache>To try out these features, update your build tools to pull the Open Liberty All Beta Features package instead of the main release. The beta works with Java SE 22, Java SE 21, Java SE 17, Java SE 11, and Java SE 8.
If you’re using Maven, you can install the All Beta Features package by using:
<plugin>
<groupId>io.openliberty.tools</groupId>
<artifactId>liberty-maven-plugin</artifactId>
<version>3.10.3</version>
<configuration>
<runtimeArtifact>
<groupId>io.openliberty.beta</groupId>
<artifactId>openliberty-runtime</artifactId>
<version>24.0.0.6-beta</version>
<type>zip</type>
</runtimeArtifact>
</configuration>
</plugin>You must also add dependencies to your pom.xml file for the beta version of the APIs that are associated with the beta features that you want to try. For example, the following block adds dependencies for two example beta APIs:
<dependency>
<groupId>org.example.spec</groupId>
<artifactId>exampleApi</artifactId>
<version>7.0</version>
<type>pom</type>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>example.platform</groupId>
<artifactId>example.example-api</artifactId>
<version>11.0.0</version>
<scope>provided</scope>
</dependency>Or for Gradle:
buildscript {
repositories {
mavenCentral()
}
dependencies {
classpath 'io.openliberty.tools:liberty-gradle-plugin:3.8.3'
}
}
apply plugin: 'liberty'
dependencies {
libertyRuntime group: 'io.openliberty.beta', name: 'openliberty-runtime', version: '[24.0.0.6-beta,)'
}Or if you’re using container images:
FROM icr.io/appcafe/open-liberty:betaOr take a look at our Downloads page.
If you’re using IntelliJ IDEA, Visual Studio Code or Eclipse IDE, you can also take advantage of our open source Liberty developer tools to enable effective development, testing, debugging, and application management all from within your IDE.
For more information on using a beta release, refer to the Installing Open Liberty beta releases documentation.
Let us know what you think on our mailing list. If you hit a problem, post a question on StackOverflow. If you hit a bug, please raise an issue.
In this article, you will learn about:
Initially, I anticipated the article would be short, but it ended up being quite lengthy. You could think of it as a missing chapter from the “Beginning Helidon” book I co-authored with my colleagues. Yes, it’s a bit cheesy to advertise the book in the first paragraph. You might assume that promoting the book was my sole motivation for writing this article. Admittedly, it’s a significant motivator, but not the only one.
In the Helidon support channels, we frequently encounter questions about migrating Spring Boot applications to Helidon. To address these inquiries, we concluded that creating a Helidon version of the well-known Spring Petclinic demo application and documenting the migration strategies and challenges would be the best approach. I volunteered for the task because of my previous experience with Spring programming and because I hadn’t engaged in real programming for quite some time, and I wanted to demonstrate that I still could. Whether I succeeded or not, you readers can decide after reviewing the work. Perhaps I shouldn’t have taken it on. You can find the result here. Anyway, enough philosophical musings; let’s get down to business.
When I began my research, I started with the original Spring Petclinic. However, it seemed a bit outdated to me, so I explored other Petclinic forks available at https://github.com/spring-petclinic. One that caught my attention was the Spring Petclinic Rest, which functions as a RESTful service. Its architecture aligns well with the concepts of Helidon. Additionally, it features an Angular-based UI in a separate project. The plan was to develop a Helidon-based backend to complement the frontend project for demonstration purposes.
The Spring Petclinic Rest project is thoroughly documented in its README.md. For convenience, I’ll provide some basic design concepts here:
openapi-generator-maven-plugin.There are two data models:
And three layers:
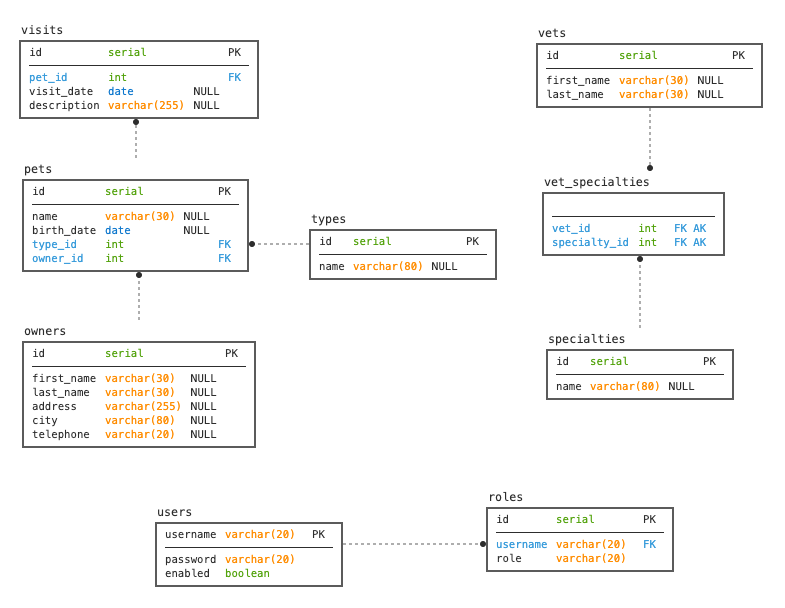
Helidon Petclinic is a project I created. You can check it out here. The README.md contains information about how to build and run it.
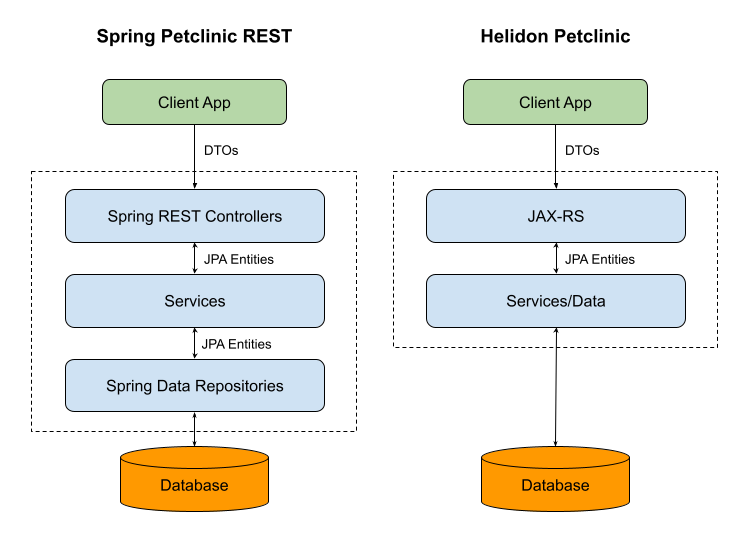
My goal was to preserve the design and structure of the application as much as possible. In the end, I achieved a layer structure very similar to the original. The only significant change is an optimization related to the database layer. I perform database operations in the service layer, effectively integrating it with the database layer. The original application’s service layer methods typically involved only a single line call to the data repository, so this made sense to me. I draw a picture (see below) to help you understand the difference.
Spring and Helidon are different frameworks. Spring is built around the proprietary Spring Injection. Although it integrates with some open-source libraries and standards, most of its features are Spring-specific. On the other hand, Helidon (Helidon MP) is built on top of Enterprise Java standards such as Jakarta EE and MicroProfile, which technically makes it more open. There is some overlap in third-party libraries. Both Spring and Helidon use JPA, which will make our database layer migration easier. Additionally, Jackson and Mockito can be used in both frameworks. But I would recommend using Jakarta equivalents of Jackson for better Jakarta compatibility. In the table below, I have listed Spring components and their corresponding Helidon equivalents, which I’ll use in my project.
| Spring | Helidon |
|---|---|
| Spring Injection | Jakarta Contexts and Dependency Injection (CDI) |
| Spring REST Controller | Jakarta RESTful Web Services (JAX-RS) |
| Spring Data | Jakarta Persistence (JPA) |
| Spring Open API generator | Helidon Open API generator |
| Spring Tests Framework | Helidon Tests |
| Jackson | Jakarta JSON Processing (JSON-P) and Jakarta JSON Binding (JSON-B) |
| Spring Configuration | MicroProfile Config |
I had to make some compromises. For simplicity’s sake, I only added support for HSQL. I also omitted security support. Basic Authentication with passwords stored in the database is not what I would recommend using; it falls far short of modern security standards. I may consider supporting security in future versions of the project if there is demand for it.
The JPA model comprises a set of JPA entities. JPA is a standard, and one of the beauties of standards is that you don’t need to alter things when migrating code to another runtime. I made only minor adjustments to these classes, mainly replacing Spring-specific features with their Helidon equivalents. I replaced the usage of ToStringCreator in toString() methods with code generated by my IDE (IntelliJ Idea rules!). Additionally, I replaced instances of PropertiesComparator.sort() with Collections.sort().
Spring code:
public List<Pet> getPets() {
List<Pet> sortedPets = new ArrayList<>(getPetsInternal());
PropertyComparator.sort(sortedPets,
new MutableSortDefinition("name", true, true));
return Collections.unmodifiableList(sortedPets);
}
Helidon code:
public List<Pet> getPets() {
var sortedPets = new ArrayList<>(getPetsInternal());
sortedPets.sort(Comparator.comparing(Pet::getName));
return Collections.unmodifiableList(sortedPets);
}
Another change I made was adding named queries to serve as a replacement for the Spring Data repositories. This is what I’ll discuss in the next section.
Spring Data is a part of the Spring framework designed for working with databases. Spring Data implements the repository pattern, which involves defining interfaces containing methods to retrieve data (entities or collections of entities). The framework automatically generates the implementation of these interfaces. Operations on data and search criteria are defined by method names. For instance, the Collection<Pet> findAll() method retrieves all pets, while void save(Pet pet) updates the given Pet object in the database. This abstraction eliminates the need to understand the underlying query language. While some may find it convenient, I personally prefer working with SQL statements as they are more intuitive to me. I suppose I’m just too old-fashioned.
To do this the Helidon way, I used JPQL queries, which I find preferable. In the service layer, rather than calling methods from repositories, I utilize the pure JPA API to achieve the same results.
First step is injecting the entity manager into ClinicServiceImpl:
@PersistenceContext(unitName = "pu1")
private EntityManager entityManager;
The entity manager will handle all database operations, which were previously handled by the repositories.
Next, I went through all methods and replaced repository usage with equivalent code using the entity manager, following certain patterns.
For find* methods a named query in the corresponding entity class has to be created and executed in the body of a method.
public List<Pet> findAllPets() {
return entityManager.createNamedQuery("findAllPets",
Pet.class).getResultList();
}
@NamedQueries({
@NamedQuery(name = "findAllPets",
query = "SELECT p FROM Pet p")
})
public class Pet extends NamedEntity {
...
}
The ClinicService.save* methods combine ‘create’ and ‘update’ functionality. However, JPA provides separate methods for creating and updating entities. Therefore, I needed to separate these operations in the code, as shown in the sample below.
@Transactional
public void saveOwner(Owner owner) {
if (owner.isNew()) {
entityManager.persist(owner);
} else {
entityManager.merge(owner);
}
}
The replacement of delete methods is straightforward, but there is one pitfall that users need to understand and know how to avoid. Here is a sample of how it’s done for most entities:
@Transactional
public void deleteOwner(Owner owner) {
entityManager.remove(owner);
}
However, for some entities, it needs to be handled differently. There are cases where an entity is dependent and managed by its parent entity. Such a relationship exists between the Owner and Pet entities. Owner contains a set of Pet entities annotated with cascade = CascadeType.ALL.
public class Owner extends Person {
@OneToMany(cascade = CascadeType.ALL,
mappedBy = "owner",
fetch = FetchType.EAGER,
orphanRemoval = true)
private Set<Pet> pets;
...
}
In this case, to remove a pet, instead of invoking entityManager.remove(pet), you need to delete it from the Owner.pets set and call entityManager.merge(owner).
@Transactional
public void deletePet(Pet pet) {
var owner = pet.getOwner();
owner.deletePet(pet);
entityManager.merge(owner);
entityManager.flush();
}
This is a legitimate use case. You can read more about it here.
The handling of transactions differs between Helidon and Spring. Spring utilizes Spring Transactions, while Helidon uses Jakarta Transactions (JTA). However, these two APIs are similar. The project employs declarative transactions, defined by placing the @Transactional annotation on methods that need to be executed within a transaction. I only replaced the import from org.springframework.transaction.annotation.Transactional to jakarta.transaction.Transactional. Additionally, since JTA does not support read-only transactions, I removed the readOnly = true parameter from Spring’s @Transactional annotation when present. Furthermore, I optimized the code by removing transaction support from methods that do not require transactions, such as methods that only read data from the database without writing to it.
Migrating REST controllers to Helidon is one of the complicated tasks. Source code is different because Helidon uses Jakarta RESTful Web Services (JAX-RS) and Spring uses proprietary libraries. I had to rewrite all REST controllers manually. There are some patterns which can be used, but it’s not as obvious as it is with data repositories.
@RequestScoped (1)
public class PetResource implements PetService { (2)
@Context (3)
UriInfo uriInfo;
private final ClinicService clinicService;
private final PetMapper petMapper;
@Inject (4)
public PetResource(ClinicService clinicService,
PetMapper petMapper) {
this.clinicService = clinicService;
this.petMapper = petMapper;
}
@Override
public Response addPet(PetDto petDto) { (5)
var owner = clinicService.findOwnerById(
petDto.getOwnerId()).orElseThrow();
var pet = petMapper.toPet(petDto);
pet.setOwner(owner);
clinicService.savePet(pet);
var location = UriBuilder
.fromUri(uriInfo.getBaseUri())
.path("api/pets/{id}")
.build(pet.getId());
return Response.created(location)
.entity(petMapper.toPetDto(pet))
.build();
}
...
}
<1> – Makes this class a request scoped CDI bean
<2> – Implements PetService generated interface. This interface contains JAX-RS annotations defining paths, HTTP methods, etc.
<3> – Injecting UriInfo class usng JAX-RS @Context annotation
<4> – Constructor injection of ClinicService and PetMapper
<5> – JAX-RS method used to add a pet
Remember that this project is API first and REST resources and the model classes it operates are generated from the OpenAPI document. All Rest controllers implement these generated interfaces. And these interfaces are different for Spring and Helidon.
I’ll explain the OpenAPI plugin configuration in the next section.
To generate code out of OpenAPI document, I used OpenAPI plugin provided by Helidon. I couldn’t use a plugin used in the original project because it generates the Spring code, which is not compatible with Helidon. You can find the plugin configuration in the project pom.xml file. I won’t go deep into the configuration. The only thing I mention is an option to skip generating data model tests. I couldn’t find it in documentation. The option is <generateModelTests>false</generateModelTests>.
There are some differences in how these two generators work. First difference I noticed is handling read only fields. Spring generator doesn’t do anything and treats read only fields as all other fields. It means that they are mutable and not read only. Helidon generator behaves differently. It treats read only fields as immutable fields. The values are passed as the constructor parameters and there are no setters. Which makes them truly immutable. On the other hand, it adds some complications when migrating from the Spring approach. The major issue is that no-args constructor cannot be used anymore when converting entities to DTOs. I’ll explain how to deal with it in Mapstruct section below.
Another issue I faced was different handling of tags. Helidon plugin uses tags to group operations into services.
In the Open API document tags are defined like this:
tags:
- name: owner
description: Endpoints related to pet owners.
- name: pet
description: Endpoints related to pets.
...
If you look at the paths, there is addPetToOwner operation at /owners/{ownerId}/pets with pet tag. All other Owner-related operations are tagged with owner.
paths:
/owners/{ownerId}:
get:
tags:
- owner
operationId: getOwner
/owners/{ownerId}/pets:
post:
tags:
- pet
operationId: addPetToOwner
summary: Adds a pet to an owner
description: Records the details of a new pet.
As result, Helidon generator places addPetToOwner method in PetService and all other Owner related methods to OwnerService. It causes paths collision because the base path of OwnerService is /owner and it supposed to handle all sub-paths too. But there is /owners/{ownerId}/pets handler in PetService.
I fixed it by changing a tag in /owners/{ownerId}/pets path to owner.
Mapstruct is a library for generating converters between Java beans. It’s based on an annotation processor and does generation at build-time. It’s used in the project to generate mappers between entities and DTOs. It can be configured for usage in Spring projects as well as in CDI based Jakarta EE projects. I used the second option because Helidon project is a CDI based application. To do it add the following to Mapstruct Maven plugin configuration:
<compilerArgs>
<compilerArg>
-Amapstruct.defaultComponentModel=jakarta-cdi
</compilerArg>
...
</compilerArgs>
One of the issues I had to solve with Mapstruct is making it work with DTOs generated by Helidon Open API generator. I mentioned above that Helidon generator doesn’t generate setters for fields marked as read only in the OpenAPI document. It generates a constructor with parameters where initial values of all read only fields must be passed. It requires a special treatment using object factories in Mapstruct. Technically, it requires creation of a factory class which describes how objects are created using non-default constructor.
The sample below contains two methods annotated with @ObjectFactory annotation. These methods will be used to create objects specified as their return types: createVetDto creates VetDto, createOwnerDto creates OwnerDto. Constructor arguments are passed as method parameters.
@ApplicationScoped
public class DtoFactory {
@ObjectFactory
public VetDto createVetDto(Vet vet) {
return new VetDto(vet.getId());
}
@ObjectFactory
public OwnerDto createOwnerDto(Owner owner) {
return new OwnerDto(owner.getId(), new ArrayList<>());
}
...
}
Object factory must be specified in @Mapper annotation uses parameter of the interface which creates that particular object as it’s shown in a snippet below.
@Mapper(uses = {DtoFactory.class, SpecialtyMapper.class})
public interface VetMapper {
VetDto toVetDto(Vet vet);
...
}
The original projects was nicely covered with tests, so my task was to do the same for my port. I rewrote the original tests and added tests for mappers and integration tests. Tests, the same as REST controllers, need to be reworked. The rework is smaller for the service tests and much bigger for Rest controllers tests.
All service layer tests are located in io.helidon.samples.petclinic.service. My project supports only one database rather than the original project supporting three databases, which makes the task easier. The tests perform real database operations in database allowing us to test all aspects of database operations including JPQL queries and CRUD operations. The tests look very similar to the original project tests. I copy/pasted the most of the code. The difference is that Spring supports transactions rollback after test method execution if the test method annotated with @Transactional. It’s very convenient because the database always kept unchanged. Helidon doesn’t have this feature, but I managed to simulate it by starting a user transaction before each method call and rolling it back after it. I collected all ‘transactional’ tests in ClinicServiceTransactionalTest class. All other tests which don’t change the data are in ClinicServiceTest class.
In the original Rest controller tests, mocking is utilized. Spring provides a nice MockMVC testing framework, which is Spring-specific. Consequently, I opted for pure Mockito. Personally, I’m not a huge fan of mocking because sometimes tests using mocks end up testing the mocks themselves rather than the actual logic. However, this isn’t true for all cases; mock tests run faster and developers are accustomed to them.
The typical Helidon mocking test class is demonstrated in the code snippet below. I utilize the @HelidonTest annotation to initiate a CDI container, in conjunction with the Mockito extension @ExtendWith(MockitoExtension.class).
Bootstrapping Mockito is slightly tricky because my JAX-RS resource uses constructor injection, and I also need to mock the field-injected UriInfo class. Mockito poorly supports the use case when both constructor and field injection are used. Consequently, I had to manually create mocks for constructor-injected classes and use declarative mocking with the @Mock annotation for field-injected UriInfo.
Despite these challenges, the test methods look like typical Mockito tests.
@HelidonTest
@ExtendWith(MockitoExtension.class)
public class PetResourceTest {
ClinicService clinicService;
@Inject
PetMapper petMapper;
@Mock
UriInfo uriInfo;
@InjectMocks
PetResource petResource;
@BeforeEach
void setup() {
clinicService = Mockito.mock(ClinicService.class);
petResource = new PetResource(clinicService, petMapper);
MockitoAnnotations.openMocks(this);
}
@Test
void testAddPet() {
var petDto = createPetDto();
var owner = createOwner();
Mockito.when(uriInfo.getBaseUri())
.thenReturn(URI.create("http://localhost:9966/petclinic"));
Mockito.when(clinicService.findOwnerById(1))
.thenReturn(Optional.of(owner));
var response = petResource.addPet(petDto);
assertThat(response.getStatus(), is(201));
assertThat(response.getLocation().toString(),
equalTo("http://localhost:9966/petclinic/api/pets/1"));
var pet = (PetDto) response.getEntity();
assertThat(pet.getId(), equalTo(petDto.getId()));
assertThat(pet.getName(), equalTo(petDto.getName()));
assertThat(pet.getOwnerId(), equalTo(petDto.getOwnerId()));
}
...
}
I’ve decided to include integration tests in the project. You can find them in the io.helidon.samples.petclinic.integration package. Ultimately, it’s the most robust way to test all application layers. I’ve utilized the Maven Failsafe plugin to execute the integration tests. Below is the failsafe plugin configuration:
<plugin>
<artifactId>maven-failsafe-plugin</artifactId>
<version>3.2.5</version>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
<goal>verify</goal>
</goals>
</execution>
</executions>
<configuration>
<classesDirectory>${project.build.directory}/classes</classesDirectory>
</configuration>
</plugin>
Please pay attention to the <classesDirectory>${project.build.directory}/classes</classesDirectory> configuration option. The plugin won’t function properly without it.
The typical integration test is illustrated in the snippet below. I’m using the @HelidonTest annotation to initiate a CDI container and the Helidon web server, and I’m injecting a web target pointing to the running web server. This is a feature of the Helidon testing framework. In the test methods, I call a REST endpoint, retrieve the result, and verify its correctness. This tests the entire chain of layers from the REST resource to the database.
@HelidonTest
class PetResourceIT {
@Inject
private WebTarget target;
@Test
void testListPets() {
var pets = target
.path("/petclinic/api/pets")
.request()
.get(JsonArray.class);
assertThat(pets.size(), greaterThan(0));
assertThat(pets.getJsonObject(0).getInt("id"),
is(1));
assertThat(pets.getJsonObject(0).getString("name"),
equalTo("Jacka"));
}
...
}
You can execute all integration tests using the mvn integration-test command.
I composed my summary as a small FAQ.
Is it possible to migrate a Spring project to Helidon?
Definitely yes.
Is it difficult?
Typically no, but it depends on the project. I spent about a day to migrate database and service layer, about 2 days to migrate REST controllers, about a week to migrate tests, and more than a week to write this article. At the end, testing and documenting work is more time-consuming than developing.
Is Helidon different from Spring?
Yes it is, but there are the same or similar components/frameworks/specs used in both, so if you know Spring, Helidon doesn’t look as an alien and visa versa.
What are the advantages of Helidon?
Helidon is based on Java 21 Virtual Threads and is very fast. It supports Jakarta EE and MicroProfile, so it’s a great choice if you are standards-minded.
Where I can find additional information about Helidon?
https://helidon.io and https://medium.com/helidon
If you’re thinking, “Hey, Dmitry! This is a brilliant article, I enjoyed reading it!” you can share a link to this article on social networks as an act of appreciation.
Thank you!
With the release of Jetty 12.0.8, we’re excited to announce the (re)implementation of a somewhat maligned and deprecated feature: Cross-Context Dispatch. This feature, while having been part of the Servlet specification for many years, has seen varied levels of use and support. Its re-introduction in Jetty 12.0.8, however, marks a significant step forward in our commitment to supporting the diverse needs of our users, especially those with complex legacy and modern web applications.
Cross-Context Dispatch allows a web application to forward requests to or include responses from another web application within the same Jetty server. Although it has been available as part of the Servlet specification for an extended period, it was deemed optional with Servlet 6.0 of EE10, reflecting its status as a somewhat niche feature.
Initially, Jetty 12 moved away from supporting Cross-Context Dispatch, driven by a desire to simplify the server architecture amidst substantial changes, including support for multiple environments (EE8, EE9, and EE10). These updates mean Jetty can now deploy web applications using either the javax namespace (EE8) or the jakarta namespace (EE9 and EE10), all using the latest optimized jetty core implementations of HTTP: v1, v2 or v3.
The decision to reintegrate Cross-Context Dispatch in Jetty 12.0.8 was influenced significantly by the needs of our commercial clients, some who still leveraging this feature in their legacy applications. Our commitment to supporting our clients’ requirements, including the need to maintain and extend legacy systems, remains a top priority.
One of the standout features of the newly implemented Cross-Context Dispatch is its ability to bridge applications across different environments. This means a web application based on the javax namespace (EE8) can now dispatch requests to, or include responses from, a web application based on the jakarta namespace (EE9 or EE10). This functionality opens up new pathways for integrating legacy applications with newer, modern systems.
The reintroduction of Cross-Context Dispatch in Jetty 12.0.8 is more than just a nod to legacy systems; it can be used as a bridge to the future of Java web development. By allowing for seamless interactions between applications across different Servlet environments, Jetty-12 opens the possibility of incremental migration away from legacy web applications.
This tutorial will show how to build a powerful combination: a React frontend that seamlessly interacts with data from a Jakarta EE REST backend application running as a WildFly bootable JAR. Prerequisites: Step # 1 Define the Rest Endpoint Firstly, bootstrap a Jakarta EE application. You can either use WildFly archetypes ( see Maven archetype ... Read more
The post Consuming Jakarta EE REST Services with React appeared first on Mastertheboss.
In this article, we will learn how to debug a Quarkus application using two popular Development Environments such as IntelliJ Idea and VS Studio. We’ll explore how these IDEs can empower you to effectively identify, understand, and resolve issues within your Quarkus projects. Enabling Debugging in Quarkus When running in development mode, Quarkus, by default, ... Read more
The post How to debug Quarkus applications appeared first on Mastertheboss.
In this article we will learn some of the available tools or plugins you can use to migrate your legacy Java EE/Jakarta EE 8 applications to the newer Jakarta EE environment. We will also discuss the common challenges that you can solve by using tools rather than performing a manual migration of your projects. Challenges ... Read more
The post Simplifying migration to Jakarta EE with tools appeared first on Mastertheboss.
Whether you’re a beginner exploring OpenShift for the first time or an experienced user looking for quick references, this cheat sheet is designed to provide you with a CheatSheet of OpenShift commands, concepts, and best practices. From managing pods and services to setting up routes and exploring advanced deployment strategies, we’ve got you covered. Login ... Read more
The post Openshift Cheatsheet for DevOps appeared first on Mastertheboss.
Jakarta Data API is a powerful specification that simplifies data access across a variety of database types, including relational and NoSQL databases. In this article you will learn how to leverage this programming model which will be part of Jakarta 11 bundle. Overview of Jakarta Data API Jakarta.Data API: Offers a higher-level abstraction for data ... Read more
The post Getting Started with Jakarta Data API appeared first on Mastertheboss.
This article will teach you how to use a plain Datasource resource in a Quarkus application. We will create a simple REST Endpoint and inject a Datasource in it to extract the java.sql.Connection object. We will also learn how to configure the Datasource pool size. Quarkus Connection Pool Quarkus uses Agroal as connection pool implementation ... Read more
The post How to use a Datasource in Quarkus appeared first on Mastertheboss.
Docker-compose allows you to access container ports in two different ways: using “ports” and “expose:”. In this tutorial we will learn what is the difference between “ports” and “expose:” providing clear examples. Before diving into the differences between “ports” and “expose”, we recommend checking this article if you are new to Docker-Compose: Orchestrate containers using ... Read more
The post Docker-compose: ports vs expose explained appeared first on Mastertheboss.
This article will detail how to get started quickly with Jakarta EE which is the new reference specification for Java Enterprise API. As most of you probably know, the Java EE moved from Oracle to the Eclipse Foundation under the Eclipse Enterprise for Java (EE4J) project. There are already a list of application servers which ... Read more
The post Getting started with Jakarta EE appeared first on Mastertheboss.
Setting up a GlassFish server cluster with an Apache HTTP server as a load balancer involves several steps:
We’ll assume that you’ve already configured GlassFish for clustering. If you haven’t done so, you can follow our guide on how to set up a GlassFish cluster to prepare your own GlassFish cluster. After you’ve prepared it, this tutorial will guide you to configure Apache HTTP Server as a load balancer with sticky sessions.
Install Apache HTTP Server on a machine that will act as the load balancer. This should be a separate machine from machines that run GlassFish cluster instances, mainly for security reasons. While your cluster should be accessible through the Apache server, GlassFish cluster instances shouldn’t be accessible publicly. Therefore, you should configure your firewall or networking rules to only allow access to GlassFish instances only from the Apache server.
On Apt-based systems, like Ubuntu or Debian, you can install Apache HTTP Server from the system repository with the following commands:
sudo apt update
sudo apt install apache2Enable the necessary proxy modules (proxy, proxy_http, proxy_balancer, and lbmethod_byrequests modules) in Apache server:
sudo a2enmod proxy
sudo a2enmod proxy_http
sudo a2enmod proxy_balancer
sudo a2enmod lbmethod_byrequestsEdit the Apache configuration file (usually located at /etc/apache2/sites-available/000-default.conf) and add the following configuration:
<VirtualHost *:80>
# Basic server configuration, use appropriate values according to your set up
ServerAdmin webmaster@localhost
ServerName yourdomain.com
# access and error log files
ErrorLog ${APACHE_LOG_DIR}/error.log
CustomLog ${APACHE_LOG_DIR}/access.log combined
# Forward requests through the load balancer named "balancer://glassfishcluster/"
# Uses the JSESSIONID cookie to stick the sesstion to an appropriate GlassFish instance
ProxyPass / balancer://glassfishcluster/ stickysession=JSESSIONID failontimeout=On
ProxyPassReverse / balancer://glassfishcluster/
# Configuration of the load balancer and GlassFish instances connected to it
<Proxy balancer://glassfishcluster>
ProxySet lbmethod=byrequests
BalancerMember http://glassfish1:28080 route=instance1 timeout=10 retry=60
BalancerMember http://glassfish2:28080 route=remoteInstance timeout=10 retry=60
# Add more BalancerMembers for additional GlassFish instances
</Proxy>
</VirtualHost>Replace the following according to your actual setup:
yourdomain.com – the domain name of your application (the DNS record should point to the Apache server) glassfish1 – hostname or IP address of your GlassFish instance with name instance1glassfish2 – hostname or IP address of your GlassFish instance with name remoteInstanceinstance1, remoteInstance – names of your GlassFish instances. If you use different names, adjust them here and make sure that the jvmRoute system property on GlassFish instances is set to the same instance name Note that:
route arguments of BalancerMember must be GlassFish instance names matching that member (values set by the jvmRoute system property). The value of the jvmRoute system property should be defined in the GlassFish cluster configuration to the value of ${com.sun.aas.instanceName} to reflect the GlassFish instance name. This value will then be added to the session cookie so that the Apache loadbalancer can match a cookie with the right GlassFish instance.failontimeout=On, the load balancer waits at most 10 seconds for the request to complete. If it takes longer, it considers the GlassFish instance as unresponsive and fails over to another instance to process the request. This is to consider GlassFish instances that are stuck (e.g. when out of available memory) as inactive. If some requests take more time to complete, either disable this option, or increase the timeout arguments on BalancerMemberJSESSIONID with your custom cookie nameVerify that:
Restart Apache to enable the new modules and apply the configuration changes.
On an operating system that uses SystemD services (e.g. Ubuntu):
sudo systemctl restart apache2Test your setup by accessing your application through the Apache load balancer. Verify that sticky sessions are working, ensuring that requests within the same session are directed to the same GlassFish instance and requests without a session are routed to a random instance.
You can use the test cluster application available at https://github.com/OmniFish-EE/clusterjsp/releases:
With these steps, you should have a basic setup of a GlassFish server cluster
In case of an issue with a GlassFish instance, the load balancer should stop sending requests to that instance and keep using the remaining GlassFish instances in the cluster. Once the GlassFish instance recovers from issues, it will rejoin the load balancer and will start receiving requests again.
You can also rely on this mechanism when you need to restart the cluster; instead of restarting the whole cluster at once, you can restart GlassFish instances one by one. While one of the instances is being restarted, Apache server will continue sending requests to the other instances.
This tutorial will guide you to set up a GlassFish cluster that serves a single application on multiple machines.
This setup doesn’t enable HTTP session replication. Session data will be available only on the original cluster instance that created it. Therefore, if you access the cluster instances through a load balancer server, you should enable sticky session support on the load balancer server. With this mechanism, a single user will be always served by the same GlassFish instance, different users (HTTP sessions) may be served by different GlassFish instances. It’s also possible to configure session replication in a GlassFish cluster so that each session is available on each instance but this is not covered by this tutorial.
bin directory of your GlassFish installation.asadmin start-domainmyCluster)instance1 as an instance name, keep “Node” selected to the default “localhost-domain1”This will create a clustering configuration myCluster in GlassFish, with one GlassFish server instance instance1, which runs on the same machine as the GlassFish administration server (DAS).
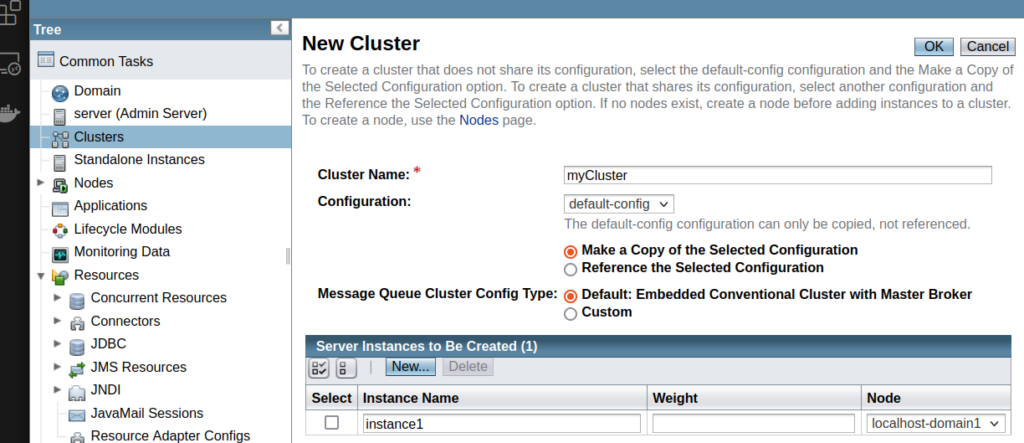
Clusters → myClusterThis configuration is needed to simplify the sticky session routing mechanism in load balancers, e.g. in Apache HTTP server.
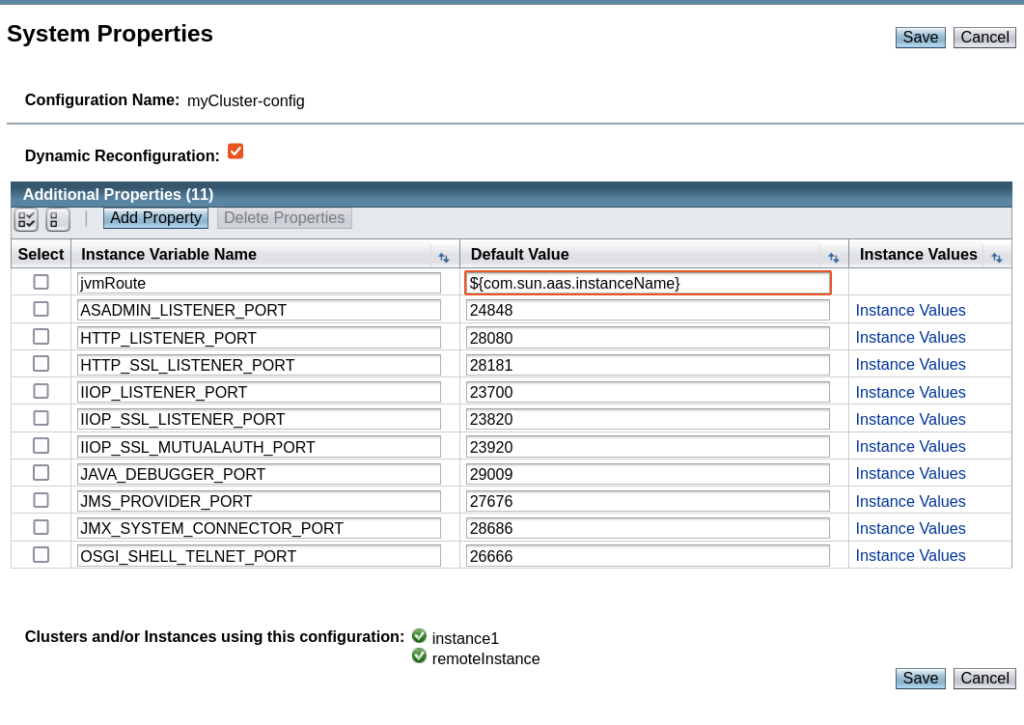
This will navigate you to the welcome page of the instance1 GlassFish instance running on port 28080.
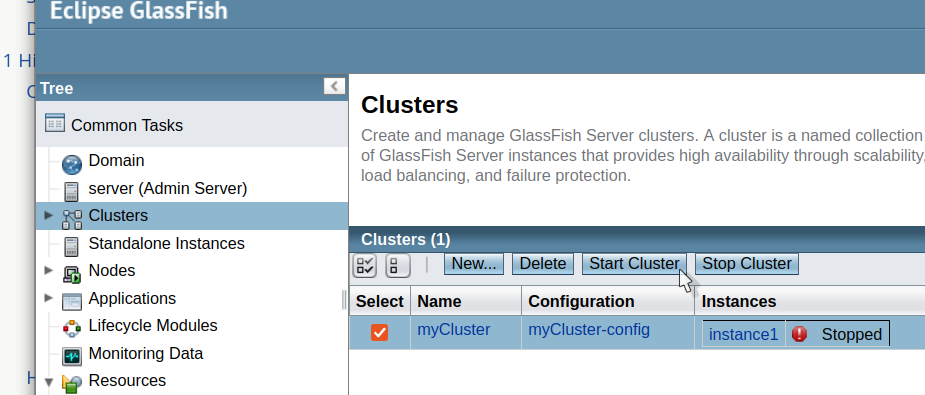
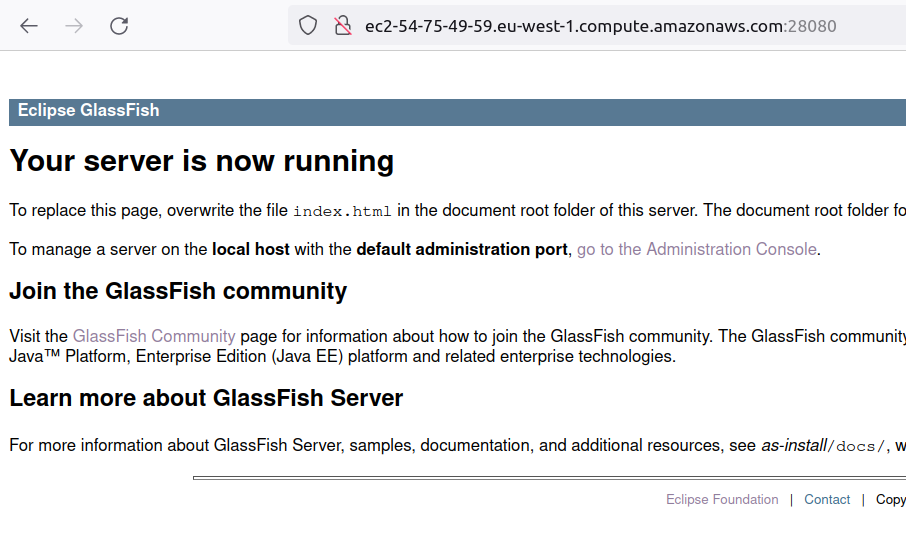
Deploy a cluster tester application, which you can download from https://github.com/OmniFish-EE/clusterjsp/releases.
Applications and click the “Deploy…” button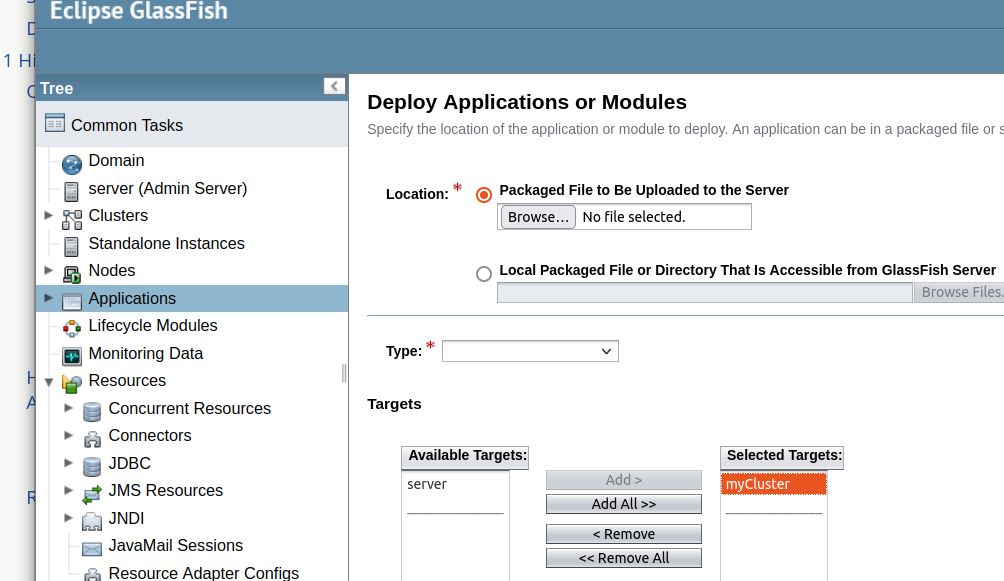
Browse… and select the application WAR fileRight now, there’s a single instance in the cluster. All requests are handled by that instance, session data is always present, and all should work as expected. As you’ll add more instances to the cluster, you can use this tester application again to verify that all works even if requests are sent to different instances.
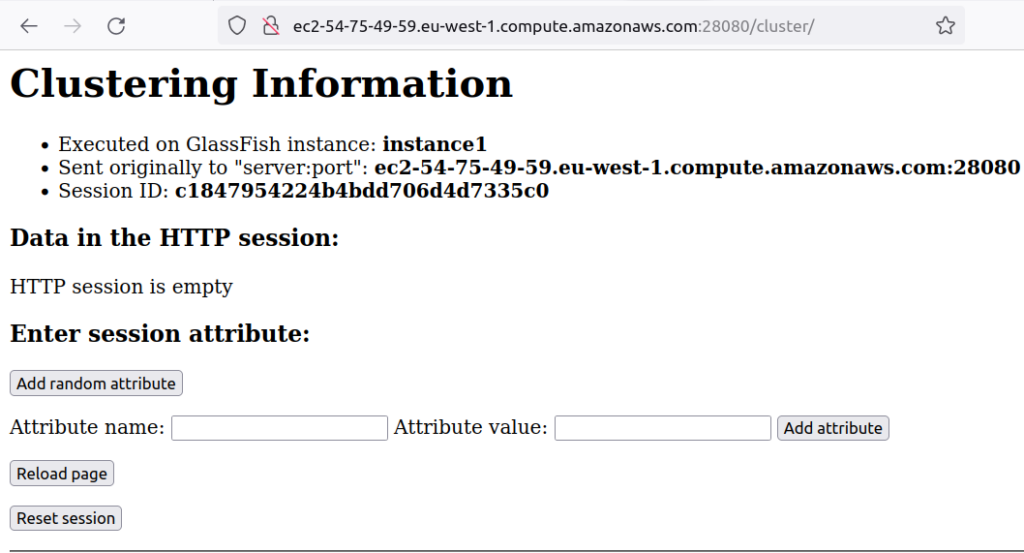
Now, add a SSH connection to a remote server, where you want to run other GlassFish cluster instances.
This assumes that you already have a remote machine with SSH server and Java installed.
Make sure that GlassFish admin server can access the remote machine on the SSH port (port 22 by default). Then:
Nodes. There’s always at least 1 node, e.g. localhost-domain1, which represents the local machinesshNode1).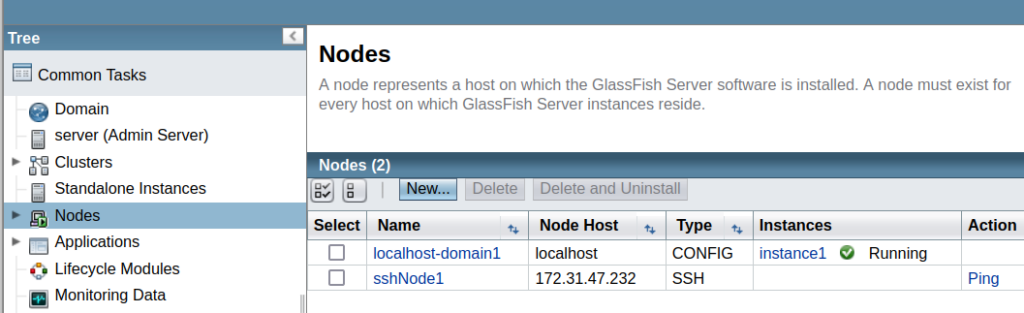
Clusters → myCluster.remoteInstance) and select the SSH node (sshNode1) as the target “Node”.Make sure that the admin port of the remote instance is open for connections from GlassFish admin server and isn’t blocked by a firewall. The port number is 24848 by default. You can find it in GlassFish Admin Console:
Clusters → myCluster, the tab “Instances”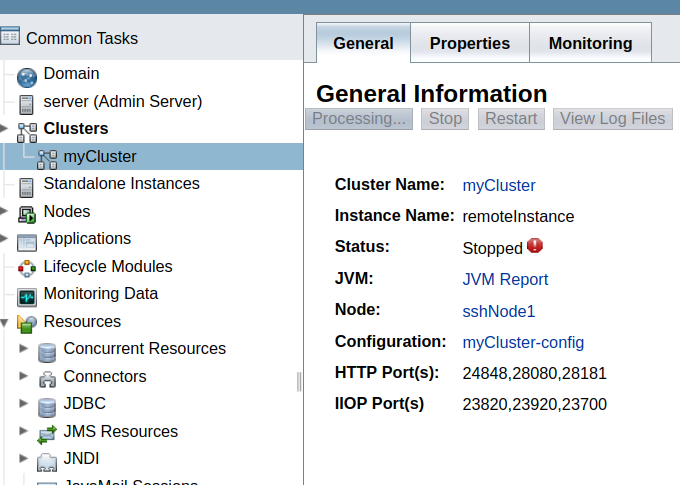
Without this, the admin server will be able to start the instance via SSH but will not be able to communicate with it or detect that it is running.
To start the new remote instance, you can start the cluster again, as you already did before. Starting a cluster if you already started it before will keep the “instance1” instance running, and will start all other instances which are not running.
Alternatively, you can start the remoteInstance individually:
remoteInstance and click on the “Start” button.This assumes that you’ve already set up a load balancer server, e.g. Apache HTTP server, and the load balancer is configured to support sticky sessions.
Access the tester application you deployed previously through the load balancer and verify that requests are load-balanced between the instances:
http://load-balancer-ip:load-balancer-port/clusterReplace load-balancer-ip and load-balancer-port with the appropriate values for your load balancer server.
After everything is working, you can undeploy the test application clusterjsp and deploy your own application. Remember to select your cluster as the deployment target, so that your application is deployed to all GlassFish instances in the cluster.
Before you deploy your application to the cluster, make sure that all resources that your application requires are deployed to the cluster too. For example, a JDBC resource:
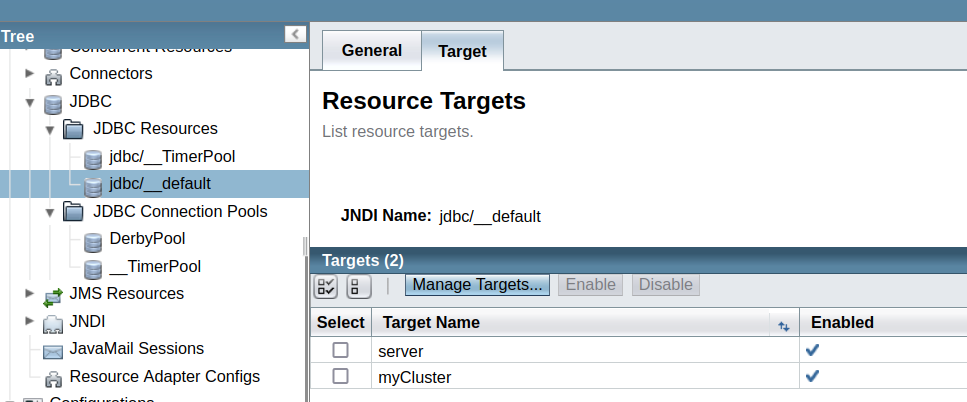
Now, deploy your application to the cluster, similarly as you deployed the tester application before in the Step 5:
Applications and click the “Deploy…” buttonThat’s it! You have now created a GlassFish cluster with instances, added an SSH node, and created an instance on this node using the Admin Console. Your application is running on all instances of the cluster. Now you can set up a load balancer server (e.g. Apache HTTP Server) with sticky sessions to proxy incoming requests to GlassFish instances, which we’ll cover in a future article.
Last updated 2024-01-28 13:40:07 +0100
Write a pure-Java microservice from scratch, without an application server nor any third party frameworks, tools, or IDE plugins — Just using JDK, Maven and JAX-RS aka Jakarta REST 3.1. This video series shows you the essential steps!
You asked, why I am not simply using the Jakarta EE 10 Core API. There are many answers in this video!
If you like this video, please give it a thumbs up, share it, subscribe to my channel, or become my patreon https://www.patreon.com/mkarg. Thanks! 
Let’s take a deep dive into the source code of #Jersey (the heart of GlassFish, Payara and Helidon) to learn how we can make our own I/O code run faster on modern Java.
In this first step, we apply NIO APIs from #Java 7 and 8 to process data more efficiently, and most notably: outside of the JVM.
If you like this video, please give it a thumbs up, share it, subscribe to my channel, or become my patreon https://www.patreon.com/mkarg. Thanks!
This blog aims at giving some pointers in order to address the challenge related to the switch from `javax` to `jakarta` namespace. This is one of the biggest changes in Java of the latest 20 years. No doubt. The entire ecosystem is impacted. Not only Java EE or Jakarta EE Application servers, but also libraries of any kind (Jackson, CXF, Hibernate, Spring to name a few). For instance, it took Apache TomEE about a year to convert all the source code and dependencies to the new `jakarta` namespace. This blog is written from the user perspective, because the shift from...
The post Moving from javax to jakarta namespace appeared first on Tomitribe.
This blog aims at giving some pointers in order to address the challenge related to the switch from `javax` to `jakarta` namespace. This is one of the biggest changes in Java of the latest 20 years. No doubt. The entire ecosystem is impacted. Not only Java EE or Jakarta EE Application servers, but also libraries of any kind (Jackson, CXF, Hibernate, Spring to name a few). For instance, it took Apache TomEE about a year to convert all the source code and dependencies to the new `jakarta` namespace.
This blog is written from the user perspective, because the shift from `javax` to `jakarta` is as impacting for application providers than it is for libraries or application servers. There have been a couple of attempts to study the impact and investigate possible paths to make the change as smooth as possible.
The problem is harder than it appears to be. The `javax` package is of course in the import section of a class, but it can be in Strings as well if you use the Java Reflection API for instance. Using Byte Code tools like ASM also makes the problem more complex, but also service loader mechanisms and many more. We will see that there are many ways to approach the problem, using byte code, converting the sources directly, but none are perfect.
The first legitimate approach that comes to our mind is the byte code approach. The goal is to keep the `javax` namespace as much as possible and use bytecode enhancement to convert binaries.
It is possible to do a post treatment on the libraries and packages to transform archives such as then are converted to `jakarta` namespace.
The Maven shade plugin has the ability to relocate packages. While the primary purpose isn’t to move from `javax` to `jakarta` package, it is possible to use it to relocate small libraries when they aren’t ready yet. We used this approach in TomEE itself or in third party libraries such as Apache Johnzon (JSONB/P implementation).
Here is an example in TomEE where we use Maven Shade Plugin to transform the Apache ActiveMQ Client library https://github.com/apache/tomee/blob/main/deps/activemq-client-shade/pom.xml
This approach is not perfect, especially when you have a multi module library. For Instance, if you have a project with 2 modules, A depends on B. You can use the shade plugin to convert the 2 modules and publish them using a classifier. The issue then is when you need A, you have to exclude B so that you can include it manually with the right classifier.
We’d say it works fine but for simple cases because it breaks the dependency management in Maven, especially with transitive dependencies. It also break IDE integration because sources and javadoc won’t match.
The Eclipse Transformer is also a generic tool, but it’s been heavily developed for the `javax` to `jakarta` namespace change. It operates on resources such as
Simple resources:
Container resources:
It can be configured using Java Properties files to properly convert Java Modules, classes, test resources. This is the approach we used for Apache TomEE 9.0.0-M7 when we first tried to convert to `jakarta`. It had limitation, so we had to then find tricks to solve issues. As it was converting the final distribution and not the individual artifacts, it was impossible for users to use Arquillian or the Maven plugin. They were not converted.
This tool can operate on a directory or an archive (zip, ear, jar, war). It can migrate quite easily an application based on the set of specifications supported in Tomcat and a few more. It has the notion of profile so that you can ask it to convert more.
You can run it using the ANT task (within Maven or not), and there is also a command line interface to run it easily.
When using application server, it is sometimes possible to step in the deployment process and do the conversion of the binaries prior to their deployment.
Mind that by default, the tool converts only what’s being supported by Apache Tomcat and a couple of other APIs. It does not convert all specifications supported in TomEE, like JAX RS for example. And Tomcat does not provide yet any way to configure it.
We haven’t seen any working solution in this area. Of course, we could imagine a JavaAgent approach that converts the bytecode right when it gets loaded by the JVM. The startup time is seriously impacted, and it has to be done every time the JVM restarts or loads a class in a classloader. Remember that a class can be loaded multiple times in different classloaders.
This may sound like the most impacting but this is probably also the most secured one. We also strongly believe that embracing the change sooner is preferable rather than later. As mentioned, this is one of the biggest breaking change in Java of the last 20 years. Since Java EE moved to Eclipse to become Jakarta, we have noticed a change in the release cadence. Releases are not more frequent and more changes are going to happen. Killing the technical depth as soon as possible is probably the best when it’s so impacting.
There are a couple of tools we tried. There are probably more in the ecosystem, and also some in-house developments.
[IMPORTANT]
This is usually a one shoot operation. It won’t be perfect and no doubt it will require adjustment because there is no perfect tool that can handle all cases.
IntelliJ IDEA added a refactoring capability to its IDE in order to convert sources to the new `jakarta` namespace. I haven’t tested it myself, but it may help to do the first big step when you don’t really master the scripting approach below.
For simple case, and we used that approach to do most of the conversion in TomEE, you can create your own simple tool to convert sources. For instance, SmallRye does that with their MicroProfile implementations. Here is an example https://github.com/smallrye/smallrye-config/blob/main/to-jakarta.sh
Using basic Linux commands, it converts from `javax` to `jakarta` namespace and then the result is pushed to a dedicated branch. The benefit is that they have 2 source trees with different artifacts, the dependency management isn’t broken.
One source tree is the reference and they add to the script the necessary commands to convert additional things on demand.
Because the Eclipse Transformer can operate on text files, it can be easily used to migrate the sources from `javax` to `jakarta` namespace.
Weather you are working on Open Source or not, someone will consume your artifacts. If you are using Maven for example, you may ask yourself what option is the best especially if you maintain the 2 branches `javax` and `jakarta`.
[NOTE]
It does not matter if you use the bytecode or the source code approach.
This is probably the more practical solution. Some project like Arquillian for example decided to go using a different artifact name (-jakarta suffix) because the artifact is the same and solves the same problem, so why bringing a technical concerned into the name? I’m more in favor of using the version to mark the namespace change. It is somehow an major API change that I’d rather emphasize using a major version update.
[IMPORTANT]
Mind that this only works if both `javax` and `jakarta` APIs are backward compatible. Otherwise, it won’t work
This is not an option we would recommend. Unfortunately some of our dependencies use this approach and it has many drawbacks. It’s fine for a quick test, but as I mentioned previously, it badly impacts how Maven works. If you pull a transformed artifact, you may get a transitive and not transformed dependency. This is the case for multi module project as well.
Another painful side effect is that javadoc and sources are still linked to the original artifact, so you will have a hard time to debug in the IDE.
We tried the bytecode approach ourselves in TomEE with the hope we could avoid maintaining 2 source trees, one for `javax` and the other one for `jakarta` namespace. Unfortunately, as we have seen before the risk is too important and there are too many edge cases not covered. Apache TomEE runs about 60k tests (including TCK) and our confidence wasn’t good enough. Even though the approach has some benefits and can work for simple use cases, like converting a small utility tool, it does not fit in our opinion for real applications.
The post Moving from javax to jakarta namespace appeared first on Tomitribe.
We’re currently in the middle of a substantial transition as we are migrating mission-critical websites from Drupal 7 to Drupal 9, with our sights set on Drupal 10. This shift has been motivated by several factors, including the announcement of Drupal 7 end-of-life which is now scheduled for January 5, 2025, and our goal to reduce technical debt that we accrued over the last decade.
To provide some context, we’re migrating a total of six key websites:
We’ve made substantial progress this year with our migration efforts. The team successfully completed the migration of Eclipse Blogs and Eclipse Newsroom. We are also in the final stages of development with the Eclipse Marketplace, which is currently scheduled for a production release on October 25, 2023. Next year, we’ll focus our attention on completing the migration of our more substantial sites, such as Eclipse PMI, Eclipse Accounts, and Eclipse Packaging.
This initiative isn’t just about moving from one version of Drupal to another. Simultaneously, we’re undertaking the task of decoupling essential APIs from Drupal in the hope that future migration or upgrade won’t impact as many core services at the same time. For this purpose, we’ve chosen Quarkus as our preferred platform. In Q3 2023, the team successfully migrated the GitHub ECA Validation Service and the Open-VSX Publisher Agreement Service from Drupal to Quarkus. In Q4 2023, we’re planning to continue down that path and deploy a Quarkus implementation of several critical APIs such as:
Our migration journey from Drupal 7 to Drupal 9, with plans for Drupal 10, represents our commitment to providing a secure, efficient, and user-friendly online experience for our community. We are excited about the possibilities this migration will unlock for us, advancing us toward a more modern web stack.
Finally, I’d like to take this moment to highlight that this project is a monumental team effort, thanks to the exceptional contributions of Eric Poirier and Théodore Biadala, our Drupal developers; Martin Lowe and Zachary Sabourin, our Java developers implementing the API decoupling objective; and Frederic Gurr, whose support has been instrumental in deploying our new apps on the Eclipse Infrastructure.
Now that Jetty 12.0.1 is released to Maven Central, we’ve started to get a few questions about where some artifacts are, or when we intend to release them (as folks cannot find them).
Things have change with Jetty, starting with the 12.0.0 release.
First, is that our historical versioning of <servlet_support>.<major>.<minor> is no longer being used.
With Jetty 12, we are now using a more traditional <major>.<minor>.<patch> versioning scheme for the first time.
Also new in Jetty 12 is that the Servlet layer has been separated away from the Jetty Core layer.
The Servlet layer has been moved to the new Environments concept introduced with Jetty 12.
| Environment | Jakarta EE | Servlet | Jakarta Namespace | Jetty GroupID |
| ee8 | EE8 | 4 | javax.servlet | org.eclipse.jetty.ee8 |
| ee9 | EE9 | 5 | jakarta.servlet | org.eclipse.jetty.ee9 |
| ee10 | EE10 | 6 | jakarta.servlet | org.eclipse.jetty.ee10 |
This means the old Servlet specific artifacts have been moved to environment specific locations both in terms of Java namespace and also their Maven Coordinates.
Example:
Jetty 11 – Using Servlet 5
Maven Coord: org.eclipse.jetty:jetty-servlet
Java Class: org.eclipse.jetty.servlet.ServletContextHandler
Jetty 12 – Using Servlet 6
Maven Coord: org.eclipse.jetty.ee10:jetty-ee10-servlet
Java Class: org.eclipse.jetty.ee10.servlet.ServletContextHandler
We have a migration document which lists all of the migrated locations from Jetty 11 to Jetty 12.
This new versioning and environment features built into Jetty means that new major versions of Jetty are not as common as they have been in the past.
The results of the 2023 Jakarta EE Developer Survey are now available! For the sixth year in a row, we’ve reached out to the enterprise Java community to ask about their preferences and priorities for cloud native Java architectures, technologies, and tools, their perceptions of the cloud native application industry, and more.
From these results, it is clear that open source cloud native Java is on the rise following the release of Jakarta EE 10.The number of respondents who have migrated to Jakarta EE continues to grow, with 60% saying they have already migrated, or plan to do so within the next 6-24 months. These results indicate steady growth in the use of Jakarta EE and a growing interest in cloud native Java overall.
When comparing the survey results to 2022, usage of Jakarta EE to build cloud native applications has remained steady at 53%. Spring/Spring Boot, which relies on some Jakarta EE specifications, continues to be the leading Java framework in this category, with usage growing from 57% to 66%.
Since the September 2022 release, Jakarta EE 10 usage has grown to 17% among survey respondents. This community-driven release is attracting a growing number of application developers to adopt Jakarta EE 10 by offering new features and updates to Jakarta EE. An equal number of developers are running Jakarta EE 9 or 9.1 in production, while 28% are running Jakarta EE 8. That means the increase we are seeing in the migration to Jakarta EE is mostly due to the adoption of Jakarta EE 10, as compared to Jakarta EE 9/9.1 or Jakarta EE 8.
The Jakarta EE Developer Survey also gives us a chance to get valuable feedback on features from the latest Jakarta EE release, as well as what direction the project should take in the future.
Respondents are most excited about Jakarta EE Core Profile, which was introduced in the Jakarta EE 10 release as a subset of Web Profile specifications designed for microservices and ahead-of-time compilation. When it comes to future releases, the community is prioritizing better support for Kubernetes and microservices, as well as adapting Java SE innovations to Jakarta EE — a priority that has grown in popularity since 2022. This is a good indicator that the Jakarta EE 11 release plan is on the right direction by adopting new Java SE 21 features.
2,203 developers, architects, and other tech professionals participated in the survey, a 53% increase from last year. This year’s survey was also available in Chinese, Japanese, Spanish & Portuguese, making it easier for Java enthusiasts around the world to share their perspectives. Participation from the Chinese Jakarta EE community was particularly strong, with over 27% of the responses coming from China. By hearing from more people in the enterprise Java space, we’re able to get a clearer picture of what challenges developers are facing, what they’re looking for, and what technologies they are using. Thank you to everyone who participated!
We encourage you to download the report for a complete look at the enterprise Java ecosystem.
If you’d like to get more information about Jakarta EE specifications and our open source community, sign up for one of our mailing lists or join the conversation on Slack. If you’d like to participate in the Jakarta EE community, learn how to get started on our website.
Looking at the web, we don’t see many articles talking about Contexts Dependency Injection’s best practices. Hence, I have made the decision to discuss the utilization of Contexts Dependency Injection (CDI) using best practices, providing a comprehensive guide on its implementation.
The CDI is a Jakarta specification in the Java ecosystem to allow developers to use dependency injection, managing contexts, and component injection in an easier way. The article https://www.baeldung.com/java-ee-cdi defines the CDI as follows:
CDI turns DI into a no-brainer process, boiled down to just decorating the service classes with a few simple annotations, and defining the corresponding injection points in the client classes.
If you want to learn the CDI concepts you can read Baeldung’s post and Otavio Santana’s post. Here, in this post, we will focus on the best practices topic.
In fact, CDI is a powerful framework and allows developers to use Dependency Injection (DI) and Inversion of Control (IoC). However, we have one question here. How tightly do we want our application to be coupled with the framework? Note that I’m not talking you cannot couple your application to a framework, but you should think about it, think about the coupling level, and think about the tradeoffs. For me, coupling an application to a framework is not wrong, but doing it without thinking about the coupling level and the cost and tradeoffs is wrong.
It is impossible to add a framework to your application without minimally coupling your application. Even though your application does not have a couple expressed in the code, probably you have a behavioral coupling, that is, a behavior in your application depends on a framework’s behavior, and in some cases, you can not guarantee that other framework will provide a similar behavior, in case of changes.
When writing code in Java, we often create classes that rely on external dependencies to perform their tasks. To achieve this using CDI, we employ the @Inject annotation, which allows us to inject these dependencies. However, it’s essential to be mindful of whether we are making the class overly dependent on CDI for its functionality, as it may limit its usability without CDI. Hence, it’s crucial to carefully consider the tightness of this dependency. As an illustration, let’s examine the code snippet below. Here, we encounter a class that is tightly coupled to CDI in order to carry out its functionality.
public class ImageRepository {
@Inject
private StorageProvider storageProvider;
public void saveImage(File image){
//Validate the file to check if it is an image.
//Apply some logic if needed
storageProvider.save(image);
}
}As you can see the class ImageRepository has a dependency on StorageProvider, that is injected via CDI annotation. However, the storageProvider variable is private and we don’t have setter method or a constructor that allows us to pass this dependency by the constructor. It means this class cannot work without a CDI context, that is, the ImageRepository is tightly coupled to CDI.
This coupling doesn’t provide any benefits for the application, instead, it only causes harm both to the application itself and potentially to the testing of this class.
Look at the code refactored to reduce the couple to CDI.
public class ImageRepository implements Serializable {
private StorageProvider storageProvider;
@Inject
public ImageRepository(StorageProvider storageProvider){
this.storageProvider = storageProvider;
}
public void saveImage(File image){
//Validate the file to check if it is an image.
//Apply some logic if needed
storageProvider.save(image);
}
}As you can see, the ImageRepository class has a constructor that receives the StorageProvider as a constructor argument. This approach follows what is said in the Clean Code book.
“True Dependency Injection goes one step further. The class takes no direct steps to resolve its dependencies; it is completely passive. Instead, it provides setter methods or constructor arguments (or both) that are used to inject the dependencies.”
(from “Clean Code: A Handbook of Agile Software Craftsmanship” by Martin Robert C.)
Without a constructor or a setter method, the injection depends on the CDI. However, we still have one question about this class. The class has a CDI annotation and depends on the CDI to be compiled. I’m not saying it is always a problem, but it can be a problem, especially if you are writing a framework. Coupling a framework with another framework can be a problem in cases you want to use your framework with another mutually exclusive one. In general, it should be avoided by frameworks. Thus, how can we fully decouple the ImageRepository class from CDI?
The CDI producer is a source of an object that can be used to be injected by CDI. It is like a factor of a type of object. Look at the code below:
public class ImageRepositoryProducer {
@Produces
public ImageRepository createImageRepository(){
StorageProvider storageProvider = CDI.current().select(StorageProvider.class).get();
return new ImageRepository(storageProvider);
}
}Please note that we are constructing just one object, but the StorageProvider‘s object is read by CDI. You should avoid constructing more than one object within a producer method, as this interlinks the construction of these objects and may lead to complications if you intend to designate distinct scopes for them. You can create a separated producer method to produce the StorageProvider.
This is the ImageRepository class refactored.
public class ImageRepository implements Serializable {
private StorageProvider storageProvider;
public ImageRepository(StorageProvider storageProvider){
this.storageProvider = storageProvider;
}
public void saveImage(File image){
//Validate the file to check if it is an image.
//Apply some logic if needed
storageProvider.save(image);
}
}Please note that the ImageRepository class does not know anything about the CDI, and is fully decoupled from CDI. The codes about the CDI are inside the ImageRepositoryProducer, which can be extracted to another module if needed.
The CDI Interceptor is a very cool feature of CDI that provides a nice CDI-based way to work with cross-cutting tasks (such as auditing). This is a little definition said in my book:
“A CDI interceptor is a class that wraps the call to a method — this method is called target method — that runs its logic and proceeds the call either to the next CDI interceptor if it exists, or the target method.”
(from “Jakarta EE for Java Developers” by Rhuan Rocha.)
The purpose of this article is not to discuss what a CDI interceptor is, but to discuss CDI best practices. So if you want to read more about CDI interceptor, check out the book Jakarta EE for Java Developers.
As said, the CDI interceptor is very interesting. I am quite fond of this feature and have incorporated it into numerous projects. However, using this feature comes with certain trade-offs for the application.
When you use the CDI interceptor you couple the class to the CDI, because you should be annotating the class with a custom annotation that is a interceptor binding. Look at the example below shown on the Jakarta EE for Java Developers book:
@ApplicationScopedpublic class SecuredBean{
@Authentication
public String generateText(String username) throws AutenticationException{
return "Welcome "+username;
}
}As you can see we should define a scope, as it should be a bean managed by CDI, and you should be annotating the class with the interceptor binding. Hence, if you eliminate CDI from your application, the interceptor’s logic won’t execute, and the class won’t be compiled. With this, your application has a behavioral coupling, and a dependency on the CDI lib jar to compile.
As said, it is not necessarily bad, however, you should think if it is a problem in your context.
The CDI Event is a great feature within the CDI framework that I have employed extensively in various applications. This functionality provides the implementation of the Observer Pattern, enabling us to emit events that are then observed by observers who execute tasks asynchronously. However, if we add the CDI codes inside our class to emit events we will couple the class to the CDI. Again, this is not an error, but you should be sure it is not a problem with your solution. Look at the example below.
import jakarta.enterprise.event.Event;
public class User{
private Event<Email> emailEvent;
public User(Event<Email> emailEvent){
this.emailEvent = emailEvent;
}
public void register(){
//logic
emailEvent.fireAsync(Email.of(from, to, subject, content));
}
}Note we are receiving the Event class, which is from CDI, to emit the event. It means this class is coupled to CDI and depends on it to work. One way to avoid it is creating your own class to emit the event, and abstract the details about what is the mechanism (CDI or other) that is emitting the event. Look at the example below.
import net.rhuan.example.EventEmitter;
public class User{
private EventEmiter<Email> emailEventEmiter;
public User(EventEmiter<Email> emailEventEmiter){
this.emailEventEmiter = emailEventEmiter;
}
public void register(){
//logic
emailEventEmiter.emit(Email.of(from, to, subject, content));
}
}Now, your class is agnostic to the emitter of the event. You can use CDI or others, according to the EventEmiter implementation.
The CDI is an amazing specification from Jakarta EE widely used in many Java frameworks and Java applications. Carefully determining the degree of integration between our application and the framework holds immense significance. This intentional decision becomes an important factor in proactively mitigating challenges during the solution’s evolution, especially when working on the development of a framework.
If you have a question or want to share your thoughts, feel free to add comments or send me messages about it.
It is that time of the year: the Jakarta EE 2023 Developer Survey open for your input! The survey will stay open until May 25st.
I would like to invite you to take this year six-minute survey, and have the chance to share your thoughts and ideas for future Jakarta EE releases, and help us discover uptake of the Jakarta EE latest versions and trends that inform industry decision-makers.
Please share the survey link and to reach out to your contacts: Java developers, architects and stakeholders on the enterprise Java ecosystem and invite them to participate in the 2023 Jakarta EE Developer Survey!

In this post, I will talk to you about what the Apache Camel is. It is a brief introduction before I starting to post practical content. Thus, let’s go to understand what this framework is.
Apache Camel is an open source Java integration framework that allows different applications to communicate with each other efficiently. It provides a platform for integrating heterogeneous software systems. Camel is designed to make application integration easy, simplifying the complexity of communication between different systems.
Apache Camel is written in Java and can be run on a variety of platforms, including Jakarta EE application servers and OSGi-based application containers, and can runs inside cloud environments using Spring Boot or Quarkus. Camel also supports a wide range of network protocols and message formats, including HTTP, FTP, SMTP, JMS, SOAP, XML, and JSON.
Camel uses the Enterprise Integration Patterns (EIP) pattern to define the different forms of integration. EIP is a set of commonly used design patterns in system integration. Camel implements many of these patterns, making it a powerful tool for integration solutions.
Additionally, Camel has a set of components that allow it to integrate with different systems. The components can be used to access different resources, such as databases, web services, and message systems. Camel also supports content-based routing, which means it can route messages based on their content.
Camel is highly configurable and extensible, allowing developers to customize its functionality to their needs. It also supports the creation of integration routes at runtime, which means that routes can be defined and changed without the need to restart the system.
In summary, Camel is a powerful and flexible tool for software system integration. It allows different applications to communicate efficiently and effectively, simplifying the complexity of system integration. Camel is a reliable and widely used framework that can help improve the efficiency and effectiveness of system integration in a variety of environments.
If you want to start using this framework you can access the documentation at the site. It’s my first post about the Apache Camel and will post more practical content about this amazing framework.
We have great news to share with you!
For the very first time at Devnexus 2023 we will have Jakarta EE track with 10 sessions and we will take this opportunity, to whenever possible, celebrate all we have accomplished in Jakarta EE community.
Jakarta EE track sessions
You may not be aware but this year (yes, time flies!!) marks 5 years of Jakarta EE, so we will be celebrating through out the year! Devnexus 2023, looks a great place to mark this milestone as well! So stay tuned for details, but in the meanwhile please help us out, register for the event come to see us and spread the word.
Help us out in spreading the word about Jakarta EE track @Devnexus 2023, just re-share posts you see from us on various social platforms!
To make it easier for you to spread the word on socials, we also have prepared a social kit document to help us with promotion of the Jakarta EE track @Devnexus 2023, sessions and speakers. The social kit document is going to be updated with missing sessions and speakers, so visit often and promote far and wide.
Note: Organizers wanted to do something for people impacted by the recent tech layoffs, and decided to offer a 50% discount for any conference pass (valid for a limited time). Please use code DN-JAKARTAEE for @JakartaEE Track to get additional 20% discount!
In addition, there will be an IBM workshop that will be highlighting Jakarta EE; look for "Thriving in the cloud: Venturing beyond the 12 factors". Please use the promo code ($100 off): JAKARTAEEATDEVNEXUS the organizers prepared for you (valid for a limited time).
I hope to see you all at Devnexus 2023!
Community Day at EclipseCon 2022 was held in person on Monday, October 24 in Ludwigsburg, Germany. Community Day has always been a great event for Eclipse working groups and project teams, including Jakarta EE/MicroProfile. This year was no exception. A number of great sessions were delivered from prominent folks in the community. The following are the details including session materials. The agenda can still be found here. All the materials can be found here.

Jakarta EE Community State of the Union
The first session of the day was a Jakarta EE community state of the union delivered by Tanja Obradovic, Ivar Grimstad and Shabnam Mayel. The session included a quick overview of Jakarta EE releases, how to get involved in the work of producing the specifications, a recap of the important Jakarta EE 10 release and as well as a view of what’s to come in Jakarta EE 11. The slides are embedded below and linked here.
Jakarta Concurrency – What’s Next
Payara CEO Steve Millidge covered Jakarta Concurrency. He discussed the value proposition of Jakarta Concurrency, the innovations delivered in Jakarta EE 10 (including CDI based @Asynchronous, @ManagedExecutorDefinition, etc) and the possibilities for the future (including CDI based @Schedule, @Lock, @MaxConcurrency, etc). The slides are embedded below and linked here. There are some excellent code examples included.
Jakarta Security – What’s Next
Werner Keil covered Jakarta Security. He discussed what’s already done in Jakarta EE 10 (including OpenID Connect support) and everything that’s in the works for Jakarta EE 11 (including CDI based @RolesAllowed). The slides are embedded below and linked here.
Jakarta Data – What’s Coming
IBM’s Emily Jiang kindly covered Jakarta Data. This is a brand new specification aimed towards Jakarta EE 11. It is a higher level data access abstraction similar to Spring Data and DeltaSpike Data. It encompasses both Jakarta Persistence (JPA) and Jakarta NoSQL. The slides are embedded below and linked here. There are some excellent code examples included.
MicroProfile Community State of the Union
Emily also graciously delivered a MicroProfile state of the union. She covered what was delivered in MicroProfile 5, including alignment with Jakarta EE 9.1. She also discussed what’s coming soon in MicroProfile 6 and beyond, including very clear alignment with the Jakarta EE 10 Core Profile. The slides are embedded below and linked here. There are some excellent technical details included.
MicroProfile Telemetry – What’s Coming
Red Hat’s Martin Stefanko covered MicroProfile Telemetry. Telemetry is a brand new specification being included in MicroProfile 6. The specification essentially supersedes MicroProfile Tracing and possibly MicroProfile Metrics too in the near future. This is because the OpenTracing and OpenCensus projects merged into a single project called OpenTelemetry. OpenTelemetry is now the de facto standard defining how to collect, process, and export telemetry data in microservices. It makes sense that MicroProfile moves forward with supporting OpenTelemetry. The slides are embedded below and linked here. There are some excellent technical details and code examples included.
See You There Next Time?
Overall, it was an honor to organize the Jakarta EE/MicroProfile agenda at EclipseCon Community Day one more time. All speakers and attendees should be thanked. Perhaps we will see you at Community Day next time? It is a great way to hear from some of the key people driving Jakarta EE and MicroProfile. You can attend just Community Day even if you don’t attend EclipseCon. The fee is modest and includes lunch as well as casual networking.

An impression of JFall by yours truly.
Sold out!

Packet room!


Very nice first keynote speaker by Saby Sengupta about the path to transform.
He is a really nice storyteller. He had us going.
Dutch people, wooden shoes, wooden hat, would not listen
- Saby
lol
Get the answer to three why questions. If the answers stop after the first why. It may not be a good idea.

This great first keynote is followed by the very well known Venkat Subramaniam about The Art of Simplicity.


The question is not what can we add? But What can we remove?
Simple fails less
Simple is elegant
All in al a great keynote! Loved it.
By Venkat Subramaniam

The GOF are kind of the grand parents of our industry. The worst thing they have done is write the damn book.
— Venkat
The quote is in the context of that writing down grandmas fantastic recipe does not work as it is based on the skill of grandma and not the exact amount of the ingredients.
The cleanup is the responsibility of the Resource class. Much better than asking developers to take care of it. It will be forgotten!
The more powerful a language becomes the less we need to talk about patterns. Patterns become practices we use. We do not need to put in extra effort.
I love his way of presenting, but this is the one of those times - I guess - that he is hampered by his own succes. The talk did not go deep into stuff. During his talk I just about covered 5 not too difficult subjects. I missed his speed and depth.
Still a great talk though.
Was actually very nice!

The Java Magazine was mentioned we (as Editors) had to shout for that!
Please contact me (@ivonet) if you have ambitions to either be an author or maybe even as a fellow editor of the magazine. We are searching for a new Editor now.
Then the voting for the Innovation Awards.
I kinda missed the next keynote by ING because I was playing with a rubix cube and I did not really like his talk
by Ivar Grimstad

Ivar talks about the specification of Jakarta EE.



To create a lite version of CDI it is possible to start doing things at build time and facilitate other tools like GraalVM and Quarkus.

He gives nice demos on how to migrate code to work in de jakarta namespace.
To start your own Jakarta EE application just go to start.jakarta.ee en follow the very simple UI instructions
I am very proud to be the creator of that UI. Thanks, Ivar for giving me a shoutout for that during your talk. More cool stuff will follow soon.



Be prepared to do some namespace changes when moving from Java EE 8 to Jakarta EE.

All slides here
I had a fantastic day. For me, it is mainly about the community and seeing all the people I know in the community. I totally love the vibe of the conference and I think it is one of the best organized venues.
See you at JSpring.
Ivo.
The results of the 2022 Jakarta EE Developer Survey are very telling about the current state of the enterprise Java developer community. They point to increased confidence about Jakarta EE and highlight how far Jakarta EE has grown over the past few years.
Strong Turnout Helps Drive Future of Jakarta EE
The fifth annual survey is one of the longest running and best-respected surveys of its kind in the industry. This year’s turnout was fantastic: From March 9 to May 6, a total of 1,439 developers responded.
This is great for two reasons. First, obviously, these results help inform the Java ecosystem stakeholders about the requirements, priorities and perceptions of enterprise developer communities. The more people we hear from, the better picture we get of what the community wants and needs. That makes it much easier for us to make sure the work we’re doing is aligned with what our community is looking for.
The other reason is that it helps us better understand how the cloud native Java world is progressing. By looking at what community members are using and adopting, what their top goals are and what their plans are for adoption, we can better understand not only what we should be working on today, but tomorrow and for the future of Jakarta EE.
Findings Indicate Growing Adoption and Rising Expectations
Some of the survey’s key findings include:
Two of the results, when combined, highlight something interesting:
After all, you wouldn’t wait for a later version and skip the one that’s already available, unless you were confident that the newer version was not only going to be coming out on a relatively reliable timeline, but that it was going to be an improvement.
And this growing hunger from the community for faster support really speaks to how far the ecosystem has come. When we release a new version, like when we released Jakarta EE 9, it takes some time for the technology implementers to build the product based on those standards or specifications. The community is becoming more vocal in requesting those implementers to be more agile and quickly pick up the new versions. That’s definitely an indication that developer demand for Jakarta EE products is growing in a healthy way.
Learn More
If you’d like to learn more about the project, there are several Jakarta EE mailing lists to sign up for. You can also join the conversation on Slack. And if you want to get involved, start by choosing a project, sign up for its mailing list and start communicating with the team.
The Jakarta EE Ambassadors are thrilled to see Jakarta EE 10 being released! This is a milestone release that bears great significance to the Java ecosystem. Jakarta EE 8 and Jakarta EE 9.x were important releases in their own right in the process of transitioning Java EE to a truly open environment in the Eclipse Foundation. However, these releases did not deliver new features. Jakarta EE 10 changes all that and begins the vital process of delivering long pending new features into the ecosystem at a regular cadence.

There are quite a few changes that were delivered – here are some key themes and highlights:
While there are many features that we identified in our Jakarta EE 10 Contribution Guide that did not make it yet, this is still a very solid release that everyone in the Java ecosystem will benefit from, including Spring, MicroProfile and Quarkus. You can see here what was delivered, what’s on the way and what gaps still remain. You can try Jakarta EE 10 out now using compatible implementations like GlassFish, Payara, WildFly and Open Liberty. Jakarta EE 10 is proof in the pudding that the community, including major stakeholders, has not only made it through the transition to the Eclipse Foundation but now is beginning to thrive once again.
Many Ambassadors helped make this release a reality such as Arjan Tijms, Werner Keil, Markus Karg, Otavio Santana, Ondro Mihalyi and many more. The Ambassadors will now focus on enabling the community to evangelize Jakarta EE 10 including speaking, blogging, trying out implementations, and advocating for real world adoption. We will also work to enable the community to continue to contribute to Jakarta EE by producing an EE 11 Contribution Guide in the coming months. Please stay tuned and join us.
Jakarta EE is truly moving forward – the next phase of the platform’s evolution is here!

Getting started with Jakarta EE just became even easier!
Moved from the Apache 2 license to the Eclipse Public License v2 for the newest version of the archetype as described below.
As a start for a possible collaboration with the Eclipse start project.
New Archetype with JakartaEE 9
JakartaEE 9 + Payara 5.2022.2 + MicroProfile 4.1 running on Java 17
FOSDEM took place February 5-6. The European based event is one of the most significant gatherings worldwide focused on all things Open Source. Named the “Friends of OpenJDK”, in recent years the event has added a devroom/track dedicated to Java. The effort is lead by my friend and former colleague Geertjan Wielenga. Due to the pandemic, the 2022 event was virtual once again. I delivered a couple of talks on Jakarta EE as well as Diversity & Inclusion.

Fundamentals of Diversity & Inclusion for Technologists
I opened the second day of the conference with my newest talk titled “Fundamentals of Diversity and Inclusion for Technologists”. I believe this is an overdue and critically important subject. I am very grateful to FOSDEM for accepting the talk. The reality for our industry remains that many people either have not yet started or are at the very beginning of their Diversity & Inclusion journey. This talk aims to start the conversation in earnest by explaining the basics. Concepts covered include unconscious bias, privilege, equity, allyship, covering and microaggressions. I punctuate the topic with experiences from my own life and examples relevant to technologists. The slides for the talk are available on SpeakerDeck. The video for the talk is now posted on YouTube.
Jakarta EE – Present and Future
Later the same day, I delivered my fairly popular talk – “Jakarta EE – Present and Future”. The talk is essentially a state of the union for Jakarta EE. It covers a little bit of history, context, Jakarta EE 8, Jakarta EE 9/9.1 as well as what’s ahead for Jakarta EE 10. One key component of the talk is the importance and ways of direct developer contributions into Jakarta EE, if needed with help from the Jakarta EE Ambassadors. Jakarta EE 10 and the Jakarta Core Profile should bring an important set of changes including to CDI, Jakarta REST, Concurrency, Security, Faces, Batch and Configuration. The slides for the talk are available on SpeakerDeck. The video for the talk is now posted on YouTube.
I am very happy to have had the opportunity to speak at FOSDEM. I hope to contribute again in the future.
Infinispan 10+ uses Log4j version 2.0+ and can be affected by vulnerability CVE-2021-44228, which has a 10.0 CVSS score. The first fixed Log4j version is 2.15.0.
So, until official patch is coming, - you can update used logger version to the latest in few simple steps
wget https://downloads.apache.org/logging/log4j/2.15.0/apache-log4j-2.15.0-bin.zip
unzip apache-log4j-2.15.0-bin.zip
cd /opt/infinispan-server-10.1.8.Final/lib/
rm log4j-*.jar
cp ~/Downloads/apache-log4j-2.15.0-bin/log4j-api-2.15.0.jar ./
cp ~/Downloads/apache-log4j-2.15.0-bin/log4j-core-2.15.0.jar ./
cp ~/Downloads/apache-log4j-2.15.0-bin/log4j-jul-2.15.0.jar ./
cp ~/Downloads/apache-log4j-2.15.0-bin/log4j-slf4j-impl-2.15.0.jar ./
Please, note - patch above is not official, but according to initial tests it works with no issues
In the previous post, we saw how to use the built-in ‘tomcat-users.xml’ identity store with Apache TomEE. While this identity store is inherited from Tomcat and integrated into Jakarta Security implementation in TomEE, this is usually good for development or simple deployments, but may appear too simple or restrictive for production environments. This blog will focus on how to implement your own identity store. TomEE can use LDAP or JDBC identity stores out of the box. We will try them out next time. Let’s say you have your own file store or your own data store like an in-memory data...
The post Custom Identity Store with Jakarta Security in TomEE appeared first on Tomitribe.
In the previous post, we saw how to use the built-in ‘tomcat-users.xml’ identity store with Apache TomEE. While this identity store is inherited from Tomcat and integrated into Jakarta Security implementation in TomEE, this is usually good for development or simple deployments, but may appear too simple or restrictive for production environments.
This blog will focus on how to implement your own identity store. TomEE can use LDAP or JDBC identity stores out of the box. We will try them out next time.
Let’s say you have your own file store or your own data store like an in-memory data grid, then you will need to implement your own identity store.
An identity store is a database or a directory (store) of identity information about a population of users that includes an application’s callers.
In essence, an identity store contains all information such as caller name, groups or roles, and required information to validate a caller’s credentials.
This is actually fairly simple with Jakarta Security. The only thing you need to do is create an implementation of `jakarta.security.enterprise.identitystore.IdentityStore`. All methods in the interface have default implementations. So you only have to implement what you need.
public interface IdentityStore {
Set DEFAULT_VALIDATION_TYPES = EnumSet.of(VALIDATE, PROVIDE_GROUPS);
default CredentialValidationResult validate(Credential credential) {
}
default Set getCallerGroups(CredentialValidationResult validationResult) {
}
default int priority() {
}
default Set validationTypes() {
}
enum ValidationType {
VALIDATE, PROVIDE_GROUPS
}
}
By default, an identity store is used for both validating user credentials and providing groups/roles for the authenticated user. Depending on what #validationTypes() will return, you will have to implement #validate(…) and/or #getCallerGroups(…)
#getCallerGroups(…) will receive the result of #valide(…). Let’s look at a very simple example:
@ApplicationScoped
public class TestIdentityStore implements IdentityStore {
public CredentialValidationResult validate(Credential credential) {
if (!(credential instanceof UsernamePasswordCredential)) {
return INVALID_RESULT;
}
final UsernamePasswordCredential usernamePasswordCredential = (UsernamePasswordCredential) credential;
if (usernamePasswordCredential.compareTo("jon", "doe")) {
return new CredentialValidationResult("jon", new HashSet<>(asList("foo", "bar")));
}
if (usernamePasswordCredential.compareTo("iron", "man")) {
return new CredentialValidationResult("iron", new HashSet<>(Collections.singletonList("avengers")));
}
return INVALID_RESULT;
}
}
In this simple example, the identity store is hardcoded. Basically, it knows only 2 users, one of them has some roles, while the other has another set of roles.
You can easily extend this example and query a local file, or an in-memory data grid if you need. Or use JPA to access your relational database.
IMPORTANT: for TomEE to pick it up and use it in your application, the identity store must be a CDI bean.
The complete and runnable example is available under https://github.com/apache/tomee/tree/master/examples/security-custom-identitystore
The post Custom Identity Store with Jakarta Security in TomEE appeared first on Tomitribe.

Disclaimer: I received this book as a collaboration with Packt and one of the authors (Thanks Emily!)
Year after year many enterprise companies are struggling to embrace Cloud Native practices that we tend to denominate as Microservices, however Microservices is a metapattern that needs to follow a well defined approach, like:
Many of these concepts require a considerable amount of context, but some books, tutorials, conferences and YouTube videos tend to focus on specific niche information, making difficult to have a "cold start" in the microservices space if you have been developing regular/monolithic software. For me, that's the best thing about this book, it provides a holistic view to understand microservices with Java and MicroProfile for "cold starter developers".
Using a software architect perspective, MicroProfile could be defined as a set of specifications (APIs) that many microservices chassis implement in order to solve common microservices problems through patterns, lessons learned from well known Java libraries, and proposals for collaboration between Java Enterprise vendors.
Subsequently if you think that it sounds a lot like Java EE, that's right, it's the same spirit but on the microservices space with participation for many vendors, including vendors from the Java EE space -e.g. Red Hat, IBM, Apache, Payara-.
The main value of this book is the willingness to go beyond the APIs, providing four structured sections that have different writing styles, for instance:
This was by far my favorite section. This section presents a well-balanced overview about Cloud Native practices like:
I enjoyed this section because my current role is to coach or act as a software architect at different companies, hence this is good material to explain the whole panorama to my coworkers and/or use this book as a quick reference.
My only concern with this section is about the final chapter, this chapter presents an application called IBM Stock Trader that (as you probably guess) IBM uses to demonstrate these concepts using MicroProfile with OpenLiberty. The chapter by itself presents an application that combines data sources, front/ends, Kubernetes; however the application would be useful only on Section 3 (at least that was my perception). Hence you will be going back to this section once you're executing the workshop.
This section divides the MicroProfile APIs in three levels, the division actually makes a lot of sense but was evident to me only during this review:
Additionally, section also describes the need for Docker and Kubernetes and how other common approaches -e.g. Service mesh- overlap with Microservice Chassis functionality.
Currently I'm a MicroProfile user, hence I knew most of the APIs, however I liked the actual description of the pattern/need that motivated the inclusion of the APIs, and the description could be useful for newcomers, along with the code snippets also available on GitHub.
If you're a Java/Jakarta EE developer you will find the CDI section a little bit superficial, indeed CDI by itself deserves a whole book/fascicle but this chapter gives the basics to start the development process.
This section switches the writing style to a workshop style. The first chapter is entirely focused on how to compile the sample microservices, how to fulfill the technical requirements and which MicroProfile APIs are used on every microservice.
You must notice that this is not a Java programming workshop, it's a Cloud Native workshop with ready to deploy microservices, hence the step by step guide is about compilation with Maven, Docker containers, scaling with Kubernetes, operators in Openshift, etc.
You could explore and change the source code if you wish, but the section is written in a "descriptive" way assuming the samples existence.
This section is pretty similar to the second section in the reference book style, hence it also describes the pattern/need that motivated the discussion of the API and code snippets. The main focus of this section is GraphQL, Reactive Approaches and distributed transactions with LRA.
This section will probably change in future editions of the book because at the time of publishing the Cloud Native Container Foundation revealed that some initiatives about observability will be integrated in the OpenTelemetry project and MicroProfile it's discussing their future approach.
As any review this is the most difficult section to write, but I think that a second edition should:
The last item is mostly a wish since I'm always in the need for better ways to integrate this common practices with buses like Kafka or Camel using MicroProfile. I know that some implementations -e.g. Helidon, Quarkus- already have extensions for Kafka or Camel, but the data consistency is an entire discussion about patterns, tools and best practices.
Today the Jakarta EE Ambassadors are announcing the start of the Jakarta EE Community Acceptance (JCAT) Testing initiative. The purpose of this initiative is to test Jakarta EE 9/9.1 implementations testing using your code and/or applications. Although Jakarta EE is extensively tested by the TCK, container specific tests, and QA, the purpose of JCAT is for developers to test the implementations.
Jakarta EE 9/9.1 did not introduce any new features. In Jakarta EE 9 the APIs changed from javax to jakarta. Jakarta EE 9.1 raised the supported floor to Java 11 for compatible implementations. So what are we testing?
Participating in this initiative is easy:
To join this initiative, please take a moment to fill-out the form:
To submit results or feedback on your experiences with Jakarta EE 9/9.1:
Jakarta EE 9 / 9.1 Feedback Form
Resources:
Start Date: July 28, 2021
End Date: December 31st, 2021

The Jakarta EE Developer Survey is in its fourth year and is the industry’s largest open source developer survey. It’s open until April 30, 2021. I am encouraging you to add your voice. Why should you do it? Because Jakarta EE Working Group needs your feedback. We need to know the challenges you facing and suggestions you have about how to make Jakarta EE better.
Last year’s edition surveyed developers to gain on-the-ground understanding and insights into how Jakarta solutions are being built, as well as identifying developers’ top choices for architectures, technologies, and tools. The 2021 Jakarta EE Developer Survey is your chance to influence the direction of the Jakarta EE Working Group’s approach to cloud native enterprise Java.
The results from the 2021 survey will give software vendors, service providers, enterprises, and individual developers in the Jakarta ecosystem updated information about Jakarta solutions and service development trends and what they mean for their strategies and businesses. Additionally, the survey results also help the Jakarta community at the Eclipse Foundation better understand the top industry focus areas and priorities for future project releases.
A full report from based on the survey results will be made available to all participants.
The survey takes less than 10 minutes to complete. We look forward to your input. Take the survey now!
Wildfly provides great out of the box load balancing support by Undertow and modcluster subsystems
Unfortunately, in case HTTP headers size is huge enough (close to 16K), which is so actual in JWT era - pity error happened:
ERROR [io.undertow.proxy] (default I/O-10) UT005028: Proxy request to /ee-jax-rs-examples/clusterdemo/serverinfo failed: java.io.IOException: java.nio.BufferOverflowException
at io.undertow.server.handlers.proxy.ProxyHandler$HTTPTrailerChannelListener.handleEvent(ProxyHandler.java:771)
at io.undertow.server.handlers.proxy.ProxyHandler$ProxyAction$1.completed(ProxyHandler.java:646)
at io.undertow.server.handlers.proxy.ProxyHandler$ProxyAction$1.completed(ProxyHandler.java:561)
at io.undertow.client.ajp.AjpClientExchange.invokeReadReadyCallback(AjpClientExchange.java:203)
at io.undertow.client.ajp.AjpClientConnection.initiateRequest(AjpClientConnection.java:288)
at io.undertow.client.ajp.AjpClientConnection.sendRequest(AjpClientConnection.java:242)
at io.undertow.server.handlers.proxy.ProxyHandler$ProxyAction.run(ProxyHandler.java:561)
at io.undertow.util.SameThreadExecutor.execute(SameThreadExecutor.java:35)
at io.undertow.server.HttpServerExchange.dispatch(HttpServerExchange.java:815)
...
Caused by: java.nio.BufferOverflowException
at java.nio.Buffer.nextPutIndex(Buffer.java:521)
at java.nio.DirectByteBuffer.put(DirectByteBuffer.java:297)
at io.undertow.protocols.ajp.AjpUtils.putString(AjpUtils.java:52)
at io.undertow.protocols.ajp.AjpClientRequestClientStreamSinkChannel.createFrameHeaderImpl(AjpClientRequestClientStreamSinkChannel.java:176)
at io.undertow.protocols.ajp.AjpClientRequestClientStreamSinkChannel.generateSendFrameHeader(AjpClientRequestClientStreamSinkChannel.java:290)
at io.undertow.protocols.ajp.AjpClientFramePriority.insertFrame(AjpClientFramePriority.java:39)
at io.undertow.protocols.ajp.AjpClientFramePriority.insertFrame(AjpClientFramePriority.java:32)
at io.undertow.server.protocol.framed.AbstractFramedChannel.flushSenders(AbstractFramedChannel.java:603)
at io.undertow.server.protocol.framed.AbstractFramedChannel.flush(AbstractFramedChannel.java:742)
at io.undertow.server.protocol.framed.AbstractFramedChannel.queueFrame(AbstractFramedChannel.java:735)
at io.undertow.server.protocol.framed.AbstractFramedStreamSinkChannel.queueFinalFrame(AbstractFramedStreamSinkChannel.java:267)
at io.undertow.server.protocol.framed.AbstractFramedStreamSinkChannel.shutdownWrites(AbstractFramedStreamSinkChannel.java:244)
at io.undertow.channels.DetachableStreamSinkChannel.shutdownWrites(DetachableStreamSinkChannel.java:79)
at io.undertow.server.handlers.proxy.ProxyHandler$HTTPTrailerChannelListener.handleEvent(ProxyHandler.java:754)
The same request directly to backend server works well. Tried to play with ajp-listener and mod-cluster filter "max-*" parameters, but have no luck.
Possible solution here is switch protocol from AJP to HTTP which can be bit less effective, but works well with big headers:
/profile=full-ha/subsystem=modcluster/proxy=default:write-attribute(name=listener, value=default)

The purpose of this article is to consolidate all difficulties and solutions that I've encountered while updating Java EE projects from Java 8 to Java 11 (and beyond). It's a known fact that Java 11 has a lot of new characteristics that are revolutionizing how Java is used to create applications, despite being problematic under certain conditions.
This article is focused on Java/Jakarta EE but it could be used as basis for other enterprise Java frameworks and libraries migrations.
Yes, absolutely. My team has been able to bump at least two mature enterprise applications with more than three years in development, being:


As everything in IT the answer is "It depends . . .". However there are a couple of good reasons to do it:
From my experience with many teams, because of this:

Currently, there are two big branches in JVMs release model:
The rationale behind this decision is that Java needed dynamism in providing new characteristics to the language, API and JVM, which I really agree.
Nevertheless, it is a know fact that most enterprise frameworks seek and use Java for stability. Consequently, most of these frameworks target Java 11 as "certified" Java Virtual Machine for deployments.

Errata: I fixed and simplified this section following an interesting discussion on reddit :)
Java 9 introduced changes in internal classes that weren't meant for usage outside JVM, preventing/breaking the functionality of popular libraries that made use of these internals -e.g. Hibernate, ASM, Hazelcast- to gain performance.
Hence to avoid it, internal APIs in JDK 9 are inaccessible at compile time (but accesible with --add-exports), remaining accessible if they were in JDK 8 but in a future release they will become inaccessible, in the long run this change will reduce the costs borne by the maintainers of the JDK itself and by the maintainers of libraries and applications that, knowingly or not, make use of these internal APIs.
Finally, during the introduction of JEP-260 internal APIs were classified as critical and non-critical, consequently critical internal APIs for which replacements are introduced in JDK 9 are deprecated in JDK 9 and will be either encapsulated or removed in a future release.
However, you are inside the danger zone if:
Any of these situations means that your application has a probability of not being compatible with JVMs above Java 8. At least not without updating your dependencies, which also could uncover breaking changes in library APIs creating mandatory refactors.

Also during Java 9 release, many Java EE and CORBA modules were marked as deprecated, being effectively removed at Java 11, specifically:
As JEP-320 states, many of these modules were included in Java 6 as a convenience to generate/support SOAP Web Services. But these modules eventually took off as independent projects already available at Maven Central. Therefore it is necessary to include these as dependencies if our project implements services with JAX-WS and/or depends on any library/utility that was included previously.

In the same way as libraries, Java IDEs had to catch-up with the introduction of Java 9 at least in three levels:
Overall, none of the Java IDEs guaranteed that plugins will work in JVMs above Java 8. Therefore you could possibly run your IDE over Java 11 but a legacy/deprecated plugin could prevent you to run your application.
You must notice that Java 9 launched three years ago, hence the situations previously described are mostly covered. However you should do the following verifications and actions to prevent failures in the process:

Mike Luikides from O'Reilly affirms that there are two types of programmers. In one hand we have the low level programmers that create tools as libraries or frameworks, and on the other hand we have developers that use these tools to create experience, products and services.
Java Enterprise is mostly on the second hand, the "productive world" resting in giant's shoulders. That's why you should check first if your runtime or framework already has a version compatible with Java 11, and also if you have the time/decision power to proceed with an update. If not, any other action from this point is useless.
The good news is that most of the popular servers in enterprise Java world are already compatible, like:
If you happen to depend on non compatible runtimes, this is where the road ends unless you support the maintainer to update it.

On a non-technical side, under support contract conditions you could be obligated to use an specific JVM version.
OpenJDK by itself is an open source project receiving contributions from many companies (being Oracle the most active contributor), but nothing prevents any other company to compile, pack and TCK other JVM distribution as demonstrated by Amazon Correto, Azul Zulu, Liberica JDK, etc.
In short, there is software that technically could run over any JVM distribution and version, but the support contract will ask you for a particular version. For instance:
Since the jump from Java 8 to Java 11 is mostly an experimentation process, it is a good idea to install multiple JVMs on the development computer, being SDKMan and jEnv the common options:

SDKMan is available for Unix-Like environments (Linux, Mac OS, Cygwin, BSD) and as the name suggests, acts as a Java tools package manager.
It helps to install and manage JVM ecosystem tools -e.g. Maven, Gradle, Leiningen- and also multiple JDK installations from different providers.

Also available for Unix-Like environments (Linux, Mac OS, Cygwin, BSD), jEnv is basically a script to manage and switch multiple JVM installations per system, user and shell.
If you happen to install JDKs from different sources -e.g Homebrew, Linux Repo, Oracle Technology Network- it is a good choice.
Finally, if you use Windows the common alternative is to automate the switch using .bat files however I would appreciate any other suggestion since I don't use Windows so often.
Please remember that any IDE ecosystem is composed by three levels:
After updating your IDE, you should also verify if all of the plugins that make part of your development cycle work fine under Java 11.

Probably the most common choice in Enterprise Java is Maven, and many IDEs use it under the hood or explicitly. Hence, you should update it.
Besides installation, please remember that Maven has a modular architecture and Maven modules version could be forced on any project definition. So, as rule of thumb you should also update these modules in your projects to the latest stable version.
To verify this quickly, you could use versions-maven-plugin:
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>versions-maven-plugin</artifactId>
<version>2.8.1</version>
</plugin>
Which includes a specific goal to verify Maven plugins versions:
mvn versions:display-plugin-updates

After that, you also need to configure Java source and target compatibility, generally this is achieved in two points.
As properties:
<properties>
...
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
</properties>
As configuration on Maven plugins, specially in maven-compiler-plugin:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<release>11</release>
</configuration>
</plugin>
Finally, some plugins need to "break" the barriers imposed by Java Modules and Java Platform Teams knows about it. Hence JVM has an argument called illegal-access to allow this, at least during Java 11.
This could be a good idea in plugins like surefire and failsafe which also invoke runtimes that depend on this flag (like Arquillian tests):
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.0</version>
<configuration>
<argLine>
--illegal-access=permit
</argLine>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
<version>2.22.0</version>
<configuration>
<argLine>
--illegal-access=permit
</argLine>
</configuration>
</plugin>
As mentioned before, you need to check for compatible versions on your Java dependencies. Sometimes these libraries could introduce breaking changes on each major version -e.g. Flyway- and you should consider a time to refactor this changes.
Again, if you use Maven versions-maven-plugin has a goal to verify dependencies version. The plugin will inform you about available updates.:
mvn versions:display-dependency-updates

In the particular case of Java EE, you already have an advantage. If you depend only on APIs -e.g. Java EE, MicroProfile- and not particular implementations, many of these issues are already solved for you.

Probably modern REST based services won't need this, however in projects with heavy usage of SOAP and XML marshalling is mandatory to include the Java EE modules removed on Java 11. Otherwise your project won't compile and run.
You must include as dependency:
At this point is also a good idea to evaluate if you could move to Jakarta EE, the evolution of Java EE under Eclipse Foundation.
Jakarta EE 8 is practically Java EE 8 with another name, but it retains package and features compatibility, most of application servers are in the process or already have Jakarta EE certified implementations:
We could swap the Java EE API:
<dependency>
<groupId>javax</groupId>
<artifactId>javaee-api</artifactId>
<version>8.0.1</version>
<scope>provided</scope>
</dependency>
For Jakarta EE API:
<dependency>
<groupId>jakarta.platform</groupId>
<artifactId>jakarta.jakartaee-api</artifactId>
<version>8.0.0</version>
<scope>provided</scope>
</dependency>
After that, please include any of these dependencies (if needed):
Java EE
<dependency>
<groupId>javax.activation</groupId>
<artifactId>javax.activation-api</artifactId>
<version>1.2.0</version>
</dependency>
Jakarta EE
<dependency>
<groupId>jakarta.activation</groupId>
<artifactId>jakarta.activation-api</artifactId>
<version>1.2.2</version>
</dependency>
Java EE
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.3.1</version>
</dependency>
Jakarta EE
<dependency>
<groupId>jakarta.xml.bind</groupId>
<artifactId>jakarta.xml.bind-api</artifactId>
<version>2.3.3</version>
</dependency>
Implementation
<dependency>
<groupId>org.glassfish.jaxb</groupId>
<artifactId>jaxb-runtime</artifactId>
<version>2.3.3</version>
</dependency>
Java EE
<dependency>
<groupId>javax.xml.ws</groupId>
<artifactId>jaxws-api</artifactId>
<version>2.3.1</version>
</dependency>
Jakarta EE
<dependency>
<groupId>jakarta.xml.ws</groupId>
<artifactId>jakarta.xml.ws-api</artifactId>
<version>2.3.3</version>
</dependency>
Implementation (runtime)
<dependency>
<groupId>com.sun.xml.ws</groupId>
<artifactId>jaxws-rt</artifactId>
<version>2.3.3</version>
</dependency>
Implementation (standalone)
<dependency>
<groupId>com.sun.xml.ws</groupId>
<artifactId>jaxws-ri</artifactId>
<version>2.3.2-1</version>
<type>pom</type>
</dependency>
Java EE
<dependency>
<groupId>javax.annotation</groupId>
<artifactId>javax.annotation-api</artifactId>
<version>1.3.2</version>
</dependency>
Jakarta EE
<dependency>
<groupId>jakarta.annotation</groupId>
<artifactId>jakarta.annotation-api</artifactId>
<version>1.3.5</version>
</dependency>
Java EE
<dependency>
<groupId>javax.transaction</groupId>
<artifactId>javax.transaction-api</artifactId>
<version>1.3</version>
</dependency>
Jakarta EE
<dependency>
<groupId>jakarta.transaction</groupId>
<artifactId>jakarta.transaction-api</artifactId>
<version>1.3.3</version>
</dependency>
In the particular case of CORBA, I'm aware of its adoption. There is an independent project in eclipse to support CORBA, based on Glassfish CORBA, but this should be investigated further.
If everything compiles, tests and executes. You did a successful migration.
Some deployments/environments run multiple application servers over the same Linux installation. If this is your case it is a good idea to install multiple JVMs to allow stepped migrations instead of big bang.
For instance, RHEL based distributions like CentOS, Oracle Linux or Fedora include various JVM versions:

Most importantly, If you install JVMs outside directly from RPMs(like Oracle HotSpot), Java alternatives will give you support:

However on modern deployments probably would be better to use Docker, specially on Windows which also needs .bat script to automate this task. Most of the JVM distributions are also available on Docker Hub:

About one month ago I had the pleasure to announce the release of the second edition of my book, now called “Jakarta EE Cookbook”. By that time I had recorded a video about and you can watch it here:
And then came a crazy month and just now I had the opportunity to write a few lines about it! 
So, straight to the point, what you should know about the book (in case you have any interest in it).
Java developers working on enterprise applications and that would like to get the best from the Jakarta EE platform.
I’m sure this is one of the most complete books of this field, and I’m saying it based on the covered topics:
The book has the word “cookbook” on its name for a reason: it follows a 100% practical approach, with almost all working code available in the book (we only omitted the imports for the sake of the space).
And talking about the source code being available, it is really available on my Github: https://github.com/eldermoraes/javaee8-cookbook
PRs and Stars are welcomed!
The book has an appendix that would be worthy of another book! I tell the readers how sharing knowledge has changed my career for good and how you can apply what I’ve learned in your own career.
In the first 24 hours of its release, this book simply reached the 1st place at Amazon among other Java releases! Wow!

Of course, I’m more than happy and honored for such a warm welcome given to my baby…
If you are interested in it, we are in the very last days of the special price in celebration of its release. You can take a look here http://book.eldermoraes.com
Leave your comments if you need any clarification about it. See you!
The JDK Flight Recorder (JFR) is an invaluable tool for gaining deep insights into the performance characteristics of Java applications. Open-sourced in JDK 11, JFR provides a low-overhead framework for collecting events from Java applications, the JVM and the operating system.
In this blog post we’re going to explore how custom, application-specific JFR events can be used to monitor a REST API, allowing to track request counts, identify long-running requests and more. We’ll also discuss how the JFR Event Streaming API new in Java 14 can be used to export live events, making them available for monitoring and alerting via tools such as Prometheus and Grafana.